 lmcinnes
commented
6 years ago
lmcinnes
commented
6 years ago There is no interpretability to the axes unfortunately -- any rotation would be an equally valid/correct embedding.
As for interpreting distances -- I think the kind of inferences you are drawing are valid, but I would be wary of trying to draw very distance specific information beyond general big picture type statements such as you made.
On Wed, Jul 25, 2018 at 7:02 AM Daniel Gomez notifications@github.com wrote:
Hi,
I have a couple of questions regarding the interpretability of the results obtained with UMAP. I apologize if the questions are too trivial and should be posted elsewhere.
Third, UMAP often performs better at preserving aspects of global structure of the data than t-SNE. This means that it can often provide a better "big picture" view of your data as well as preserving local neighbor relations.
I was wondering whether euclidian distances in the embedding are interpretable. Taking the MNIST example:
[image: MNIST example] https://raw.githubusercontent.com/lmcinnes/umap/master/images/umap_example_mnist1.png
Does it make sense to say that the digit "3" is as distant to "0" as it is from "1"? Or that because the area of the cluster of "1"s is larger than the area of the cluster of "8"s, that there is more variability in "1"s than there is in "8"s?
Is there any way of interpreting of the axes mean?
Thank you for your awesome project!
— You are receiving this because you are subscribed to this thread. Reply to this email directly, view it on GitHub https://github.com/lmcinnes/umap/issues/92, or mute the thread https://github.com/notifications/unsubscribe-auth/ALaKBZVZg4A5JsP0hfmIO-mhDqPUqv9dks5uKFBXgaJpZM4Vf4UP .
 cjnolet
cjnolet birdsarah
birdsarah

 aprive
aprive ConstantinWdP
ConstantinWdP sleighsoft
sleighsoft PedroRaposo
PedroRaposo

 jc-healy
jc-healy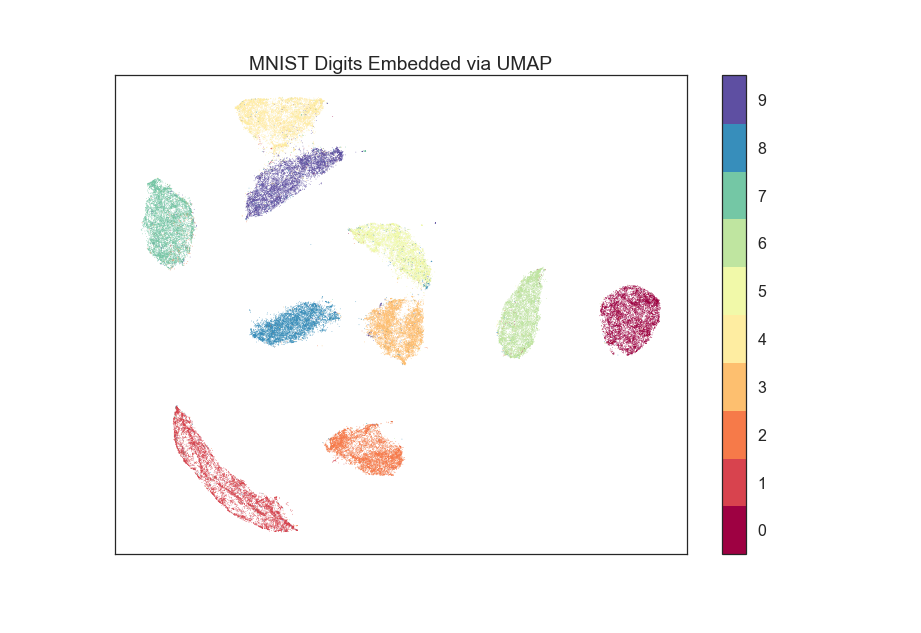{kind=link}
Hi,
I have a couple of questions regarding the interpretability of the results obtained with UMAP. I apologize if the questions are too trivial and should be posted elsewhere.
I was wondering whether euclidian distances in the embedding are interpretable. Taking the MNIST example:
Does it make sense to say that the digit "3" is as distant to "0" as it is from "1"? Or that because the area of the cluster of "1"s is larger than the area of the cluster of "8"s, that there is more variability in "1"s than there is in "8"s?
Is there any way of interpreting of the axes mean, i.e., if we were to take a random point in the 2D space, could we apply an inverse transformation to figure out what the N-D object would've looked like?
Thank you for your awesome project!