 long8v
commented
2 years ago
long8v
commented
2 years ago code
official 코드는 code지만 tensorflow로 구현되어 있어, 학습을 위해 위의 코드로 봄
Readme
- LARS를 쓰지 않고 다른 optimizer를 사용하면 weight decay를 바꿔야한다.
- 논문의 implementation의 batch size가 매우 큰데, 작게해도 temperature, lr, projection head depth등을 잘 설정하면 학습이 된다
models
models/resnet.py
torchvision에서 models.resnet.ResNet 모델을 상속함. (self.layer1, ... 는 부모 클래스에서 나온 것)
argument는 아래와 같음
- block
- ResNet18은
models.resnet.BasicBlock사용 - 3x3 conv -> BN2D -> ReLU -> 3x3 conv -> BN2D (-> Downsample) -> ReLU
- ResNet50은
models.resnet.Bottleneck사용 - 1x1 conv -> BN2D -> ReLU -> 3x3 conv -> BN2D (-> Downsample) -> ReLU
- https://pytorch.org/vision/0.8/_modules/torchvision/models/resnet.html
- ResNet18은
- cifar_head
- cifar_head가 True면 self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)로 바꾸고 진행, cifar이미지 크기가 달라서 맞춰주고 가는듯함
- cifar_headr가 False면 maxpooling함
flatten이라는 nn.Module을 정의하여 마지막 output에 대해 dim=1부터 flatten함 dim=0은 batch_size고 batch_size 이후의 feature(W H) kernel 그냥 flatten 하는듯
import torch.nn as nn
import torchvision.models as models
import torch
class Flatten(nn.Module):
def __init__(self, dim=-1):
super(Flatten, self).__init__()
self.dim = dim
def forward(self, feat):
return torch.flatten(feat, start_dim=self.dim)
class ResNetEncoder(models.resnet.ResNet):
"""Wrapper for TorchVison ResNet Model
This was needed to remove the final FC Layer from the ResNet Model"""
def __init__(self, block, layers, cifar_head=False, hparams=None):
super().__init__(block, layers)
self.cifar_head = cifar_head
if cifar_head:
self.conv1 = nn.Conv2d(3 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = self._norm_layer(64)
self.relu = nn.ReLU(inplace=True)
self.hparams = hparams
print('** Using avgpool **')
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
if not self.cifar_head:
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
return x
class ResNet18(ResNetEncoder):
def __init__(self, cifar_head=True):
super().__init__(models.resnet.BasicBlock, [2, 2, 2, 2], cifar_head=cifar_head)
class ResNet50(ResNetEncoder):
def __init__(self, cifar_head=True, hparams=None):
super().__init__(models.resnet.Bottleneck, [3, 4, 6, 3], cifar_head=cifar_head, hparams=hparams)models/encoder.py
- EncoderProject : forward에 out='h'면 project하기 전에 return 'z'면 project 하고 나서 return
- conv(ResNet) -> fc1 -> bn1 -> relu -> fc2 -> bn2(no bias)
- BatchNorm1dNoBias : nn.BatchNorm1d를 상속받고 bias의 requires_grad를 꺼주면 됨!
