Open maicFir opened 2 years ago
深度优先遍历与广度优先遍历,不刷算法题不知道这两个概念,虽然平时业务也有写过这种场景,但是一遇到这两词就感觉高大上了
深度优先遍历
广度优先遍历
深度优先遍历就是当我们搜索一个树的分支时,遇到一个节点,我们会优先遍历它的子节点,直到最后根节点为止,最后再遍历兄弟节点,从兄弟子节点寻找它的子节点,直到搜索到最后结果,然后结束。
树
节点
首先我们从上面一段话中,我们知道遍历的对象是树,树是一种数据结构,我们在 js 中可以模拟它,具体我们画一个图 以上就是一个基本的树结构,在 js 中我们可以用以下结构去描述
const root = { name: '1', children: [ { name: '2-1', children: [ { name: '3-1', children: [ { name: '4-2', children: null }, { name: '4-1', children: null } ] }, { name: '3-2', children: null } ] }, { name: '2-2', children: null } ] };
我们理解上面那句话,深度优先遍历,就是当我搜索一个树分支,遇到一个节点,我就搜索她的子节点,直到搜索完了,再去搜索兄弟节点,我们用代码来验证一下
// 深度优先遍历 const deepDFS = (root, nodeList = []) => { if (root) { nodeList.push(root.name); // 递归root.children,找root的子节点 root.children && root.children.forEach((v) => deepDFS(v, nodeList)); } return nodeList; }; const result = deepDFS(root, []); console.log(JSON.stringify(result, null, 2)); /** [ "1", "2-1", "3-1", "4-2", "4-1", "3-2", "2-2" ] */
