 vin1992
commented
7 years ago
vin1992
commented
7 years ago 受教了,感觉自己瞬间落后了几个纪元
Open livoras opened 9 years ago
vin1992
commented
7 years ago 受教了,感觉自己瞬间落后了几个纪元
 livoras
commented
7 years ago
livoras
commented
7 years ago @vin1992 这篇文章是差不多两年前写的,本文所讲的内容已经过时了。
作者:戴嘉华
转载请注明出处,保留原文链接和作者信息
1. 前端自动化工作流简介
每种项目都有自己特定的开发流程、工作流程。从需求分析、设计、编码、测试、发布,一个整个开发流程中,会根据不同的情况形成自己独特的步骤和流程。一个工作流的过程不是一开始就固定的,而是随着项目的深入而不断地改进,期间甚至会形成一些工具。例如当年大神们在Linux写C语言,觉得每次编译好多文件好麻烦,就发明了makefile。不同代码的管理好麻烦,然后就发明了git、SVN等等。
一个工作流程的好坏会影响你开发的效率、开发的流程程度,然后间接影响心情,打击编码积极性。所以我认为开发一个项目的时候,编码前把工作流程梳理清楚确定下来是一个非常重要的步骤。并且这个流程要在真实环境中不停的改进。
对于要负责页面结构和内容、外观、逻辑的前端来说,一个好的工作流至关重要。而且这里中没有银弹。要根据具体项目所使用的框架、应用场景来进行调整独特的工作流。
我会介绍一个我经常使用的前端工作流,这个工作流只是一个原始的流程,一般来说,我会根据不同项目的不同来在这个基础上进行调整,形成每个项目独特的流程。所以这里的重点是领会构建工作流的思路,然后学会举一反三。
一个前端自动化开发流程中,我觉得至少需要做到以下几点:
能用机器的地方就不要自己动手,除了上述必备的几点,有时候要根据特定的情况编写一些Python、Nodejs、Shell脚本来避免重复的操作。好好呵护你的F5和稀疏的脑神经,男人要对自己好一点。
2. 储备知识
在正式介绍之前会先做一些储备知识的介绍,也会略过一些你可能不懂的知识。懂的话可以跳过,遇到不懂的可以自己Google,不要百度。
2.1 工程目录
我的工程目录一般是这个样的:
所有子目录名称很多都其实源于古老的C语言工程。
assets:一般存放的是图片、音频、视频、字体等代码无关的静态资源,我一般只有图片,有时候也会新建一个fonts文件夹什么的。
bin:binary的缩写,这个名字来历于我们古老的C语言工程,因为一般C语言要编译成可执行的二进制文件什么的,后来基本成为了一种默认的标注。所以前端编译好的文件也会存放在bin/目录下。
dist:distribution的缩写,编译好的bin中的文件并不会直接用于发布,而是会经过一系列的优化操作,例如打包压缩等。最终能够部署到发布环境的文件都会存放在dist里面,所以dist里面是能够直接用到生产环境的代码。
lib:library的缩写,存放的是第三方库文件。例如你喜欢的jquery、fastclick什么的。但是接下来你会看到,在我们的模块化方式中,这个文件夹一般是比较鸡肋的存在。
