tinevez
commented
5 years ago
tinevez
commented
5 years ago Supersede and include
-
67
-
63
Closed tinevez closed 5 years ago
tinevez
commented
5 years ago Supersede and include
tinevez
commented
5 years ago The Travis job fails on Javadoc errors. Shall I fix them all?
This PR includes the new feature framework, that decouples the feature specifications and the feature storage themselves, as well as its use to generate a feature-based coloring scheme in TrackScheme.
Hi Tobias, So here is the changes I made to your experiments on the feature framework. I list here the changes I propose, grouped by category. Most of them relate to providing end-users with information and incremental updates.
Mamut-prefixed classes indicate classes that are specific to the Mastodon-app, that usesModelGraphwithSpots andLinks. Other classes are generic and work forVertexandEdgeinterfaces.A. Specify and provide the metadata of features.
1. Feature projection specs can have a multiplicity.
The multiplicity flag aims at addressing the fact that some projections may be defined per source. For instance the mean intensity has one projection per source. But we do not know how many sources we will get. So we flag these projections with a special value of the multiplicity to signal for that.
If a feature projection has a standard multiplicity (e.g. position) you don't have to worry about it. But for instance, here is what you do to define a feature with two series of projections, each per channel:
Let's focus on one:
(Ignore
Dimensionfor now.) With this you generate a single projection spec object that signal that there will be one projection per source, all prefixed withMEAN_PROJECTIONS_KEY(in this caseMean).In the feature computer, when you will need to generate and store the projection of the source number
iSource, or when you will need to get the feature projection key foriSource, you will do something like that:That way you can get and play with projection keys before knowing all the sources you have.
Multiplicity has 3 values, for standard projections, per source projections, and also for source pairs, unused yet.
2. Feature projection specs have a dimenson.
No big deal, I wanted to support units for quantities. Since the feature projection specs know nothing of the model, they cannot have units. But you can defined a dimension for the quantity they represent. Later, actual feature projections will turn this into a unit.
There is a
org.mastodon.feature.Dimensionenum that stores accepted dimensions, with utility methods.3. Feature projection have units.
The logical conclusion.
FeatureProjectionhas aunits()method that return a String.There is a method in the
Dimensionclass that can generate the units string automatically from the space and time units:... so to do this right we need....
4. The
Modelstores space and time units.I hope this will not make you cringe too much. There are two extra string fields into the
Modelobject that stores that. The two units are serialized with theModel. I stored them into theproject.xmlfile, as two XML elements.They are determined when the
Modelis created from theBDVobject, reading spatial and time units. Right now, BDV does not support time units, but we are ready to do so.When a project is loaded, the two strings are retrieved from the
project.xmlfile, and theModelinstance created with these. If we fail to load them, they are retrieved from the BDV file. If this still fails , by default they arepixelandframe.This forces us to declare v0.3 for the file format, but it is backward compatible with v0.2.
5. Feature specs provide more information to the user.
A feature spec provide an information text. Put it (e.g. HELP_STRING) in the constructor:
and the class has a
getInfo()method:This is exploited e.g. in the feature projection.
B. Filter feature computer by application.
I drilled a little bit into the
FeatureComputerService. I reasoned thatFeatureComputerServiceis the class that manages a collection ofFeatureComputers, and is in charge of facilitating feature calculation.We might have features that are defined only for a specific application, for instance the Mastodon-app which is based on the
ModelwithModelGraphobjects etc... The way we separateFeatureComputers from another application is with FCs that implement a specific interface. In our case that isMamutFeatureComputer, that has nothing special.So we also have a specific
MamutFeatureComputerServicefor the Mastodon-app, that only discoversMamutFeatureComputers. It inherits fromDefaultFeatureComputerService, which discovers all FCs, and implements the commonFeatureComputerServiceinterface.I think it works well this way. With the
FeatureSpecService, all features are discovered. But inside theMamutFeatureComputerService, only those that can be computed by aMamutFeatureComputerare considered and presented to the user.This also solves a problem I had with "manual" features: Features that are defined for
Spots andLinks but are not computed by a FC. For instance they might store the quality of a spot detection, or the cost of a link. They will not appear in the feature computation dialog, because a FC will not be found for them. And therefore, they won't be deleted after a feature computation request. But because they will be stored in theFeatureModel, they will appear in whatever uses features, like table, coloring etc.C. Facilities for feature computers.