从结果上来看发现从最开始的分支,从第一个分支开始,找到一个节点就一直找到最深的那个节点为止,然后再找父级兄弟节点,最后再从根子节点的兄弟节点去寻找子节点。
搜索树分支时,从根节点开始,当访问子节点时,先遍历找到兄弟节点,再寻找对应自己的子节点
我们用一个图来还原一下搜索过程 对应的代码如下
// 广度优先遍历 const deepBFS = (root, nodeList = []) => { const queue = [root]; // 循环判断队列的长度是否大于0 while (queue.length > 0) { // 取出队列添加的节点 const p = queue.shift(); nodeList.push(p.name); // 根据节点是否含有children,如果有子节点则添加到队列中 p.children && p.children.forEach((v) => queue.push(v)); } return nodeList; }; console.time('BFS-start'); const result = deepBFS(root, []); console.log(JSON.stringify(result, null, 2)); console.timeEnd('BFS-start'); /* [ "1", "2-1", "2-2", "3-1", "3-2", "4-2", "4-1" ] */
广度优先遍历的主要思想是将一个树放到一个队列中,我们循环这个队列,判断该队列的长度是否大于 0,我们不断循环队列,shift出队列操作,然后判断节点children,循环children,然后将子节点添加到队列中,一旦队列的长度为 0,那么就终止循环了。
shift
children
我们测试一下两者哪种搜索时间效率更高
// BFS 广度优先遍历 console.time('BFS-start'); const result = deepBFS(root, []); console.log(JSON.stringify(result, null, 2)); console.timeEnd('BFS-start');
