Open loadlj opened 3 years ago
不同类型的地址类型:
内存控制单元(MMU)通过一种称为分段单元(segmentation unit)的硬件电路把一个 逻辑地址转换成线性地址;接着,第二个称为分页单元(paging unit)的硬件电路把线性地址转换成一个物理地址
从80286模型开始,Intel 微处理器以两种不同的方式执行地址转换,这两种方式分别称为实模式(real mode)和保护模式(protecied mode)。实模式存在的主要原因是要维持处理器与早期模型兼容,并让操 作系统自举。
整个小节看下来还是比较疑惑的,所以网上翻了下分段为什会出现:
1976年开始设计,1978年中旬Intel 发布了8086。标志了x86王朝的开始。它是一款16位的微处理器,却被设计成可以访问1MB 的内存(即20位的地址空间)。问题就产生了,16位的 ALU怎么去取20位的地址呢?因此,段的概念 在8086身上被引入了。
段的引入是解决“ 地址总线的宽度一般要大于寄存器的宽度 ”这个问题。
8086的分段寻址,是指一个物理地址由段地址(segment selector)与偏移量(offset)两部分组成,长度各是16比特。其中段地址左移4位(即乘以16)与偏移量相加即为物理地址。例如,06EFh:1234h,表示段地址为06EFh,偏移量为1234h,物理地址为06EF0h + 1234h = 08124h。在计算物理地址时如果发生上溢出,8086处理器舍弃进位。例如,FFFFh:0010h所对应的物理地址为00000h. 这种分段寻址,即 段地址+偏移量 的做法,在以80286开始之后会被称为 实模式。
分段机制是IA32架构CPU的特色,并不是操作系统寻址方式的必然选择。Linux为了跨平台,巧妙的绕开段机制,主要使用分页机制来寻址。
详细的文章可以参考一下这篇 https://m.xp.cn/b.php/77856.html
分页单元(pagingunit)把线性地址转换成物理地址。其中的一个关键任务是把所请求的访问类型与线性地址的访问权限相比较,如果这次内存访问是无效的,就产生一个缺页异常。 页、页框、页表的概念:
页: 为了效率起见,线性地址被分成以固定长度为单位的组,称为页(page)。 页内部连续的线性地址被映射到连续的物理地址中。
页框: 分页单元把所有的RAM分成固定长度的页框(page frame) (有时叫做物理页)。每个页框包含一个页(page), 也就是说一个页框的长度与一个页的长度一致。页框是主存的一部分,因此也是一个存储区域。区分一页和一个页框是很重要的,前者只是一个数据块,可以存放在任何页框或磁盘中。
页表: 把线性地址映射到物理地址的数据结构称为页表(page table)。页表存放在主存中,并在启用分页单元之前必须由内核对页表进行适当的初始化。