Well of course we want to provide incremental updates to features, but first a digression:
1.
PropertyChangeListeneras dependency for FCs.The
DefaultFeatureComputerServicead inherited classes have aPropertyChangeListener(that does nothing by default). Interested FC can access it via the dependency mechanism, and us it to report computation progresses. For instance, you would put this in your FC code:and then:
Status events.
Progress event.
Clear status event.
2. Incremental updates for feature computers.
The Mamut features can subscribe to a object that will facilitate implementing incremental updates. That is: only recompute feature values for objects that have been modified since last time a computation was made.
A
GraphUpdateStackinstance will record graph changes between certain 'commits'.After features have been computed, a commit is made to the stack by the feature computer service. The commit stores the list of feature keys that have been computed. The stack can store a limited number of commits (10).
When needed, a
FeatureComputercan call thechangesFor( key )method, which will return an GraphUpdate object containing all the changes that happened in the graph since the last time the feature was computed. This object can be used to make an incremental computation of the feature. TheGraphUpdateobject is produced by concatenating all the GraphUpdates over all commits until the commit with the feature key is found. If aGraphUpdateobject cannot be produced (isnull, because e.g. the feature was never computed, or because the last commit with this feature was 'forgotten' by the stack), this signals that a full computation must be made.The updates have a certain locality. For instance you can ask for all the vertices that have been modified, and/or for all the edges of the spots that have been modified. There is just two
localityvaue now:SELF: You have been modified.NEIGHBOR: Your direct neighbor has been modified (edges of a vertex, source and target vertices of an edge).The
SpotGaussFilteredIntensityFeatureComputeruses it.3. Feature computer service is cancelable and feature computers can be cancelable.
You can cancel the feature computation process. If the current feature computer is cancelable, the cancel event will be forwarded to it.
Again the
SpotGaussFilteredIntensityFeatureComputeris cancelable.D. A settings page to edit color modes.
User-provided information about how to generate colors based on feature values is stored in a