// DFS 深度优先遍历 console.time('DFS-start'); console.log(JSON.stringify(deepDFS(root, []), null, 2)); console.timeEnd('DFS-start');
最后发现 广度优先遍历的时间明显比深度优先的时间效率要高,广度优先遍历是用队列记录了每一个节点的位置,所以会占用内存更多点,由于深度优先遍历是从根节点往子节点依次递归查询,当子节点查询完了,就从根的节点的兄弟节点依次往下搜索,所以比较耗时,搜索效率上广度优先遍历更高。
1、理解深度优先遍历与广度优先遍历是什么
深度优先遍历就是从上到下,当我们搜索一个树时,我们从根开始,遇到一个节点,就先查询的它的子节点,如果子节点还有子节点就继续往下寻找直到最后没有为止,再从根子节点的兄弟节点开始依次向下寻找节点。
而广度优先遍历遍历就是从根节点开始,寻找子节点,先遍历寻找兄弟节点,依次从上往下,按层级依次搜索。
2、用具体代码实现深度优先遍历与广度优先遍历
3、深度优先遍历比广度优先遍历更耗时
4、本文示例代码 code example
什么是深度优先遍历
深度优先遍历就是当我们搜索一个树的分支时,遇到一个节点,我们会优先遍历它的子节点,直到最后根节点为止,最后再遍历兄弟节点,从兄弟子节点寻找它的子节点,直到搜索到最后结果,然后结束。首先我们从上面一段话中,我们知道遍历的对象是树,树是一种数据结构,我们在 js 中可以模拟它,具体我们画一个图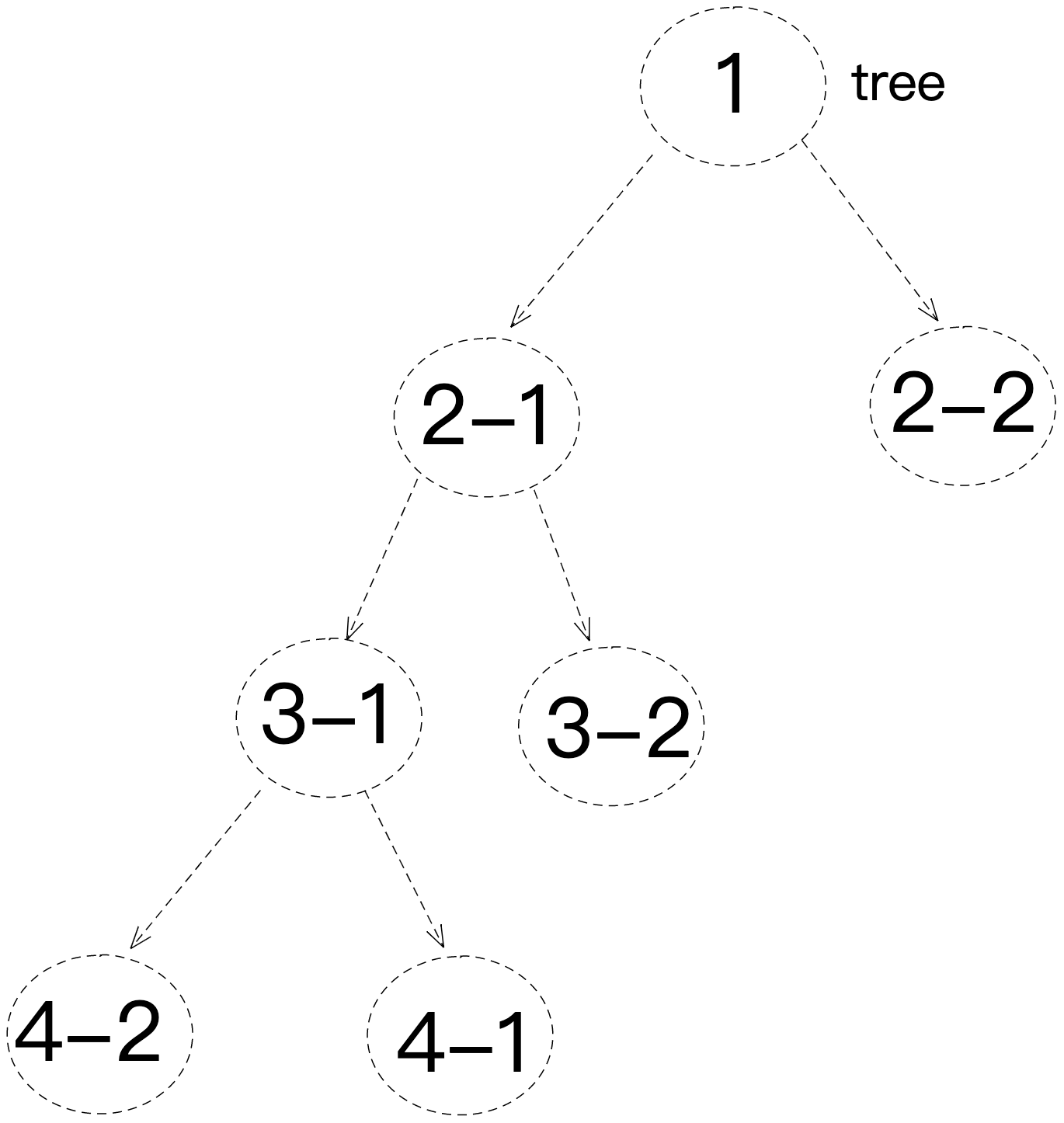 以上就是一个基本的树结构,在 js 中我们可以用以下结构去描述
以上就是一个基本的树结构,在 js 中我们可以用以下结构去描述
我们理解上面那句话,深度优先遍历,就是当我搜索一个树分支,遇到一个节点,我就搜索她的子节点,直到搜索完了,再去搜索兄弟节点,我们用代码来验证一下
从结果上来看发现从最开始的分支,从第一个分支开始,找到一个节点就一直找到最深的那个节点为止,然后再找父级兄弟节点,最后再从根子节点的兄弟节点去寻找子节点。
广度优先遍历
搜索树分支时,从根节点开始,当访问子节点时,先遍历找到兄弟节点,再寻找对应自己的子节点
我们用一个图来还原一下搜索过程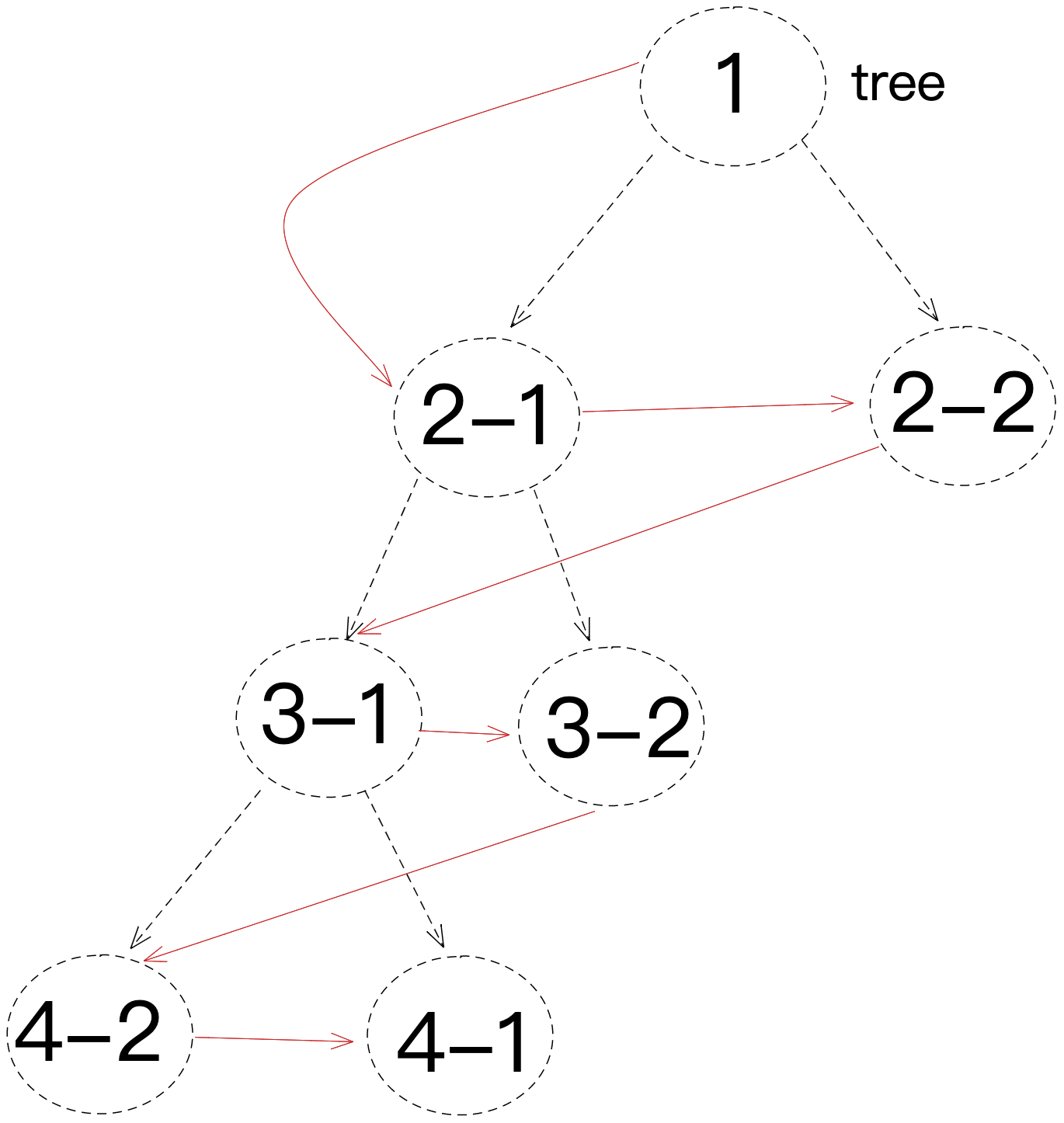 对应的代码如下
对应的代码如下
广度优先遍历的主要思想是将一个树放到一个队列中,我们循环这个队列,判断该队列的长度是否大于 0,我们不断循环队列,shift出队列操作,然后判断节点children,循环children,然后将子节点添加到队列中,一旦队列的长度为 0,那么就终止循环了。我们测试一下两者哪种搜索时间效率更高
最后发现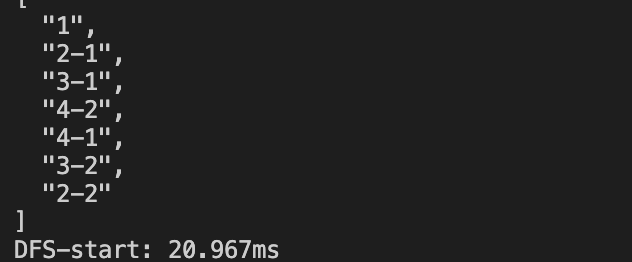
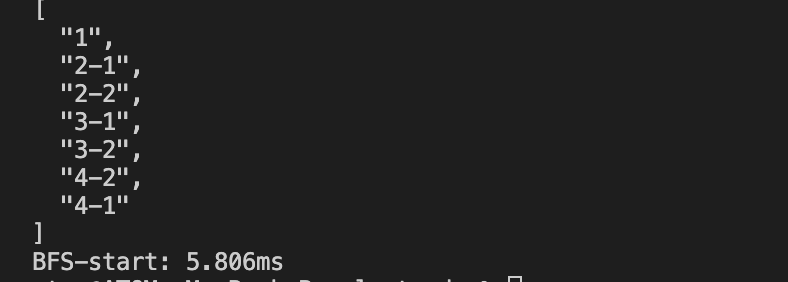 广度优先遍历的时间明显比深度优先的时间效率要高,广度优先遍历是用队列记录了每一个节点的位置,所以会占用内存更多点,由于深度优先遍历是从根节点往子节点依次递归查询,当子节点查询完了,就从根的节点的兄弟节点依次往下搜索,所以比较耗时,搜索效率上广度优先遍历更高。
广度优先遍历的时间明显比深度优先的时间效率要高,广度优先遍历是用队列记录了每一个节点的位置,所以会占用内存更多点,由于深度优先遍历是从根节点往子节点依次递归查询,当子节点查询完了,就从根的节点的兄弟节点依次往下搜索,所以比较耗时,搜索效率上广度优先遍历更高。
总结
1、理解
深度优先遍历与广度优先遍历是什么深度优先遍历就是从上到下,当我们搜索一个树时,我们从根开始,遇到一个节点,就先查询的它的子节点,如果子节点还有子节点就继续往下寻找直到最后没有为止,再从根子节点的兄弟节点开始依次向下寻找节点。而
广度优先遍历遍历就是从根节点开始,寻找子节点,先遍历寻找兄弟节点,依次从上往下,按层级依次搜索。2、用具体代码实现
深度优先遍历与广度优先遍历3、深度优先遍历比广度优先遍历更耗时
4、本文示例代码 code example