llvmbot
commented
2 years ago
llvmbot
commented
2 years ago @llvm/issue-subscribers-backend-aarch64
Open EgorBo opened 2 years ago
llvmbot
commented
2 years ago @llvm/issue-subscribers-backend-aarch64
 EgorBo
commented
2 years ago
EgorBo
commented
2 years ago After taking a quick glance the issue, it seems, in enableMemCmpExpansion that unconditionally returns Options.LoadSizes = {8, 4, 2, 1};
I assume for, at least, -O3 and IsZeroCmp == true it makes sense to consider using 16b. e.g. memset uses neon just fine
TLDR: https://godbolt.org/z/be34K3ba8
While on x64
Expand memcmp() to load/stores (expandmemcmp)transformation pass does a good job:which is lowered down to (AVX2):
on ARM64 it lowers
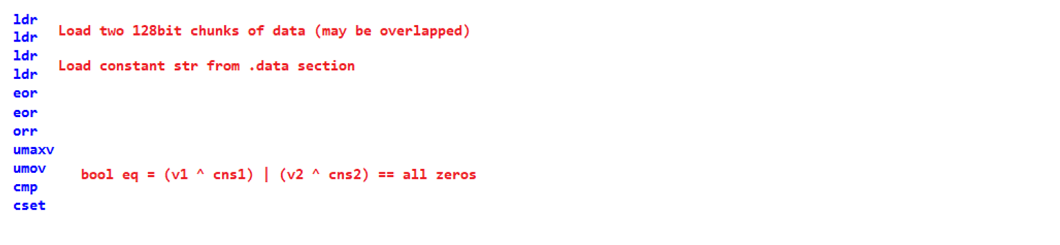
bcmp == 0to a very long sequence of SWAR/Scalar ops:which is lowered down to:
Hard to imagine an overhead from a case where sequences aren't the same - ARM64 codegen doesn't use branches so it has to accumulate a final 64bit value to figure out it was not the same.
Expected: Neon or SVE2 impl, e.g. something like this for 32byte length: