 lw-lin
commented
8 years ago
lw-lin
commented
8 years ago @cjuexuan
在 Streaming 官方的 Programming Guide 里,有下面的图示:
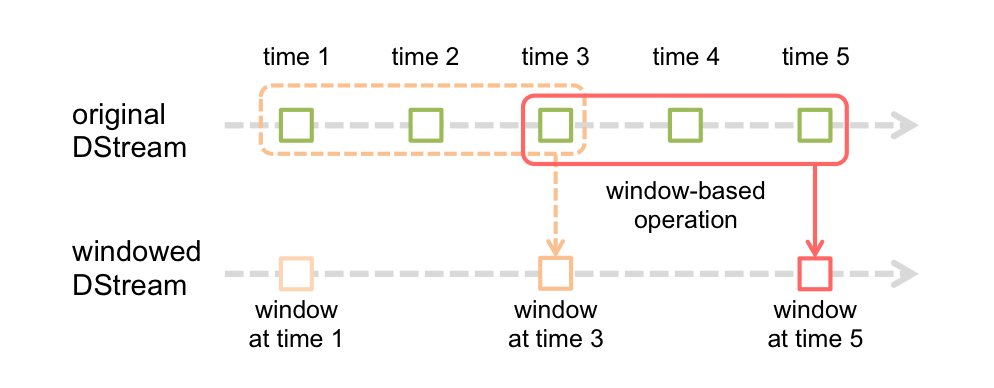
上图里 batch duration = 1, window length = 3, sliding interval = 2 任何情况下 Job Submit 是以 batch duration 为准,但本 batch 里不一定生成 RDD —— 对于 window 操作,每隔 sliding interval 才去实际生成 RDD,每次计算的结果包括 window length 个 batch 的数据。
 cjuexuan
cjuexuan luckuan
luckuan pzz2011
pzz2011
 superwood
superwood zqhxuyuan
zqhxuyuan
您能否抽时间讲一下这三个之间的关系,从doc上看貌似只是说window duration和sliding duration都应该设为batch duration的倍数,而job的submit到底是参照的batch duration还是sliding duration,请您为我解惑