 lzh2nix
commented
4 years ago
lzh2nix
commented
4 years ago golang tools简介(2020.08.25)
原文: https://www.alexedwards.net/blog/an-overview-of-go-tooling
这不是简介这是十全大补丸
- go env 查看环境变量
- go help environment 查询没每一个环境变量的具体描述
- go get github.com/foo/bar@8e1b8d3 获取依赖
- gofmt -w -r 'strings.Replace(a, b, c, -1) -> strings.ReplaceAll(a, b, c)' . 来重构代码
- go doc strings.ReplaceAll 快速查看看文档
- go doc -src sync.Mutex.Lock 快速查看源码
- go test . 跑当前目录下的所有test
- go test ./... 跑当前目录+所有子目录的test
- go test ./foo/bar 跑/foo/bar下的test
- go test -race ./... 竞争检测
- go clean -testcache 清除testcache
- go test -v -run=^TestFooBar$ . 跑制定的case
- go test -short ./... 跳过耗时太久的case
- go test -failfast ./... 一个case不够的时候提早终止
- go test -coverprofile=/tmp/profile.out ./... go tool cover -html=/tmp/profile.out 查看测出是覆盖情况
- go test -run=^TestFooBar$ -count=500 . 跑多次
- go test -c -o=/tmp/foo.test . stress -p=4 /tmp/foo.test -test.run=^TestFooBar$ 做并行执行测试
- go test all 跑所有测试(包含依赖部分)
- gofmt -w -s -d . gofmt 当前目录
- go vet . 做静态分析
- golint . 做style check
- go mod tidy/go mod verify 进行依赖验证
- go build -o=/tmp/foo ./cmd/foo 输出制定binary
- GOOS=linux GOARCH=amd64 go build -o=/tmp/linux_amd64/foo . 进行交叉编译