src:source的缩写,所有需要开发的源代码的存放地,我们一般操作地最多的就是这个文件夹。简单地分为coffee、less两个文件夹,存的是逻辑代码和样式(我一般用CoffeeScript和LessCss,当然你也可以改成你喜欢的语言,JS,TS,LS,SASS,思路是一样的)。你看到两个文件夹下分别有main.coffe、main.less,这其实是逻辑代码和样式代码的主要入口文件,会把其他模块和样式引进来,通过某种机制合成一个文件。接下来会详细解释。
另外,这个目录的组织方式会根据实际情况多变。有时候你会需要html模板,可能会多一个tpl/目录。也许你的目录不是这种基于文件类型的层次组织,而是基于页面部件的组织,就可能出现components/目录,然后下面有很多个页面部件的目录,每个子目录有自己的coffee、less、html。(这种形式也变得逐渐流行。因为基于文件类型目录,当工程复杂起来的时候,就会变得异常难以维护,基于部件就会相当方便)。
test:使用测试驱动(TDD)开发进行编程,这里存放的都是测试样例。
index.html:页面文件
接下来几个文件都不解释,不了解的可以先预习NodeJS、Git、Grunt这几个东西。
2.2 模块化
说起前端模块化又是一个可以长篇大论话题。前端模块化的方式有很多种,年轻人最喜欢用的就是RequireJS、SeaJS什么的,看到这些模块化工具的时候感觉就像自己的第一双滑板鞋那样那么兴奋。其实这种AMD、CMD都需要引进一个库文件来做模块化工具,而且配置复杂,各种异步加载问题多多。后来我发现其实最clean、直接、方便、强大模块化方式当属substack大神的真.Browserify。
它可以基于NodeJS平台实现模块化的工具,你可以像组织NodeJS代码那样组织自己的前端工程,所有的模块都可以像NodeJS那样直接require进来。提供一个入口文件(如上的main.coffee)给Browserify,它会把这个入口文件的所有依赖模块都打包成一个文件。最终的文件不依赖于Browserify,最终的文件就是你的逻辑代码的组合。
而且Browserify和NodeJS的模块兼容性很好,一些NodeJS自带的模块例如util、path都可以用到前端中。你用npm安装的库,也可以通过Browserify用到前端中!例如我想用jQuery,我只需要:
npm install jquery --save。然后在main.coffee中:相当贴心。
(Browserify具体用法查看官网文档)
2.3 流程自动化工具
其实自动化方式可以有很多种,你可以:
前两种方式更适合NodeJS开发服务端的应用场景,前端一般更适合用后两种。
目前使用的是Grunt,选择它是因为它社区大、插件多、成熟。但是我更看好Gulp基于流(Stream)的机理,这种继承于Unix思想的无与伦比的实现方式着实可以让它在性能上和Grunt拉开差距。Grunt基于文件实现方式是在是:太!慢!了!
(Grunt具体用法可以见官网文档)
2.4 测试