class BatchNorm1dNoBias(nn.BatchNorm1d): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self.bias.requires_grad = False
class EncodeProject(nn.Module): def init(self, hparams): super().init()
if hparams.arch == 'ResNet50':
cifar_head = (hparams.data == 'cifar')
self.convnet = models.resnet.ResNet50(cifar_head=cifar_head, hparams=hparams)
self.encoder_dim = 2048
elif hparams.arch == 'resnet18':
self.convnet = models.resnet.ResNet18(cifar_head=(hparams.data == 'cifar'))
self.encoder_dim = 512
else:
raise NotImplementedError
num_params = sum(p.numel() for p in self.convnet.parameters() if p.requires_grad)
print(f'======> Encoder: output dim {self.encoder_dim} | {num_params/1e6:.3f}M parameters')
self.proj_dim = 128
projection_layers = [
('fc1', nn.Linear(self.encoder_dim, self.encoder_dim, bias=False)),
('bn1', nn.BatchNorm1d(self.encoder_dim)),
('relu1', nn.ReLU()),
('fc2', nn.Linear(self.encoder_dim, 128, bias=False)),
('bn2', BatchNorm1dNoBias(128)),
]
self.projection = nn.Sequential(OrderedDict(projection_layers))
def forward(self, x, out='z'):
h = self.convnet(x)
if out == 'h':
return h
return self.projection(h)### losses.py
non-linear transformation된 z(n, feature)를 받고, normalize한 뒤, tau로 나눈뒤 z @ z.T를 해서 logit을 구함
이때 자기 자신은 제외해야하므로 logits[np.arange(n), np.arange(n)] = -self.LARGE_NUMBER 와 같이 (0, 0) ... 은 마이너스 무한대를 줌
이때 labels 값은 (np.repeat(np.arange(n), m) + [np.tile](https://numpy.org/doc/stable/reference/generated/numpy.tile.html)(np.arange(m) * n//m, n)) % n한 것을 .reshape(n, m)하고 [:, 1:] 인덱싱. (이때 m은 multiplier. 이미지 당 augmentation 된 이미지 개수?) (c.f. [np.tile과 np.repeat의 차이점](https://yeko90.tistory.com/65))n = 3, m =2 이라고 할 때, np.repeat(np.arange(n), m) -> [0, 0, 1, 1, 2, 2] + np.tile(np.arange(m) * n // m , n) -> [0, 1, 0, 1, 0, 1] =합 -> [0, 1, 1, 2, 2, 3] . % n -> [0, 1, 1, 2, 2, 0] .reshape(n, m)[:, 1:].reshape(-1) -> [[0, 1], [1, 2], [2, 0]] -> [[1], [2], [0]] -> [1, 2, 0]
복잡한데.. #8 에도 추측한대로 multi-GPU 환경에서 모든 클래스가 100개라고 하고 GPU가 10개라고 할 때, n번째 GPU의 i번째 데이터가 (0, 1, 2, ...) (11, 12, ...) 이런식으로 들어가서 그런듯함
이후 log_softmax를 취하고 실제 label값과 예측값의 logprob를 sum하고 이를 n * (m - 1) * norm(default=1)으로 나눈 값의 음수를 loss로 둠(이미 log_softmax를 취해서 분모를 위해 합을 구할 필요 없이 1이 되는듯함) class NTXent(nn.Module): """ Contrastive loss with distributed data parallel support """ LARGE_NUMBER = 1e9
def __init__(self, tau=1., gpu=None, multiplier=2, distributed=False):
super().__init__()
self.tau = tau
self.multiplier = multiplier
self.distributed = distributed
self.norm = 1.
def forward(self, z, get_map=False):
n = z.shape[0]
assert n % self.multiplier == 0
z = F.normalize(z, p=2, dim=1) / np.sqrt(self.tau)
if self.distributed:
z_list = [torch.zeros_like(z) for _ in range(dist.get_world_size())]
# all_gather fills the list as [<proc0>, <proc1>, ...]
# TODO: try to rewrite it with pytorch official tools
z_list = diffdist.functional.all_gather(z_list, z)
# split it into [<proc0_aug0>, <proc0_aug1>, ..., <proc0_aug(m-1)>, <proc1_aug(m-1)>, ...]
z_list = [chunk for x in z_list for chunk in x.chunk(self.multiplier)]
# sort it to [<proc0_aug0>, <proc1_aug0>, ...] that simply means [<batch_aug0>, <batch_aug1>, ...] as expected below
z_sorted = []
for m in range(self.multiplier):
for i in range(dist.get_world_size()):
z_sorted.append(z_list[i * self.multiplier + m])
z = torch.cat(z_sorted, dim=0)
n = z.shape[0]
logits = z @ z.t()
logits[np.arange(n), np.arange(n)] = -self.LARGE_NUMBER
logprob = F.log_softmax(logits, dim=1)
# choose all positive objects for an example, for i it would be (i + k * n/m), where k=0...(m-1)
m = self.multiplier
labels = (np.repeat(np.arange(n), m) + np.tile(np.arange(m) * n//m, n)) % n
# remove labels pointet to itself, i.e. (i, i)
labels = labels.reshape(n, m)[:, 1:].reshape(-1)