从80386起,Intel处理器的分页单元处理4KB的页。(如果没有内存分页,那么就需要记录物理内存每字节到虚拟内存每字节的对应关系,在内存里面是放不下的。)
线性地址的转换分两步完成,每一步都基于一种转换表,第一种转换表称为页目录表(page directory), 第二种转换表称为页表(page table)。这也是我们常说的二级页表。
如果我们使用一级页表,总共就需要4GB/4KB个表项,就是2的20次方。使用上面的二级页表的话,整体的逻辑就跟电话簿类似,分成三本电话簿, 一本记录目录对应关系,最多2的10次方个项,一本记录页表对应关系,也是2的10次方个项,最后的offset是2的12次方。可以很大程度减少页表项占用的内存。
4GB/4KB
(图片来源 https://www.cnblogs.com/vamei/p/9329278.html)
从Pentium模型开始,80x86 微处理器引入了扩展分页(extended paging),它允许页框大小为4MB而不是4KB(见图2-8)。扩展分页用于把大段连续的线性地址转换成相应的物理地址,在这些情况下,内核可以不用中间页表进行地址转换,从而节省内存并保 留TLB项。
32位微处理器普遍采用两级分页。然而两级分页并不适用于采用64位系统的计算机。
首先假设一个大小为4KB的标准页。因为1KB覆盖210个地址的范围,4KB覆盖212个地址,所以offset字段是12位。这样线性地址就剩下52位分配给Table和Directory字段。如果我们现在决定仅仅使用64位中的48位来寻址(这个限制仍然使我们自在地拥 有256TB的寻址空间! ), 剩下的48-12 = 36位将被分配给Table和Directory字段。如果我们现在决定为两个字段各预留18位, 那么每个进程的页目录和页表都含有218个项,即超过256000个项。
所以在64位的操作系统一般采用的是3级及以上的分页技术。
SRAM就是我们理解的CPU Cache(L1/L2/L3)
Cache Line: 80x86体系结构中引入了一个叫行(line)的新单位。行由几十个连续的字节组成,它们以脉冲突发模式(burstmode)在慢速DRAM和快速的用来实现高速缓存的片上静态RAM (SRAM)之间传送,用来实现高速缓存。
读写策略:
TLB(Translation Lookaside Buffer): 当一个线性地址被第一次使用时,通过慢速访问RAM中的页表计算出相应的物理地址。同时,物理 地址被存放在一个TLB表项(TLBentry)中,以便以后对同一个线性地址的引用可以快速地得到转换。
Linux采用了一种同时适用于32位和64位系统的普通分页模型。正像前面“64位系统 中的分页”一节所解释的那样,两级页表对32位系统来说已经足够了,但64位系统需 要更多数量的分页级别。
4种页表分别为:
