 lzh2nix
commented
4 years ago
lzh2nix
commented
4 years ago golang work-stealing调度(2020.09.09)
原文: https://rakyll.org/scheduler/
关于调度这块看来好多文章,就是不知道如何下手。看这种概要性设计文章还好,但是看源码分析性的文章的时候就一头污水。想来想去还是回到之前的模式 ”看文章写总结“,暂时不去关心太底层的东西。
golang GMP模型
调度的目的就是充分利用计算机的资源,从 1.1 开始 golang 的调度器就是一个 M:N 的调度器, 这里的 N 是通过 GOMAXPROCS 指定的。
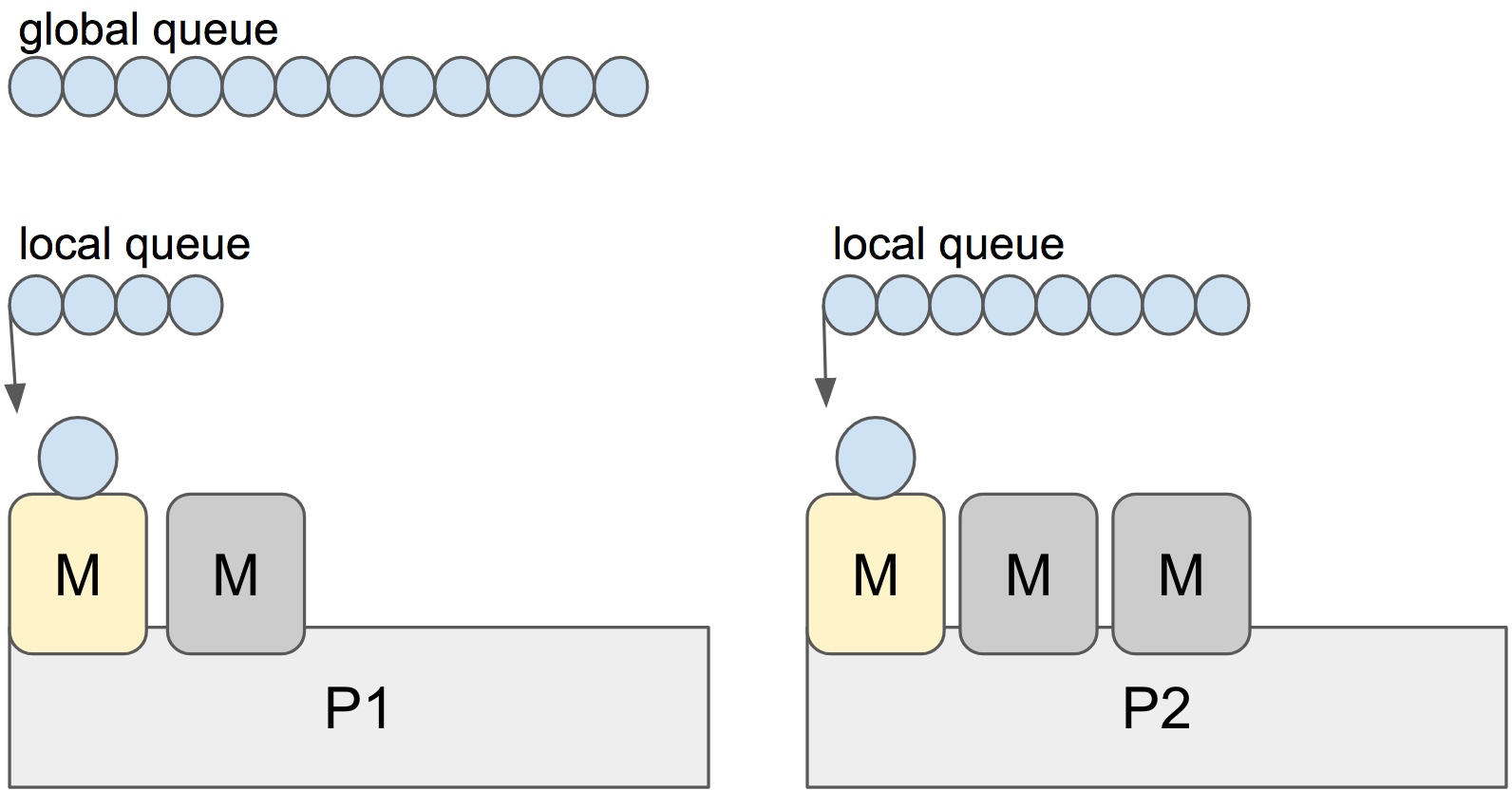 G: goroutine
M: 系统线程
P: process
G: goroutine
M: 系统线程
P: process
之前一直不太理解这里为啥叫process,已经他和cpu的核数有啥关系,看了这篇文章才发现这里的 P 只是一个虚拟的概念,理解成 M 执行的上下文环境 确实更合适一点,M 执行的时候需要获得一个P。 调度规则
- check lock queue
- try to steal from other Ps
- check global runnable queue(由于 global 这里需要加锁,61次才去check一次)
Stealing
steal 的原则就是随机选择一个P然后偷一半的goroutine 放到local queue里
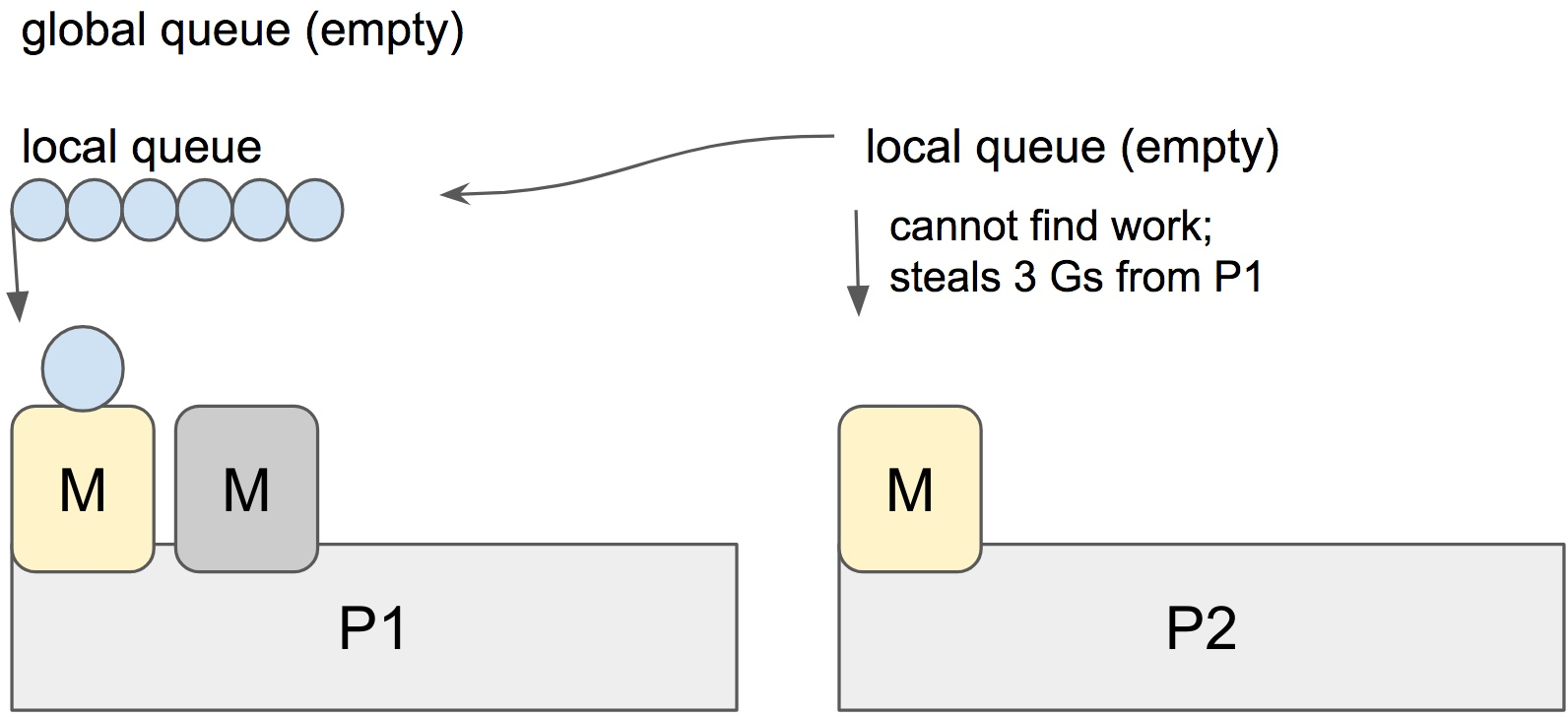
Spining threads
为了避免os不断的调度 thread 带来的性能损耗(上下文切换+系统调用block的中恢复),go这边在以下几种场景里会spinning thread
- M获取P需要可运行的G
- M寻找一个可用的P
