type ringBuffer struct {
pool *sync.Pool
}
// Push adds an element to one of the internal stripes and possibly drains if
// the stripe becomes full.
func (b *ringBuffer) Push(item uint64) {
// Reuse or create a new stripe.
stripe := b.pool.Get().(*ringStripe)
stripe.Push(item)
b.pool.Put(stripe)
}
func (s *ringStripe) Push(item uint64) {
s.data = append(s.data, item)
// Decide if the ring buffer should be drained.
if len(s.data) >= s.capa {
// Send elements to consumer and create a new ring stripe.
if s.cons.Push(s.data) {
s.data = make([]uint64, 0, s.capa)
} else {
s.data = s.data[:0]
}
}
}
func (p *tinyLFU) Increment(key uint64) {
// Flip doorkeeper bit if not already done.
if added := p.door.AddIfNotHas(key); !added {
// Increment count-min counter if doorkeeper bit is already set.
p.freq.Increment(key)
}
p.incrs++
if p.incrs >= p.resetAt {
p.reset()
}
}
func (r cmRow) reset() {
// Halve each counter.
for i := range r {
r[i] = (r[i] >> 1) & 0x77
}
}
valp := p.all[t]
// Avoid false sharing by padding at least 64 bytes of space between two
// atomic counters which would be incremented.
idx := (hash % 25) * 10
atomic.AddUint64(valp[idx], delta)
risterio code reading
risterio是一个基于内存的高性能KV存储,具有较高的读写性能和可靠性。它采用了多种技术来优化性能,分析代码可以看看具体的实现。
sync.Pool 实现BP-Wrapper
BP-Wrapper是一种无锁算法,BP代表的是
batching和prefetching的缩写,在risterio中主要使用了batching的思想。Batching
batching比较容易理解,论文中为每个线程设置了一个FIFO队列,每个页面请求都会先进入队列,当队列满或符合特定条件后再获取锁进行后续操作。这样会有一定的延迟,是否需要使用batching也取决于业务场景是否能够接受。Prefetching
Prefetching在论文中没有详细描述,但通过图示可以比较清楚地了解其作用,简单来说就是为了避免在锁定并发访问的情况下发生cache miss并需要进行I/O操作。因此,Prefetching可以在进行计算之前提前获取数据,只有在实际进行计算时才需要对数据进行加锁。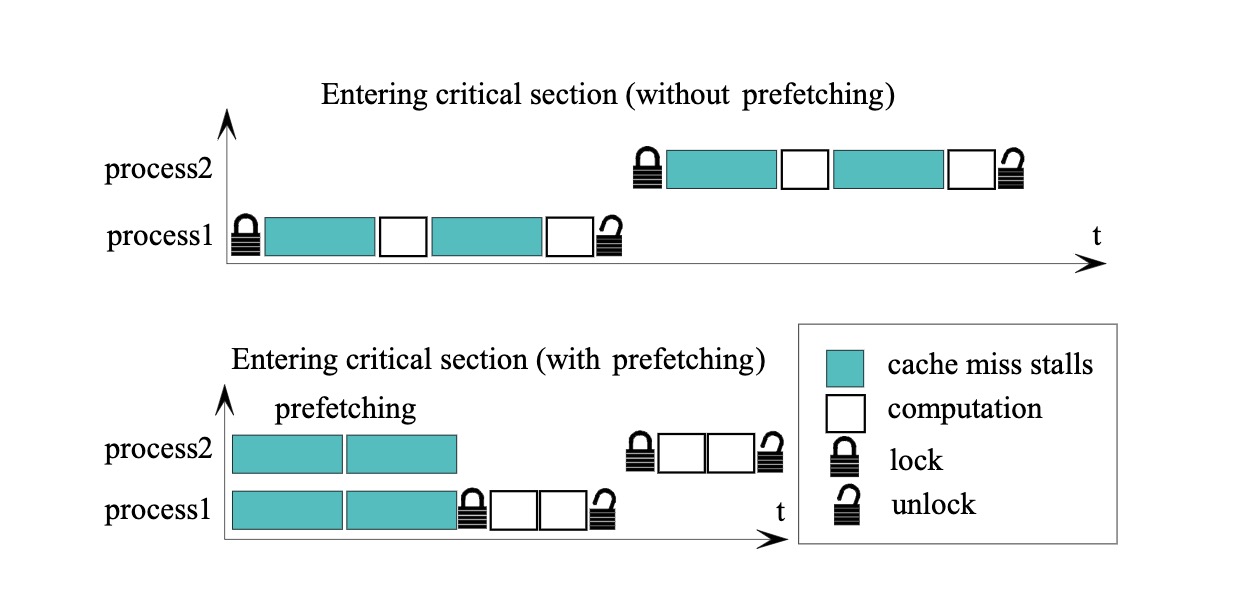
Sync.Pool 实现
他们的blog提到过实现批处理的功能,但也有提到使用channel的方式,不过通道的性能并没有sync.Pool表现得那么好。这是因为sync.Pool底层对于P做了一些优化,相当于实现了一层本地TLS(thread-local storage),将数据存储在poolLocal中,每个P都有自己的数据,可以大大减少竞争。
去看下risterio里面的代码实现,sync.Pool是在ringBuffer里定义的。其中核心思想就是当ringbuffer满了之后再去统计LFU里面的一些metrics信息。
stripe会先把数据写入到s.data里面,这个操作是无锁的。当目前的data数据超过cap之后会让
ringConsumer去进行消费。上面的代码关键点就在于每次操作前都是从pool里面拿到的ringStripe对象,所以就无需进行加锁操作,在还回pool之前就不会有并发的一些问题,这也是比较巧妙的一点。
后续的操作因为已经没有pool来保证并发,所以在processItem的时候还是需要lock来进行并发保护的。