对于没有启用物理地址扩展的32位系统,两级页表已经足够了。Linux通过使“页上级目录”位和“页中间目录”位全为0,从根本上取消了页上级目录和页中间目录字段。
每一个进程有它自己的页全局目录和自己的页表集。当发生进程切换时(参见第三章“进程切换"一节),Linux把cr3控制寄存器的内容保存在前一个 执行进程的描述符中,然后把下一个要执行进程的描述符的值装入cr3寄存器中。因此,当新进程重新开始在CPU上执行时,分页单元指向一组正确的页表。
在初始化阶段,内核必须建立一个物理地址映射来指定哪些物理地址范围对内核可用而哪些不可用(或者因为它们映射硬件设备I/O的共享内存,或者因为相应的页框含有BIOS数据)。
进程的线性地址空间分成两部分:
当进程运行在用户态时,它产生的线性地址小于0xc0000000;当进程运行在内核态时,它执行内核代码,所产生的地址大于等于0xc0000000。但是,在某些情况下,内核为了检索或存放数据必须访问用户态线性地址空间。
TLB 刷新: 一般来说,任何进程切换都会暗示着更换活动页表集。相对于过期页表。本地TLB表项必须被刷新:这个过程在内核把新的页全局目录的地址写入cr3控制寄在器时会自动完成。不过内核在下列情况下将避免TLB被刷新:
为了避免多处理器系统上无用的TLB刷新,内核使用一种叫做懒惰TLB (lazy TLB)模式的技术。其基本思想是,如果几个CPU正在使用相同的页表,而且必须对这些CPU上的一个TLB表项刷新,那么,在某些情况下,正在运行内核线程的那些CPU上的刷新就可以延迟。
《深入理解linux内核》笔记-内存寻址
地址类型
不同类型的地址类型:
内存控制单元(MMU)通过一种称为分段单元(segmentation unit)的硬件电路把一个 逻辑地址转换成线性地址;接着,第二个称为分页单元(paging unit)的硬件电路把线性地址转换成一个物理地址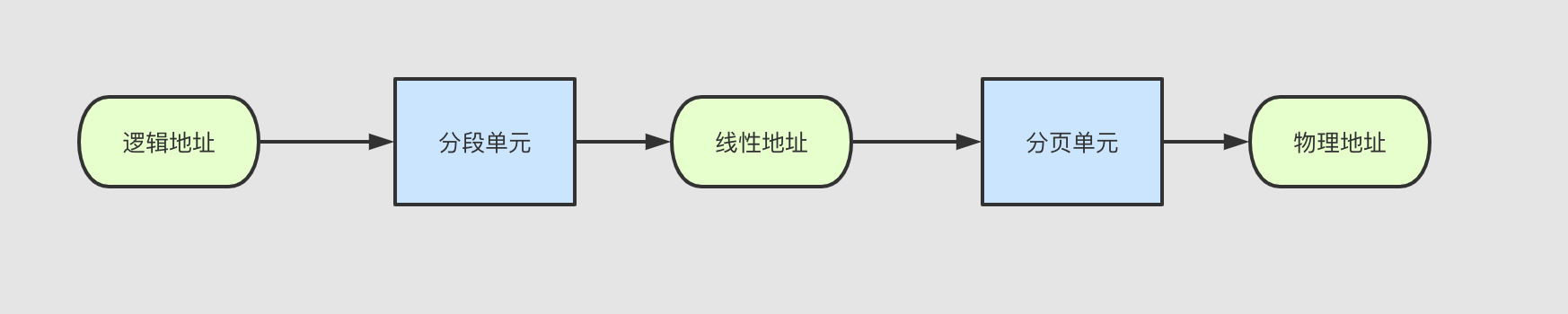
分段
从80286模型开始,Intel 微处理器以两种不同的方式执行地址转换,这两种方式分别称为实模式(real mode)和保护模式(protecied mode)。实模式存在的主要原因是要维持处理器与早期模型兼容,并让操 作系统自举。
整个小节看下来还是比较疑惑的,所以网上翻了下分段为什会出现:
1976年开始设计,1978年中旬Intel 发布了8086。标志了x86王朝的开始。它是一款16位的微处理器,却被设计成可以访问1MB 的内存(即20位的地址空间)。问题就产生了,16位的 ALU怎么去取20位的地址呢?因此,段的概念 在8086身上被引入了。
段的引入是解决“ 地址总线的宽度一般要大于寄存器的宽度 ”这个问题。
分段机制是IA32架构CPU的特色,并不是操作系统寻址方式的必然选择。Linux为了跨平台,巧妙的绕开段机制,主要使用分页机制来寻址。
