 magento-engcom-team
commented
7 years ago
magento-engcom-team
commented
7 years ago @gwharton, thank you for your report. We were not able to reproduce this issue by following the steps you provided. If you'd like to update it, please reopen the issue. We tested the issue on 2.2.0
 emmathepossum
emmathepossum gwharton
gwharton cytracon
cytracon My dev store went again at about 2am on the 17th. See phpmyadmin attached. The first entry in the table is marked as running. Then there are 6000 odd entries following it, all in the pending state and growing.
My dev store went again at about 2am on the 17th. See phpmyadmin attached. The first entry in the table is marked as running. Then there are 6000 odd entries following it, all in the pending state and growing.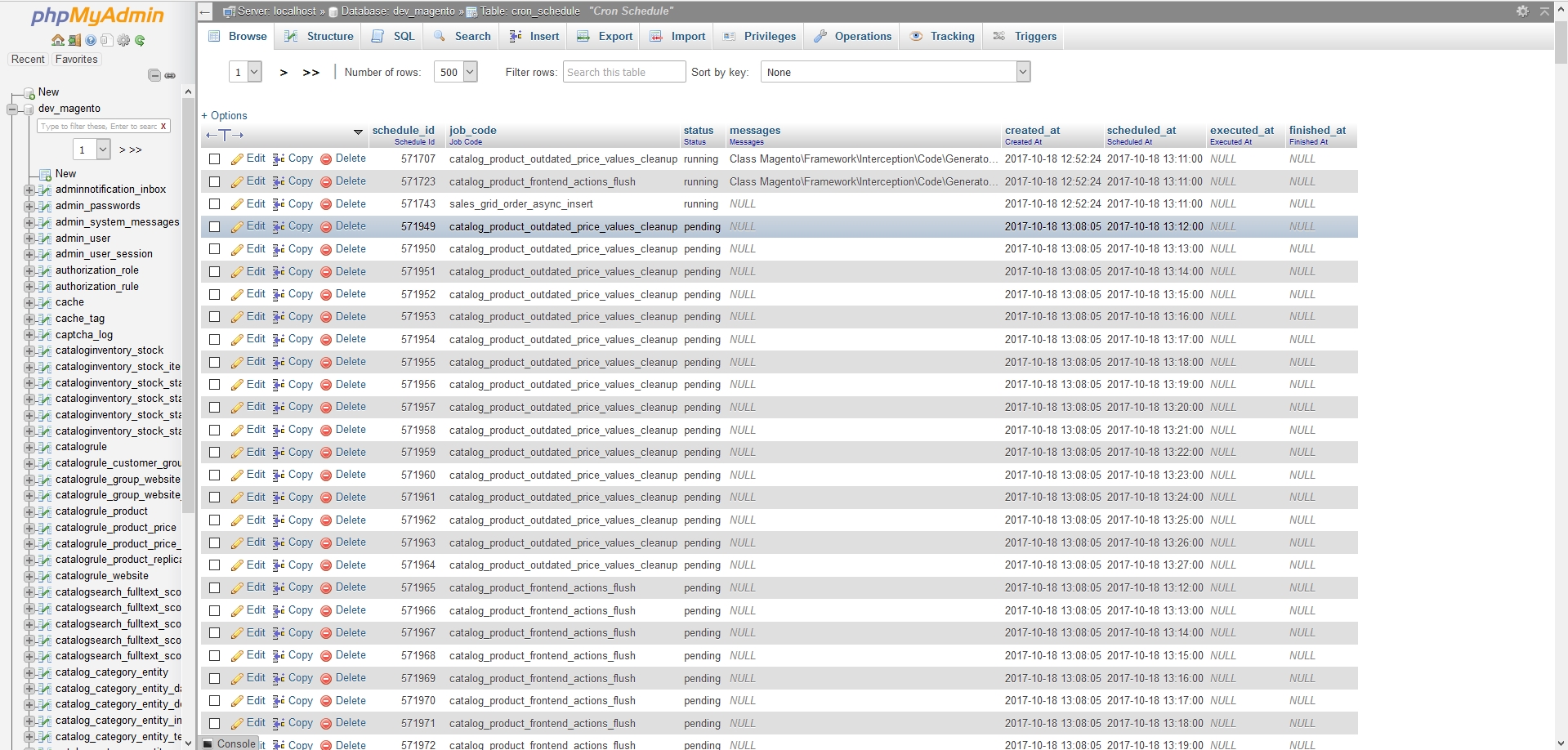 I deleted the first row of the table, that was in the running state, and on the next cron run, it cleared all the pending tasks for this stuck cron, however rising to the top of the table, 3 more stuck cron jobs the following day at midday.
I deleted the first row of the table, that was in the running state, and on the next cron run, it cleared all the pending tasks for this stuck cron, however rising to the top of the table, 3 more stuck cron jobs the following day at midday. hostep
hostep akellberg-zz
akellberg-zz Krapulat
Krapulat andrewhowdencom
andrewhowdencom fooman
fooman SpartakusMd
SpartakusMd TandyCorp
TandyCorp Ylmzef
Ylmzef msieprawski
msieprawski
 simonmaass
simonmaass skukla
skukla ryantfowler
ryantfowler
 agata-maksymiuk
agata-maksymiuk Valentyn-Kubrak
Valentyn-Kubrak mattdillon100
mattdillon100 amitbdigitalaptech
amitbdigitalaptech Linek
Linek DigitalStartupUK
DigitalStartupUK Lasim
Lasim jontesamuelsson
jontesamuelsson Jean-PierreGassin
Jean-PierreGassin centminmod
centminmod ericvhileman
ericvhileman miguelbalparda
miguelbalparda gnuzealot
gnuzealot foxmasters
foxmasters erikhansen
erikhansen
 We would also see these errors during this time:
We would also see these errors during this time:

Preconditions
Steps to reproduce
Expected result
Actual result
The cronjob steadily increases in the time taken to complete, at the moment it is taking around 30 seconds to complete, during which time, mysql and php are taking up heavy CPU usage.
A MYSQL query log shows magento churning through all the pending requests, but they are never marked as success. Hence the ever increasing list of jobs to run.
Snippet from the Mysql Query log below