测试又是一个庞大的话题。在国外,前端TDD、BDD开发已经相当成熟,各种酷炫的工具Jasmine、Mocha、Tape等等,可能是我比较孤陋寡闻,貌似国内很少见到这些工具的使用。
其实前端是很难做到完全测试驱动开发的,它本身涉及到许多主观判断因素,例如动画是不是按照预想的那样移动等等。但是逻辑代码和前后端接口逻辑是可以测试的。所以引进测试驱动开发的一个非常大的好处就是:只要接口确定了,前后端可以分离开发,前端不用再“等后端API实现”了。
在我们的工作流中,使用MochaJS作为测试套件,ChaiJS作为断言库,Sinon做为数据mocking和函数spy。具体用法可以看各自的官网。
(对前端测试驱动开发不了解的同学可以Google相关资料或查阅相关书籍)
3. 自动化工作流
3.1 模板
这个工作流的模版已经存放到了github上,大家可以clone下来进行本地测试一下:https://github.com/livoras/feb.git
运行步骤:
安装browswerify,coffeescript,和grunt:
npm install browswerify coffee-script grunt-cli -g
把仓库fork到本地,进入工程目录,安装依赖:
npm install
运气好的话你可以看到这样的界面:
然后,你会发现工程目录下多了一个bin文件夹,那就是我们刚编译好的文件存放在bin中。
然后打开浏览器,进入http://localhost:3000 ,可以看到: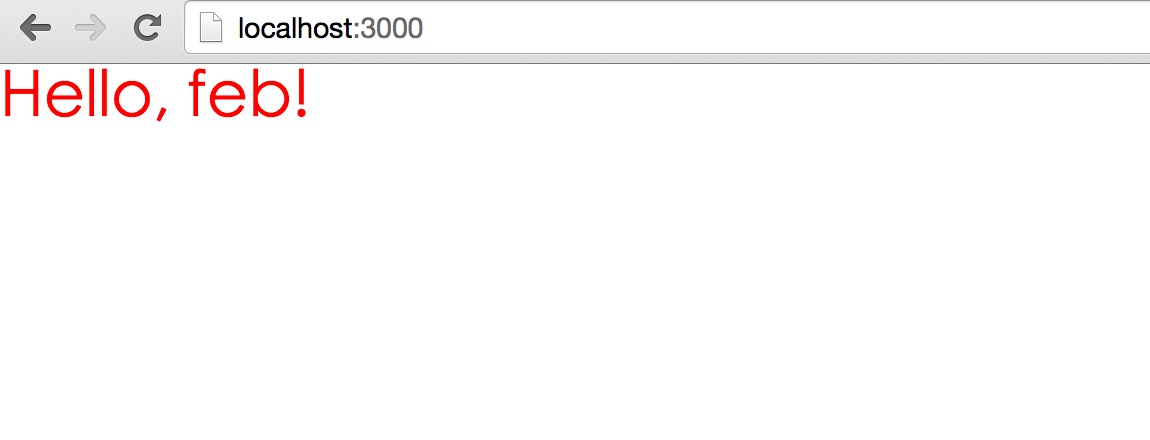
现在我们修改src/less/main.less文件,把body改成黑色看看:
然后回到浏览器看看: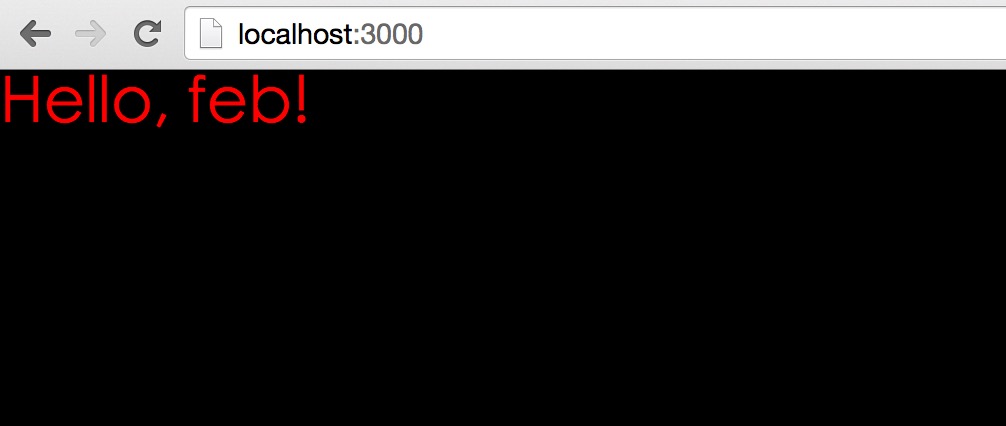
说变就变,非常哦妹子(amazing)是不是?
工作流分两个简单的步骤:
现在来介绍一下。
3.2 开发时
我们来看看gruntfile的100~108行:
其实grunt干了这么几件事:
import)。所以我们的样式也是萌萌哒模块化了。有了这么一个流程,你就可以很轻松地写前端的逻辑和样式,并且都是以模块化的方式。
3.3 发布时
好了,代码都写完了。我需要把我的代码部署到服务器上。很简单,只需要命令行中执行:
你就会发现工程目录下多了一个dist文件夹,进入里面,可以看到:
直接打开index.html:
居然可以直接打开,也是非常哦妹子是不是?
我们看看grunt的build任务:
grunt build干了这么几件事情:
你可以看到dist目录下的文件js和css文件都是经过压缩的,现在dist中的文件夹已经ready了,你随时都可以直接放到服务器上了。
4. 最后
上面其实是一个非常简陋的流程,在实际要做的流程化要比这个复杂多,例如要考虑组建目录自动化构建,版本管理自动化,部署自动化,图片合并优化等等。主要有这个意识:* 不要做任何重复的工作,能自动化到地方都可以想法设法做到自动化 *。
上面也跳过了很多基础知识,这些是你需要知道的:
我甚至直接跳过了构建整个流程的过程,也跳过了测试如何编写。其实其中很多细节都可以拓展来讲,测试,模块化等,接下来博客也许会往这个方向去写。
(全文完)