详细的文章可以参考一下这篇 https://m.xp.cn/b.php/77856.html
硬件分页
分页单元(pagingunit)把线性地址转换成物理地址。其中的一个关键任务是把所请求的访问类型与线性地址的访问权限相比较,如果这次内存访问是无效的,就产生一个缺页异常。 页、页框、页表的概念:
页: 为了效率起见,线性地址被分成以固定长度为单位的组,称为页(page)。 页内部连续的线性地址被映射到连续的物理地址中。
页框: 分页单元把所有的RAM分成固定长度的页框(page frame) (有时叫做物理页)。每个页框包含一个页(page), 也就是说一个页框的长度与一个页的长度一致。页框是主存的一部分,因此也是一个存储区域。区分一页和一个页框是很重要的,前者只是一个数据块,可以存放在任何页框或磁盘中。
页表: 把线性地址映射到物理地址的数据结构称为页表(page table)。页表存放在主存中,并在启用分页单元之前必须由内核对页表进行适当的初始化。
从80386起,Intel处理器的分页单元处理4KB的页。(如果没有内存分页,那么就需要记录物理内存每字节到虚拟内存每字节的对应关系,在内存里面是放不下的。)
线性地址的转换分两步完成,每一步都基于一种转换表,第一种转换表称为页目录表(page directory), 第二种转换表称为页表(page table)。这也是我们常说的二级页表。
如果我们使用一级页表,总共就需要
4GB/4KB个表项,就是2的20次方。使用上面的二级页表的话,整体的逻辑就跟电话簿类似,分成三本电话簿, 一本记录目录对应关系,最多2的10次方个项,一本记录页表对应关系,也是2的10次方个项,最后的offset是2的12次方。可以很大程度减少页表项占用的内存。(图片来源 https://www.cnblogs.com/vamei/p/9329278.html)
从Pentium模型开始,80x86 微处理器引入了扩展分页(extended paging),它允许页框大小为4MB而不是4KB(见图2-8)。扩展分页用于把大段连续的线性地址转换成相应的物理地址,在这些情况下,内核可以不用中间页表进行地址转换,从而节省内存并保 留TLB项。
64位系统的分页
32位微处理器普遍采用两级分页。然而两级分页并不适用于采用64位系统的计算机。
首先假设一个大小为4KB的标准页。因为1KB覆盖210个地址的范围,4KB覆盖212个地址,所以offset字段是12位。这样线性地址就剩下52位分配给Table和Directory字段。如果我们现在决定仅仅使用64位中的48位来寻址(这个限制仍然使我们自在地拥 有256TB的寻址空间! ), 剩下的48-12 = 36位将被分配给Table和Directory字段。如果我们现在决定为两个字段各预留18位, 那么每个进程的页目录和页表都含有218个项,即超过256000个项。