- go test -run=^$ -bench=. ./... 跑所有benchmark 测试(不跑普通的测试)
- go test -bench=. -benchtime=5s ./... 跑5s
- go test -bench=. -benchtime=500x ./... 跑500次
- go test -bench=. -cpu=1,4,8 ./... 分别使用1,4,8 proc去跑测试
- $ go test -run=^$ -bench=^BenchmarkFoo$ -[cpuprofile|memprofile|blockprofile|mutexprofile]=/tmp/cpuprofile.out . 生成各种profile
- go tool pprof -http=:5000 /tmp/cpuprofile.out 加载上一步生成的profile
- go tool pprof --nodefraction=0.1 -http=:5000 /tmp/cpuprofile.out 跳过占比小于10%
- go test -run=^$ -bench=^BenchmarkFoo$ -trace=/tmp/trace.out . 然后 go tool trace /tmp/trace.out 查看trace文件
具体的check sheet https://github.com/fedir/go-tooling-cheat-sheet/blob/master/go-tooling-cheat-sheet.pdf
里面附带的几篇文章也是超级好: Profiling and optimizing Go web applications Debugging performance issues in Go programs Daily code optimization using benchmarks and profiling Profiling Go programs with pprof go tool trace
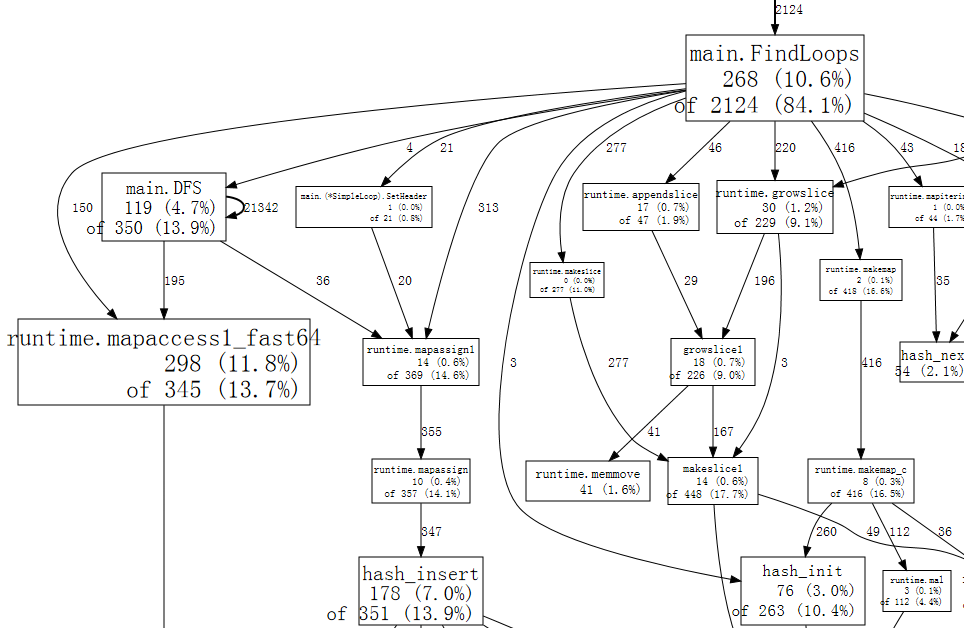 查看代码
查看代码

 这里可以看到所有goroutine的列表,感觉比pprof里的更直接一点,再点击一层之后可以看到:
这里可以看到所有goroutine的列表,感觉比pprof里的更直接一点,再点击一层之后可以看到:
 从这里可以看到 在
从这里可以看到 在  这样去分析问题就快捷很多了。
这样去分析问题就快捷很多了。
