Open loadlj opened 4 years ago
要想了解熟悉分布式,Raft协议是绕不开的。相较于Paxos,raft的优点就是上手比较方便,容易理解。这篇文章主要是介绍下raft一些基本概念。
Raft is a protocol for implementing distributed consensus.
Raft是一个分布式的共识性协议,节点的状态分为Leader,Follower,以及Candidate三种状态。在集群中,节点的个数一般为大于3的基数,这是根据抽屉原理来的,每次选举都必须获得超过半数以上的同意。
Raft会把运行时分为不同的term,一般来讲,其实就是根据Leader的任期来进行划分的,每个Term里面最多只包含一个Leader。
Term在Raft里面是用来替代逻辑时钟的,每个节点都会存储当前的Term ID,并且单调递增,通过RPC进行信息交换,Node根据不同的Term ID来进行当前的逻辑判断。
所有Node初始化的时候状态都是follower,如果一段时间后节点没有收到任何消息,就会认为当前没有Leader(election timeout),这个时候会重新开始选举一个新的leader。 开始之前,节点先把自己变为candidate状态,然后给其他节点发起投票请求,会出现三种情况:
leader选举出来之后就需要开始为客户端提供服务了,所有的请求都需要经过leader的处理,leader会把当前的请求转发给全部的follower。如果超过半数响应了本次请求,则leader就会响应户端 从上面的图片可以看到Log的结构,本身raft的思想是基于WAL来实现的,先提交,然后再commit, 每次的日志都是在最尾端进行追加的。 如图所示,leader的日志和follower的日志是会出现不一致的状态的。Raft中是强制follower去同步leader的日志,同步的逻辑是找到最近一次两者达成一致的地方,然后从那个点删除之后的日志,leader将自身的日志再发送给follower。
前面的选举中可以看到,任何follower都有可能成为leader。Raft增加了一些限制来确保选出的leader包含之前大部分的log。
选举限制: Raft在投票的时候需要确保candidate上的log和大多数节点中都一样新才能变成leader,定义谁新的方法就是通过比较两份日志中最后一条日志条目的索引值和任期号。
