Go by default will send requests with the header Connection: Keep-Alive and persist connections for re-use. The problem that I ran into is that the server is responding with Connection: Keep-Alive in the response header and then immediately closing the connection.
type Dialer struct {
...
// KeepAlive specifies the interval between keep-alive
// probes for an active network connection.
// If zero, keep-alive probes are sent with a default value
// (currently 15 seconds), if supported by the protocol and operating
// system. Network protocols or operating systems that do
// not support keep-alives ignore this field.
// If negative, keep-alive probes are disabled.
KeepAlive time.Duration
...
}
type Server struct {
...
// IdleTimeout is the maximum amount of time to wait for the
// next request when keep-alives are enabled. If IdleTimeout
// is zero, the value of ReadTimeout is used. If both are
// zero, there is no timeout.
IdleTimeout time.Duration
...
}
HTTP Client & Server 的Keep Alive 策略
Background
由于线上存在网络问题,会导致
GRPC HOL blocking, 于是决定把GRPC client改写成HTTP client。 改写HTTP client的过程还算顺利,但是搜索日志里面会发现有极少数的EOF错误。EOF这个东西一般是跟IO关闭有关系的,Google了下相关的错误,在stackoverflow找到相关的参考粗略看了下,问题很清晰,就是
server和client的Keep-Alive机制的问题,去看下client和serve的设置参数再去调下应该就可以解决问题。Keep-Alive parameter
HTTP Client
线上在使用的
http.Client的参数如下:Dial中的
DisableKeepAlives为开启状态KeepAlive: 官方文档介绍是一个用于
TCP Keep-Alive的probe指针,间隔一定的时间发送心跳包。每间隔60S进行一次Keep-AliveHTTP Server
线上在使用的
http server的参数KeepAlive主要是通过IdleTimeout来进行控制的,IdleTimeout如果为空则使用ReadTimeoutDebug again
可以看到,
client侧的Keep-Alive是60s,但是server侧的时间是间隔10s就去关掉空闲的连接。所以这里很容易就认为是:client侧的Keep-Alive心跳间隔时间太长了,server侧提前关闭了连接。于是作出更改:调整