 这里c虽然使用了new操作,但是作用域没有超出CenterCursor函数所有还是会在栈上分配。
这里c虽然使用了new操作,但是作用域没有超出CenterCursor函数所有还是会在栈上分配。
 go routine时代
go routine时代


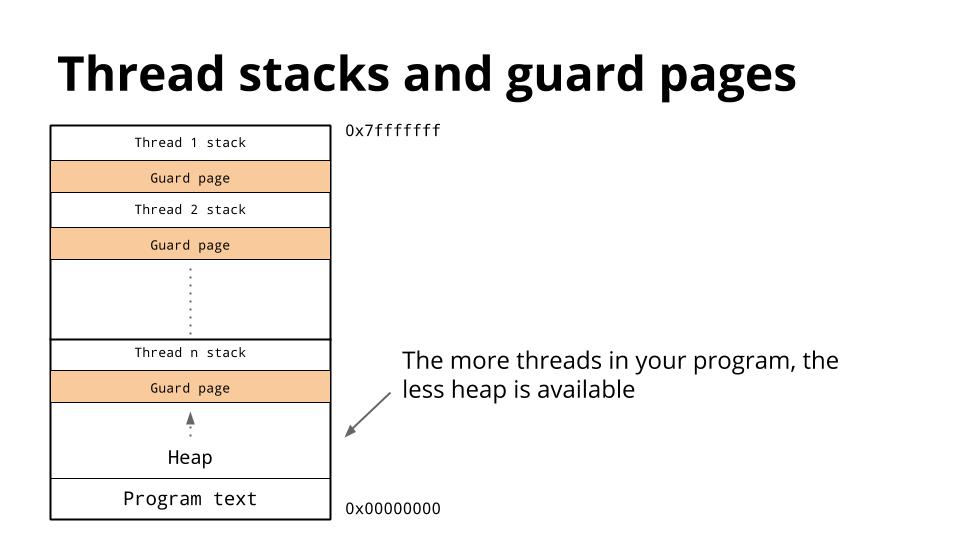 线程越多这个gard page也就越多,这对内存资源来说是很多的浪费。go 在这方面的改进就是没有gard page,初始栈只有8k,然后随着需求的增加可以不断的申请。这里涉及到一个golang的栈管理相关的知识点。
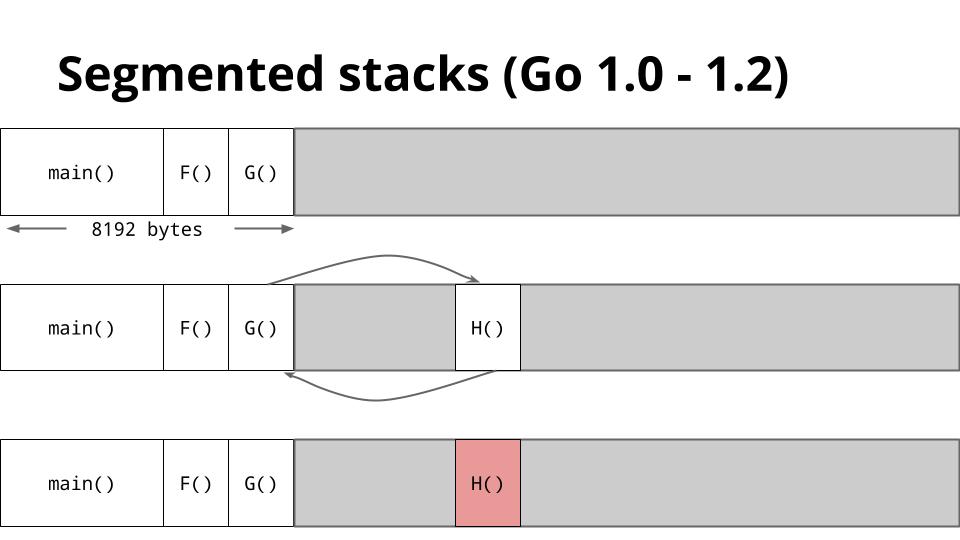
在1.0~1.2中的操作是, 先给他个8k的栈,如果需要更大的空间的时候就新开一个栈,等返回之后把新的栈给释放掉。
线程越多这个gard page也就越多,这对内存资源来说是很多的浪费。go 在这方面的改进就是没有gard page,初始栈只有8k,然后随着需求的增加可以不断的申请。这里涉及到一个golang的栈管理相关的知识点。
在1.0~1.2中的操作是, 先给他个8k的栈,如果需要更大的空间的时候就新开一个栈,等返回之后把新的栈给释放掉。
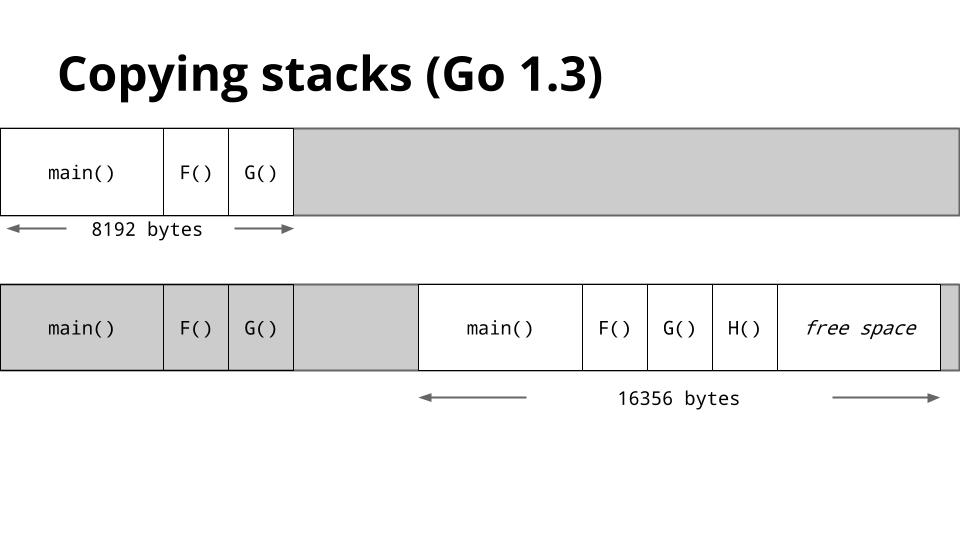
 如果有大量的goroutine做申请/释放操作的话就会引起hot split问题, 为了解决这个问题在1.3中引入了copy技术,如果一个goroutine需要更大的栈了就先申请一个更大栈,然后将所有老的栈里的东西拷贝过去,然后在新的栈里执行程序。
如果有大量的goroutine做申请/释放操作的话就会引起hot split问题, 为了解决这个问题在1.3中引入了copy技术,如果一个goroutine需要更大的栈了就先申请一个更大栈,然后将所有老的栈里的东西拷贝过去,然后在新的栈里执行程序。
 详细可以参考
详细可以参考
目录
An Overview of Go's Tooling(2020.08.25) Profiling Go Programs(2020.08.26) Using Go as a scripting language in Linux(2020.08.27) Profiling and optimizing Go web applications(2020.08.28) Diagnostics(2020.08.29) Five things that make Go fast(2020.08.29) Practical Go Benchmarks(2020.08.29)