提交约束: 只有leader才可以commit当前term的日志。考虑下面的corner case:
在时刻(a), s1是leader,在term2提交的日志只赋值到了s1 s2两个节点就crash了。在时刻(b), s5成为了term 3的leader,日志只赋值到了s5,然后crash。然后在(c)时刻,s1又成为了term 4的leader,开始赋值日志,于是把term2的日志复制到了s3,此刻,可以看出term2对应的日志已经被复制到了majority,因此是committed,可以被状态机应用。不幸的是,接下来(d)时刻,s1又crash了,s5重新当选,然后将term3的日志复制到所有节点,这就出现了一种奇怪的现象:被复制到大多数节点(或者说可能已经应用)的日志被回滚。
Raft在选举leader成功后,不会直接提交前任leader的日志,是通过发送当前的日志进而提交上一次的日志。两段提交在这里就很好的避免了上面的问题发生,如果发生上面的问题,第二段commit会直接rollback。
Raft 原理
Background
要想了解熟悉分布式,Raft协议是绕不开的。相较于Paxos,raft的优点就是上手比较方便,容易理解。这篇文章主要是介绍下raft一些基本概念。
什么是Raft
基础
Raft是一个分布式的共识性协议,节点的状态分为Leader,Follower,以及Candidate三种状态。在集群中,节点的个数一般为大于3的基数,这是根据抽屉原理来的,每次选举都必须获得超过半数以上的同意。
Raft会把运行时分为不同的term,一般来讲,其实就是根据Leader的任期来进行划分的,每个Term里面最多只包含一个Leader。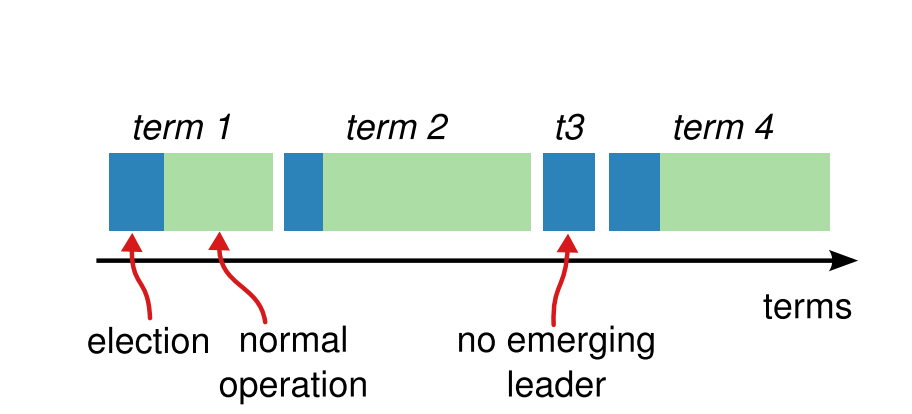
Term在Raft里面是用来替代逻辑时钟的,每个节点都会存储当前的Term ID,并且单调递增,通过RPC进行信息交换,Node根据不同的Term ID来进行当前的逻辑判断。
Leader选举
所有Node初始化的时候状态都是follower,如果一段时间后节点没有收到任何消息,就会认为当前没有Leader(election timeout),这个时候会重新开始选举一个新的leader。 开始之前,节点先把自己变为candidate状态,然后给其他节点发起投票请求,会出现三种情况:
日志复制
leader选举出来之后就需要开始为客户端提供服务了,所有的请求都需要经过leader的处理,leader会把当前的请求转发给全部的follower。如果超过半数响应了本次请求,则leader就会响应户端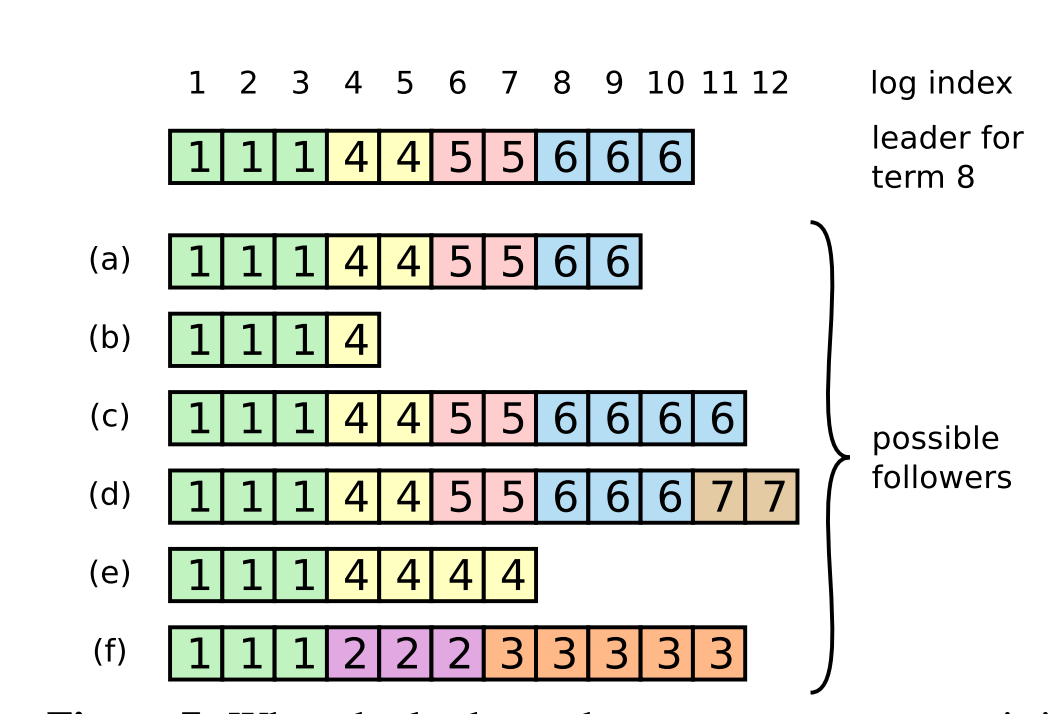 从上面的图片可以看到Log的结构,本身raft的思想是基于WAL来实现的,先提交,然后再commit, 每次的日志都是在最尾端进行追加的。
如图所示,leader的日志和follower的日志是会出现不一致的状态的。Raft中是强制follower去同步leader的日志,同步的逻辑是找到最近一次两者达成一致的地方,然后从那个点删除之后的日志,leader将自身的日志再发送给follower。
从上面的图片可以看到Log的结构,本身raft的思想是基于WAL来实现的,先提交,然后再commit, 每次的日志都是在最尾端进行追加的。
如图所示,leader的日志和follower的日志是会出现不一致的状态的。Raft中是强制follower去同步leader的日志,同步的逻辑是找到最近一次两者达成一致的地方,然后从那个点删除之后的日志,leader将自身的日志再发送给follower。
安全性
前面的选举中可以看到,任何follower都有可能成为leader。Raft增加了一些限制来确保选出的leader包含之前大部分的log。
选举限制: Raft在投票的时候需要确保candidate上的log和大多数节点中都一样新才能变成leader,定义谁新的方法就是通过比较两份日志中最后一条日志条目的索引值和任期号。
提交约束: 只有leader才可以commit当前term的日志。考虑下面的corner case: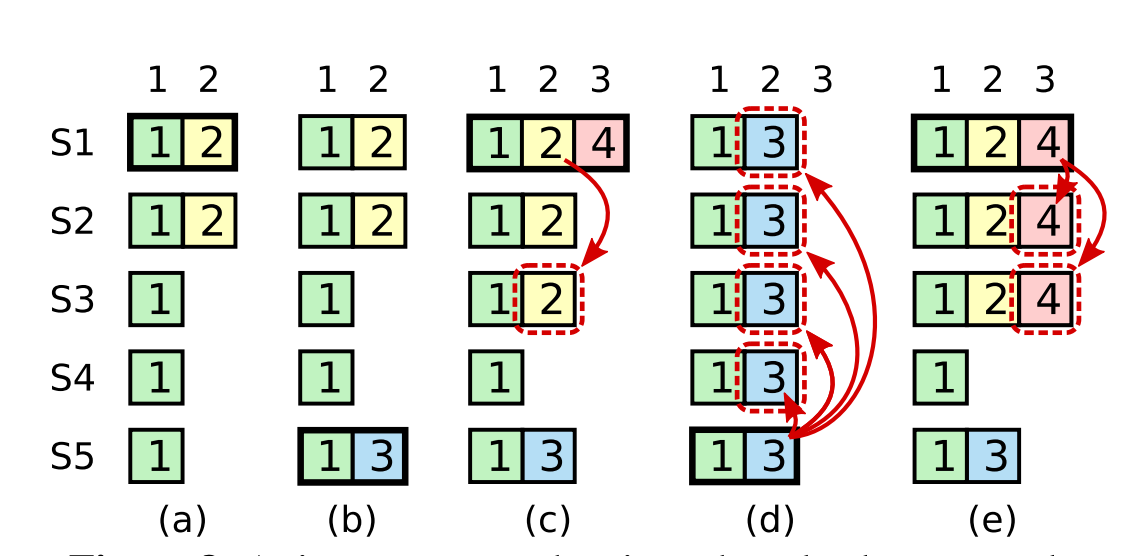
Raft在选举leader成功后,不会直接提交前任leader的日志,是通过发送当前的日志进而提交上一次的日志。两段提交在这里就很好的避免了上面的问题发生,如果发生上面的问题,第二段commit会直接rollback。
reference