client Keep-Alive为1s,这个时候感觉就不会出现EOF的错误了。于是修改参数,重新上线,持续观察一段时间发现还是有
EOF错误。看来只有进行本地复现看看究竟发生了什么。Reproduce
Mock EOF
在尝试复现
EOF错误的时候,看到有Hijack这种东西,还是挺好用的。可以看到直接在server侧关掉连接,client侧感知不到连接关闭确实是会有EOF错误发生的。EOF的原因知道了,在这里应该就是Server侧主动关闭了连接,至于为什么关闭连接,可以再继续往下看Mock Keep-Alive
然后先在本地开始尝试复现
Keep-Alive的问题,client侧使用KeepAlive: time.Second,每间隔一秒钟的keep-alive,server侧同样使用两秒IdleTimeout: time.Second。Client侧代码的Keep-AliveServer侧的代码:
理论上来讲,
client间隔一秒发送probe,server的idle为两秒是不会关闭连接的,但是实际却是关闭了旧的连接,重新创建了新的连接。Server侧输出:
抓包分析
结果有些出乎意料,因为是在本地进行代码复现的,所以去看下抓包分析结果。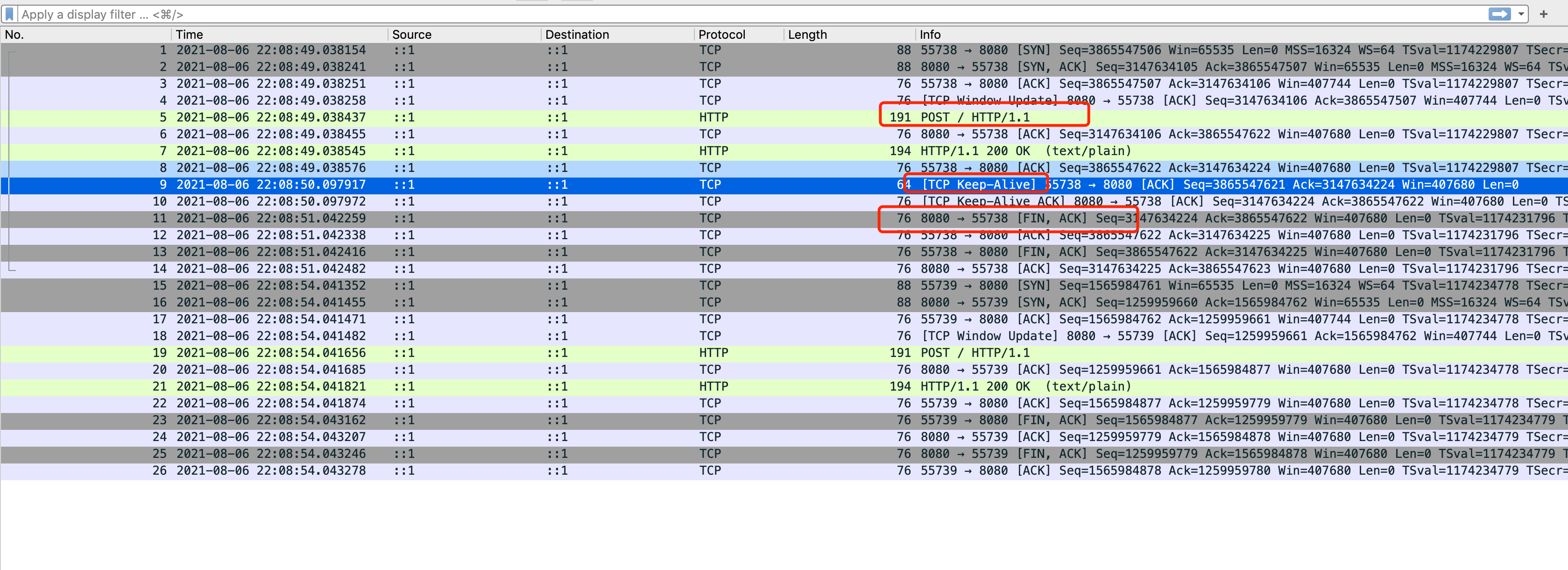
Client使用的基于TCP层面的Keep-alive协议,针对的是整条TCP连接Server侧明显是基于应用层协议做的判断所以初步的结论就是两者的
Keep-Alive是工作在不同层面,让人产生了误解。源码分析
Client
Client侧的代码在net/dial.go里面,主要进行Keep-Alive的逻辑如下上面的代码可以看到,最后调用的是
SetsockoptInt,这个函数就不在这具体的展开了,本质上来讲Client侧是在TCP 4层让OS来帮忙进行的Keep-Alive。因为网络的环境是比较复杂的,有很多的请求是跨
LB进行的,比如AWS的ELB之类的,所以这个keep-alive在这里也显得合理。Server
Server侧的代码在
net/http/server.go里:简单的说明下,
defer就是关闭连接用的,当函数退出的时候server会关闭连接。for循坏是处理连接请求用的,可以看出来HTTP server本身其实是不支持处理多个请求的,并没有实现HTTP 1.1协议中的Pipeline。然后再看
keep-alive的操作,先设置ReadDeadline,然后调用c.bufr.Peek这里的调用流程比较长,其实最后会落到conn.Read,本质上是一个阻塞操作。然后开始等待bufr里面的数据,如果client在这个时间段没有发送数据过来,则会退出for循环然后关闭连接。conclusion
所以在上述的场景下想要
reuse一个conn主要还是取决于server侧的idleTimeout。如果没收到client发送的请求是会主动发送fin包进行close的。Fix
Retry
其实解决方案有很多种,在这里线上采用的是客户端进行重试。这里引申一下,像上面这种错误,如果是
GET,HEAD等一些幂等操作的话,client代码库会自动进行重试。我们线上使用的是POST, 所以直接在业务侧进行重试。Increase IdleTimeout
另外一个解决方案就是增加
server的IdleTimeout,但是这样一来会消耗更多的server资源。Short-lived conn
还有一种方法就是短连接,这样对
server的资源浪费就减轻了,但是不能重用连接。整体latency会受到影响。