# TODO: maybe different terms for each process should only be computed here...
loss = -logprob[np.repeat(np.arange(n), m-1), labels].sum() / n / (m-1) / self.norm
# zero the probability of identical pairs
pred = logprob.data.clone()
pred[np.arange(n), np.arange(n)] = -self.LARGE_NUMBER
acc = accuracy(pred, torch.LongTensor(labels.reshape(n, m-1)).to(logprob.device), m-1)
if get_map:
_map = mean_average_precision(pred, torch.LongTensor(labels.reshape(n, m-1)).to(logprob.device), m-1)
return loss, acc, _map
return loss, acc
## [SSL.py](https://github.com/AndrewAtanov/simclr-pytorch/blob/master/models/ssl.py)
utils에 ContinousSampler라는걸 정의했는데 이렇게 하면 for n in range(epochs)로 안해도될듯class ContinousSampler(torch.utils.data.sampler.Sampler): def init(self, sampler, n_iterations): self.base_sampler = sampler self.n_iterations = n_iterations
def __iter__(self):
cur_iter = 0
while cur_iter < self.n_iterations:
for batch in self.base_sampler:
yield batch
cur_iter += 1
if cur_iter >= self.n_iterations: return
def __len__(self):
return self.n_iterations
def set_epoch(self, epoch):
self.base_sampler.set_epoch(epoch)
- BaseSSL :
데이터 다운로드, 데이터로더 정의 부분이 모델에 들어가 있음.
- SimCLR : 프리트레이닝을 위한 모델
BaseSSL을 상속받음. EncoderProject 불러와서 forward하고 losses.NTXent불러와서 criterion
- SSLEval : 파인튜닝을 위한 모델
BaseSSL을 상속받음. linear projection(finetuning)을 하기 위해서 self.model을 새로 정의함. 모델의 인코더에 'h'를 주고 forward한 뒤 그 값을 linear로 줌. 이후 label과 crossentropy loss
학습은 finetune 단계에서는 모델전체를 학습하고, feature-based(linear만 학습하는 경우)일 경우 linear model만 학습함.def train(self, mode=True):
if self.hparams.finetune:
super().train(mode)
else:
self.model.train(mode)
TL; DR
problem : supervised learning을 하기 위해 큰 annotation 비용. 이전의 SSL은 복잡한 아키텍쳐를 가지고 있음. solution : 이미지를 augmentation하여 원래 이미지와 augmented image가 같은 이미지로 분류되도록 학습. 이미지에서 representation을 하고 이를 non-linear로 transform한 뒤 두 pair의 내적 곱의 log softmax가 최대화(=크로스엔트로피 최소화)하도록 하는 contrastive loss 적용. result : ImageNet에 대해 linear evaluation했을 때 top-1 accuracy 76.5%로 SOTA, 실제 데이터의 1%를 사용하여 fine-tuning한 모델이 top-5에서 AlexNet보다 더 좋은 성능. transfer-learning에서도 12개 데이터셋 중 5개는 supervised 보다 나은 성능, 5는 유사, 2는 떨어짐.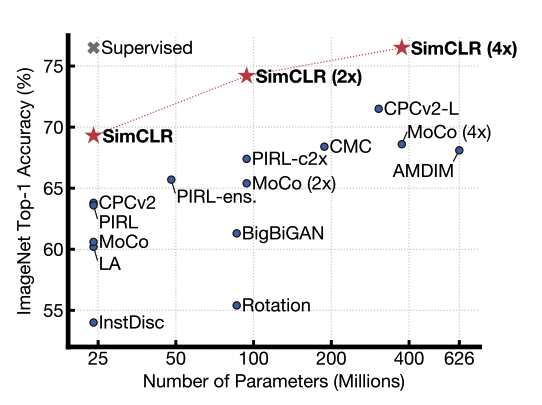
Abstract