memory bouding
过期策略
risterio的内存管理方式不同于freecache等其他缓存库,它引入了一个"cost"概念。每次调用set函数时,会为每个key附加一个cost值,通过计算maxCost来控制整个缓存中存储的key数量。与其他库根据key的使用量来决定哪些key需要被删除不同,risterio使用cost作为标准来管理内存。
LRU(Least Recently Used), 算法根据数据的访问时间来决定其生命周期,最近访问的存活时间越长。然而,这种算法的缺点也很明显,即短时间内有大量的冷数据访问时,会刷掉热数据,导致缓存的命中率下降。以golang里面的LRU cache实现来讲的话,一般都是基于map以及linkedlist来实现的。这样GET和SET的时间复杂度都可以到O(1)。
risterio 里面使用 Count-Min sketch的思想来自于bloomfilter,通过hash后的key来映射到位图上,在尽可能少的使用内存的情况下去进行过滤。但是在发生hash冲突的时候,可能不同的key会出现在位图的同一个位置,这就是为什么bloomfilter里面无法准确判断key是否存在(false postive)。
在Count-Min Sketch中,对于每一个值,写入时用n个独立的hash函数映射到每一行的一列中。每个位置上存储一个计数器,用于记录该位置上已经被映射到的元素的频率count。
查询时取最小的count作为element出现的次数,故名count-min。为了降低Count-Min Sketch表格的空间占用,TinyLFU会定期将Count-Min Sketch中的计数器减半。
Count-Min sketch的思想来自于bloomfilter,通过hash后的key来映射到位图上,在尽可能少的使用内存的情况下去进行过滤。但是在发生hash冲突的时候,可能不同的key会出现在位图的同一个位置,这就是为什么bloomfilter里面无法准确判断key是否存在(false postive)。
在Count-Min Sketch中,对于每一个值,写入时用n个独立的hash函数映射到每一行的一列中。每个位置上存储一个计数器,用于记录该位置上已经被映射到的元素的频率count。
查询时取最小的count作为element出现的次数,故名count-min。为了降低Count-Min Sketch表格的空间占用,TinyLFU会定期将Count-Min Sketch中的计数器减半。
tinyLFU还是受到了Caffeine的影响,TinyLFU是一种适用于大型数据库的高效缓存淘汰策略,它通过维护最近访问的项目的访问频率的近似表示来实现。相比之下,LRU和LFU是两种传统的缓存淘汰策略。LRU会优先淘汰最近最少使用的项目,而LFU会优先淘汰最不经常使用的项目。TinyLFU基于Count-Min Sketch策略并且可以在非常小的内存开销下实现高效率的统计,命中率也十分可观。除了上面的CM-Sketch, tinyLFU 前面还加了一层bloomFilter可以用来提高缓存命中率以及误判率。
cmSketch以及Bloomfilter具体实现的代码就不展示,整个tinyLFU的实现还是比较好理解的。写入的时候由于是batch写,所以对外提供的接口是Push,另外查询的时候因为不是准确的频率,所以是
p.freq.Estimate。还有个tinyLFU有意思的点就是当counter计数到一定的数量时,会去将counter里面的数目减半,进而减少记录访问频率的开支。
时间片管理TTL
TTL的管理在risterio里的实现也比较简单,基于时间戳来划分不同的桶,定期回收过期的桶。 以5秒为一个时间片,数据结构是map[bucketNum]keys,每间隔2.5秒就会循环清理一次所有的桶。时间片的计算是基于Unix时间戳,使用time.Now()/5 + 1来定位到对应的时间片。
clean的tick到了后会去清除上一轮已经过期掉的的时间片, 新的写入操作只会写入当前5s的时间片。 这点设计跟kafka里的时间轮有点不一样,kafka的时间轮是一个环形的多层时间轮,这里的实现比较简单,就相当于是一个顺序展开的时间片。
其他的一些优化
Hash加速
通过go link直接调用底层的汇编函数,目前是比较快的。
Map分片,减少锁力度
这个优化手段比较常见了,通过声明多个map,每个map单独持有锁进而减少锁的粒度
atomic padding
在高并发场景下,多个goroutine同时访问共享变量可能会导致false sharing的问题,即一个goroutine修改了共享变量的一部分,导致其他goroutine需要重新加载整个变量的情况,从而影响性能。 padding是在结构体中添加一些无用的字段,使得不同的字段位于不同的cache line中,从而避免了false sharing的问题。 atomic计数器在多核情况下的false sharing可通过padding解决。
Ref