 longxiaofei
commented
2 years ago
longxiaofei
commented
2 years ago 是这样的。对五个关键词三年内的日级数据爬取,只需要发送两次请求。 对五个关键词一年内的日级数据爬虫,只需要发送一次请求。
所以,对五个关键词的一年的日级数据,发送一次请求后,得到最细粒度的数据后。 可以得出周级、月级、季级,年级的统计数据。
而不是发送365次请求哈。
Closed 17816712353 closed 2 years ago
longxiaofei
commented
2 years ago 是这样的。对五个关键词三年内的日级数据爬取,只需要发送两次请求。 对五个关键词一年内的日级数据爬虫,只需要发送一次请求。
所以,对五个关键词的一年的日级数据,发送一次请求后,得到最细粒度的数据后。 可以得出周级、月级、季级,年级的统计数据。
而不是发送365次请求哈。
感谢作者提供这个包,解决了我论文的一个重要数据需求!
在使用的过程中,我发现一个能够提升爬取效率的思路,如果作者能够采用,将是我们社科的福音!
现有百度指数的爬取逻辑是日度数据,但如图所示,官网是直接提供了自定义日期+平均的数据的。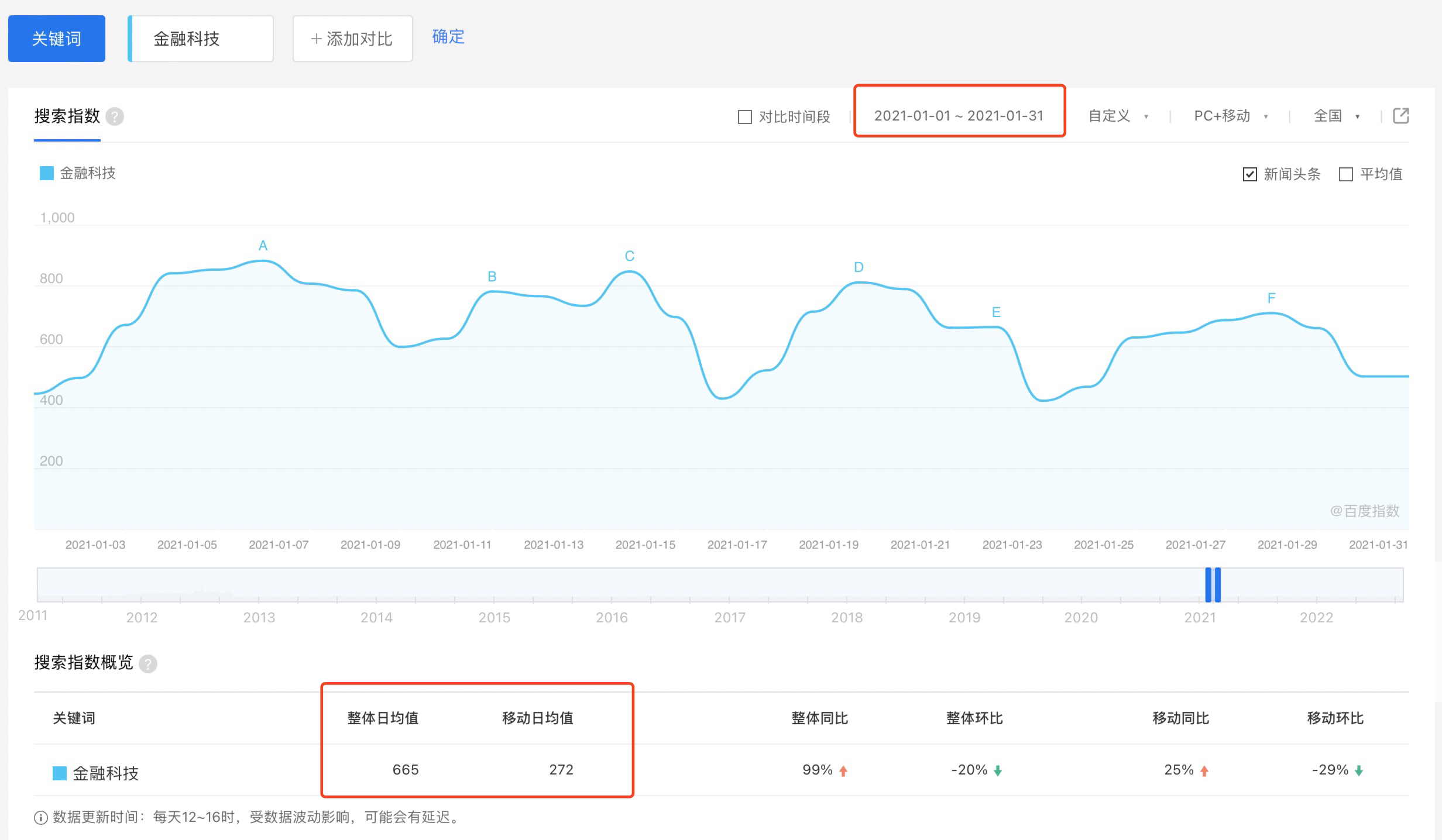
量少还行,但当关键词和所需期间较长时,爬取日度数据非常消耗cookies,以及会出现网络错误等问题,导致爬取效率很低。但大多数情况,我们可能只需要一个月度平均/年度平均或者其他任意期间的平均百度指数即可。
如果能够采用这个思路,提供自定义期间的均值爬取,那一年访问365次能够改进到12次(月度平均),或者仅需要爬取1次(年度平均),将大大减少爬取出现的问题,提高爬取效率。
这对于我们这种博士生动辄10年几十个关键词的百度指数爬取将大大友好(即使我们爬取到日度,依然要转换成年度平均)。
不求作者采纳,仅为作者提供一个我使用过程中的小小看法。再次感谢作者的包!