visual representation을 위한 contrastive learning을 위한 간단한 프레임 워크를 제안. 우리의 가장 중요한 세가지 요소에 대해 학습 (1) 데이터 어그멘테이션의 구성이 효과적인 예측 태스크를 정의하는데 중요하게 작용함 (2) representation과 contrastive loss 사이의 nonlinear한 transformation이 매우 중요함 (3) contrastive learning은 큰 배치사이즈와 더 많은 트레이닝 스텝을 필요로 함
Method
Contrastive Learning Framework
4가지의 구성요소 1) stochastic data augmentation 같은 이미지에서 나온 x를 두개의 augmentation을 적용하여 나온 x_i, x_j를 positive pair라고 부름
2) neural network인 base encoder f( ) 데이터에 대해 represntation vector를 뽑아냄. ResNet + average pooling layer를 거쳐 h를 만듦
3) small neural network projection head g( ) FCN + ReLU + FCN. g( )의 결과물인 z로 contrastive loss를 구함. 위의 f( ) 에서 나온 결과물인 h로 contrastive loss가 나오는 것이 효과적이지 않음을 보임
4) contrastive loss function k개의 augmented sample이 있을 때, 같은 sample에서 나온 이미지에서 나온 sample과 그렇지 않은 sample을 구분해야함. N개의 batch size로 contrastive prediction task를 하면, 두 종류의 aug를 지나면 총 2N개의 데이터가 생긴다. 이 때 N개의 positive pair를 빼면 2(n-1) 개의 negative pair가 생긴다. 유사도를 내적으로 구하고,
positive pair에 대한 loss function은 아래와 같이 된다.
이를 모든 positive pair (i, j), (j, i)에 대해 구하는 것이 loss term이 되고, 여기서 temperature \tau로 나누어주므로 줄여서 본 논문에서 NT-Xent(the normalized temperature-scaled cross entropy loss)
softmax처럼 생김. triplet loss 랑 비슷함.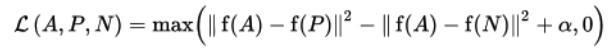
Training with Large Batch Size
memory bank(각 이미지 feature를 저장해 둠)를 사용하는 대신, batch size를 256~8192까지 늘려보어 실험해보았다. 큰 배치사이즈에서는 학습이 불안정하여 LARS optimizer를 사용했고, 배치사이즈에 따라 32`~128 core의 TPU를 사용했다. 한 device에서 positive pair가 들어가도록 디자인되기 때문에 로컬 정보가 분류 모델에 적용될 수 있음. 이를 방지하기 위해 모든 device의 mean과 std를 구하는 global batch normalization이 사용됨
Data Augmentation for Contrastive Representation Learning
SSL에 적용하기 위해는 두개 이상의 augmentation을 적용해야 했고, random crop + color distortion 조합이 가장 성능이 좋았음
representation에 non-linear transformation을 추가하는 것이 성능에 크게 기여함(linear 보다 3%, 없는것보다 10%이상)
또한 projection을 하기 전의 h를 사용하는 것이 g(z)를 사용하는 것보다 성능이 10%이상 차이남 -> representation이 잘됐다는 의미
contrastive loss로 사용한 이 성능에 크게 기여함 . contrastive learning을 위한 loss들이 있었음. 이때 cross entropy와 달리 다른 loss들은 negative sample에 가중을 두지 않았음(?)
. L2 norm을 추가하는지(dot product vs cosine), tau(temperature)에 대한 성능 차이가 있었음 (L2 적용. tau=0.1)
. contrastive learning을 위한 loss들이 있었음. 이때 cross entropy와 달리 다른 loss들은 negative sample에 가중을 두지 않았음(?)
. L2 norm을 추가하는지(dot product vs cosine), tau(temperature)에 대한 성능 차이가 있었음 (L2 적용. tau=0.1)
supervised learning보다 더 큰 batch size(bs:8192까지), 더 긴 학습 시간이 필요했음