所以在64位的操作系统一般采用的是3级及以上的分页技术。
硬件高速缓存(SRAM)以及TLB
SRAM就是我们理解的CPU Cache(L1/L2/L3)
Cache Line: 80x86体系结构中引入了一个叫行(line)的新单位。行由几十个连续的字节组成,它们以脉冲突发模式(burstmode)在慢速DRAM和快速的用来实现高速缓存的片上静态RAM (SRAM)之间传送,用来实现高速缓存。
读写策略:
TLB(Translation Lookaside Buffer): 当一个线性地址被第一次使用时,通过慢速访问RAM中的页表计算出相应的物理地址。同时,物理 地址被存放在一个TLB表项(TLBentry)中,以便以后对同一个线性地址的引用可以快速地得到转换。
Linux分页
Linux采用了一种同时适用于32位和64位系统的普通分页模型。正像前面“64位系统 中的分页”一节所解释的那样,两级页表对32位系统来说已经足够了,但64位系统需 要更多数量的分页级别。
4种页表分别为:
对于没有启用物理地址扩展的32位系统,两级页表已经足够了。Linux通过使“页上级目录”位和“页中间目录”位全为0,从根本上取消了页上级目录和页中间目录字段。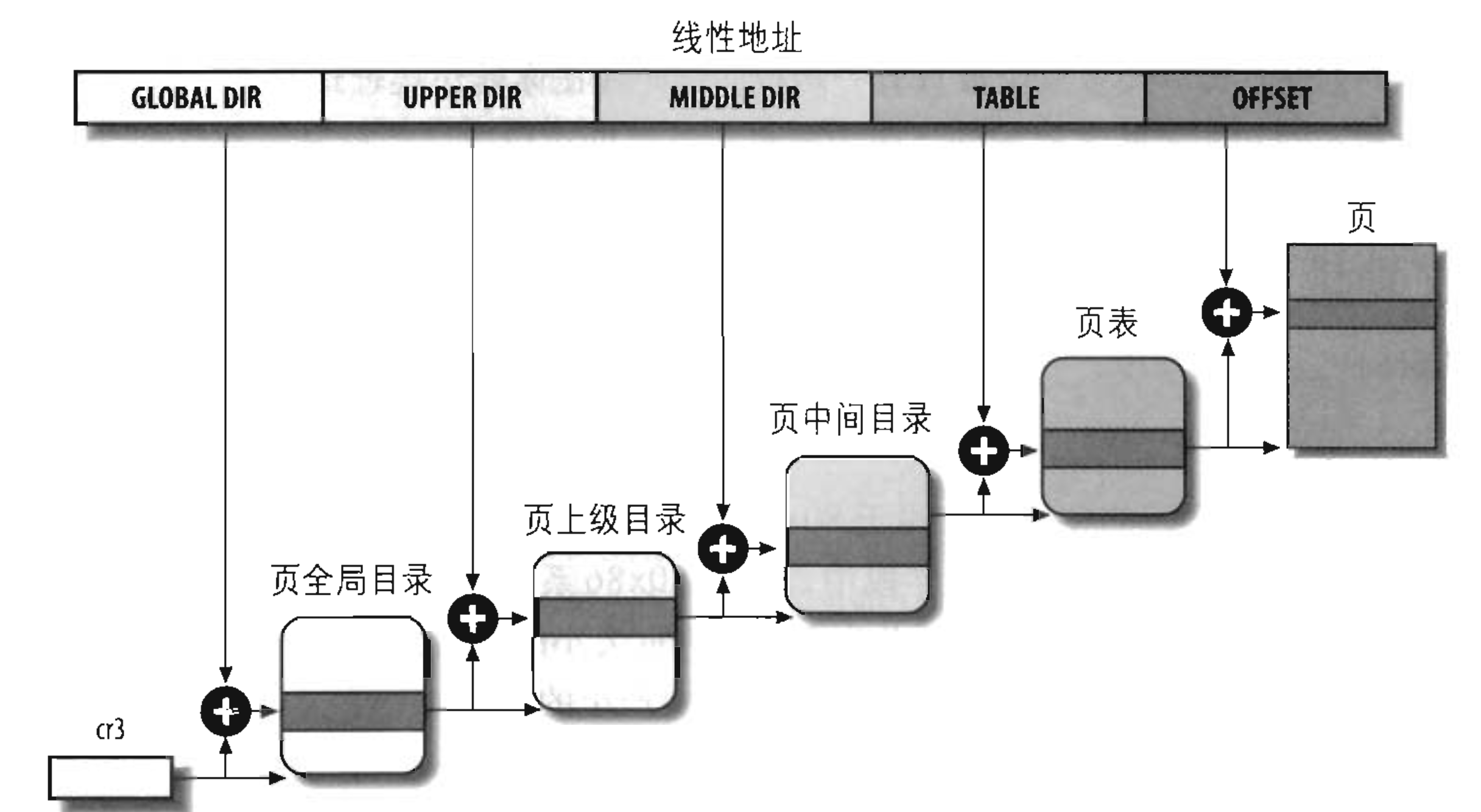
每一个进程有它自己的页全局目录和自己的页表集。当发生进程切换时(参见第三章“进程切换"一节),Linux把cr3控制寄存器的内容保存在前一个 执行进程的描述符中,然后把下一个要执行进程的描述符的值装入cr3寄存器中。因此,当新进程重新开始在CPU上执行时,分页单元指向一组正确的页表。
在初始化阶段,内核必须建立一个物理地址映射来指定哪些物理地址范围对内核可用而哪些不可用(或者因为它们映射硬件设备I/O的共享内存,或者因为相应的页框含有BIOS数据)。
进程的线性地址空间分成两部分:
当进程运行在用户态时,它产生的线性地址小于0xc0000000;当进程运行在内核态时,它执行内核代码,所产生的地址大于等于0xc0000000。但是,在某些情况下,内核为了检索或存放数据必须访问用户态线性地址空间。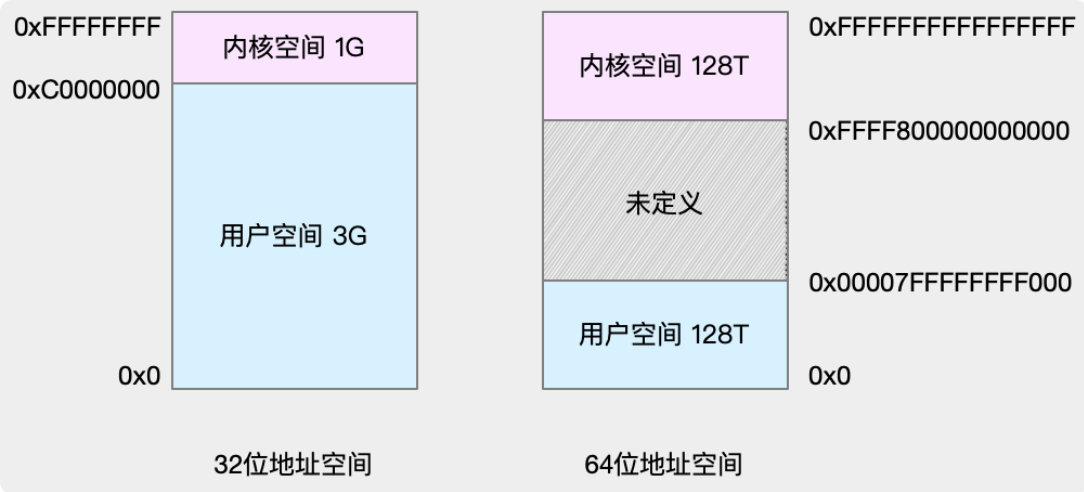
TLB 刷新: 一般来说,任何进程切换都会暗示着更换活动页表集。相对于过期页表。本地TLB表项必须被刷新:这个过程在内核把新的页全局目录的地址写入cr3控制寄在器时会自动完成。不过内核在下列情况下将避免TLB被刷新:
为了避免多处理器系统上无用的TLB刷新,内核使用一种叫做懒惰TLB (lazy TLB)模式的技术。其基本思想是,如果几个CPU正在使用相同的页表,而且必须对这些CPU上的一个TLB表项刷新,那么,在某些情况下,正在运行内核线程的那些CPU上的刷新就可以延迟。