- 有一个idle的P但是没有空闲的M(这时候spin结束之后M可以立马找到工作)
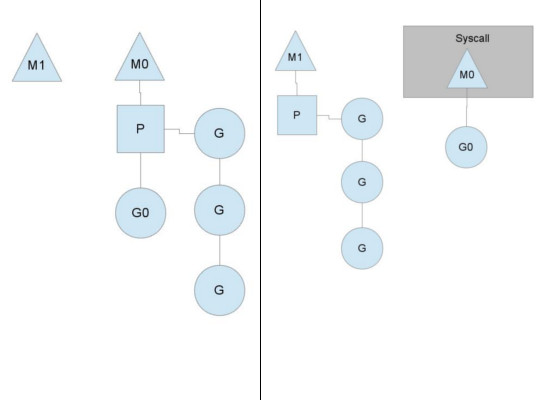 当发生系统调用的时候当前的 M 会 block 在系统调用上,他持有的P会 handoff 给空闲的M。当从系统调用返回的时候,先看能不能从其他M偷一个P过来, 如果能获得一个P就将G放到这个P的local queue里,否则就将 G 放到 global queue里去。
当发生系统调用的时候当前的 M 会 block 在系统调用上,他持有的P会 handoff 给空闲的M。当从系统调用返回的时候,先看能不能从其他M偷一个P过来, 如果能获得一个P就将G放到这个P的local queue里,否则就将 G 放到 global queue里去。 进一步每个goroutine的执行情况和通过go tool trace查看https://github.com/lzh2nix/articles/issues/77#issuecomment-683261463 trace章节
进一步每个goroutine的执行情况和通过go tool trace查看https://github.com/lzh2nix/articles/issues/77#issuecomment-683261463 trace章节 这里就是把cid的地址传递给ioctl
这里就是把cid的地址传递给ioctl
目录
Go's work-stealing scheduler(2020.09.09) The Go scheduler(2020.09.09) Address Alignments in Go(2020.09.10) The Go scheduler II(2020.09.10) Anatomy of a function call in Go(2020.09.12) Scheduler Tracing in Go(2020.09.12) unsafe.Pointer and system calls(2020.09.12)