FeatureColorModeclass, that can be serialized to YAML, and is managed like the BDVRenderSettingsand theTrackSchemeStyle.The mode editing panel resembles this: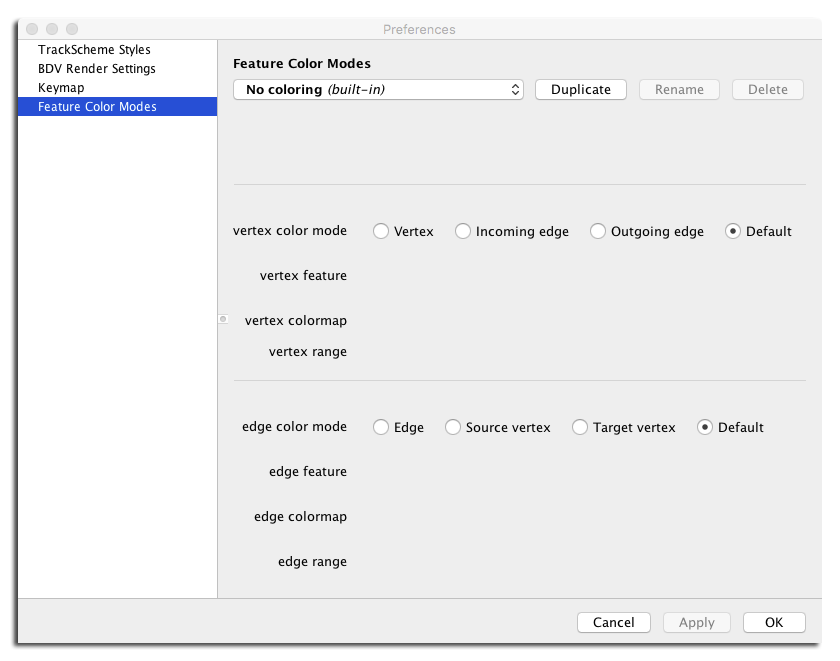
Classic case like coloring a vertex by a vertex feature is supported, but it is also possible to color and edge by a vertex feature and vice-versa: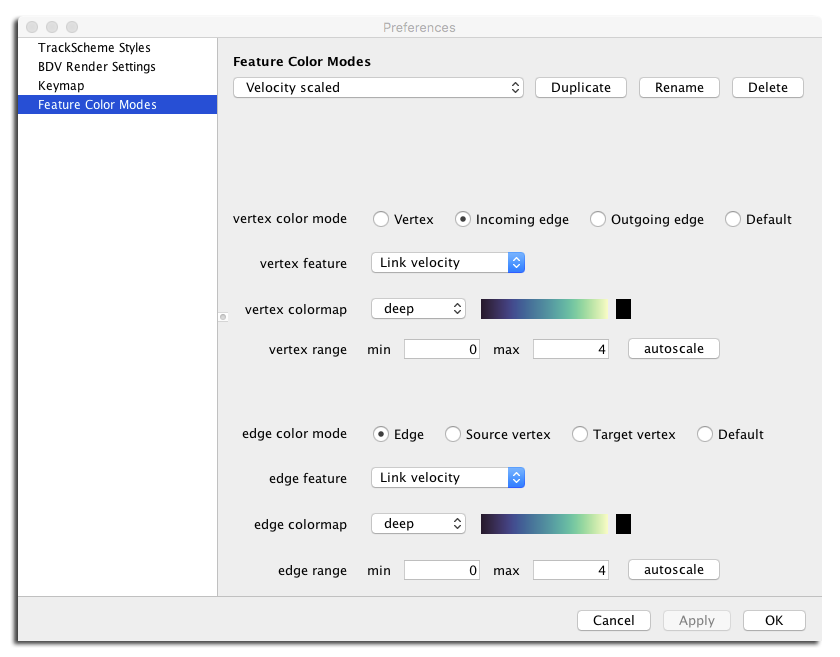
The editor looks like this on Windows platform: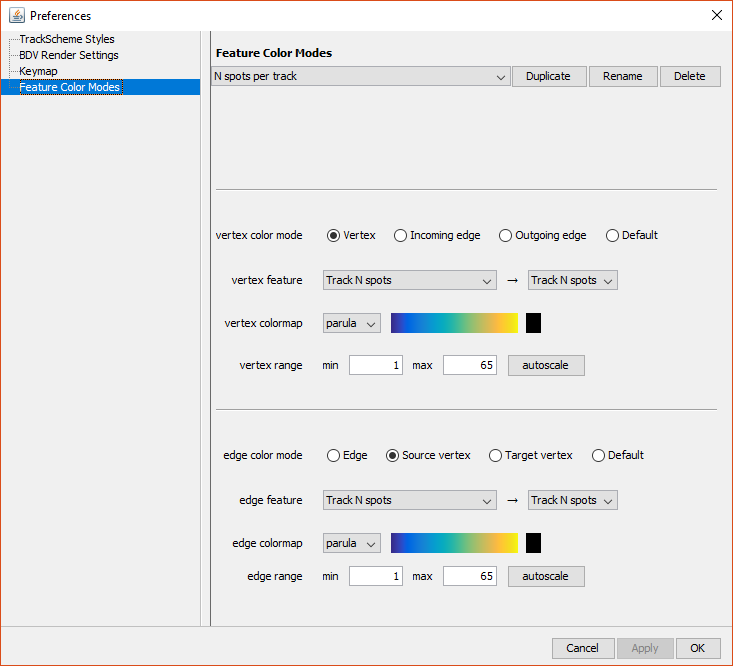
The color maps are represented by a
ColorMapclass, that can also be serialized to YAML. There is no editor for these colormaps, however it is possible to drop ImageJ LUT files in the~/.mastodon/lutsfolder:The coloring is based on the feature projections (scalar, double values) of a feature. The editor panel lets the user pick a pair of feature and projection keys: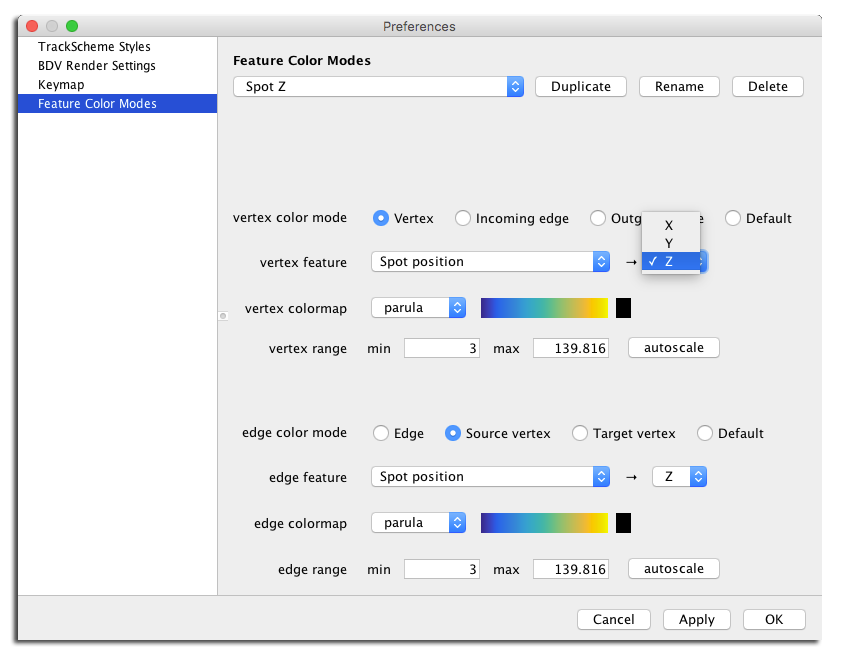
Finally, the validity of a color mode depends on the feature to be calculated. It is possible and even common to have a color mode pointing to features that are not registered in the feature model. We want to let the user edits such modes, but we warn them that the related features need to be computed before use in a view: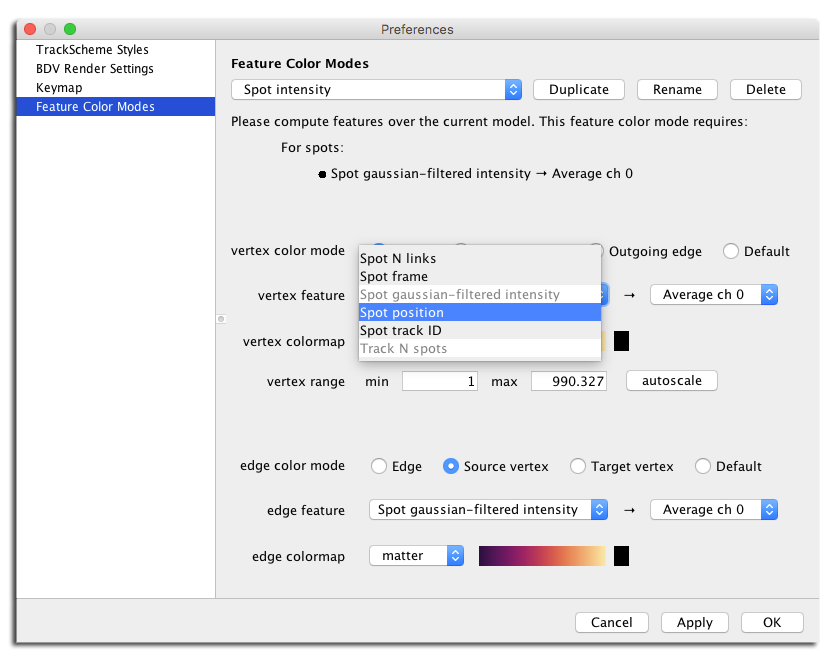
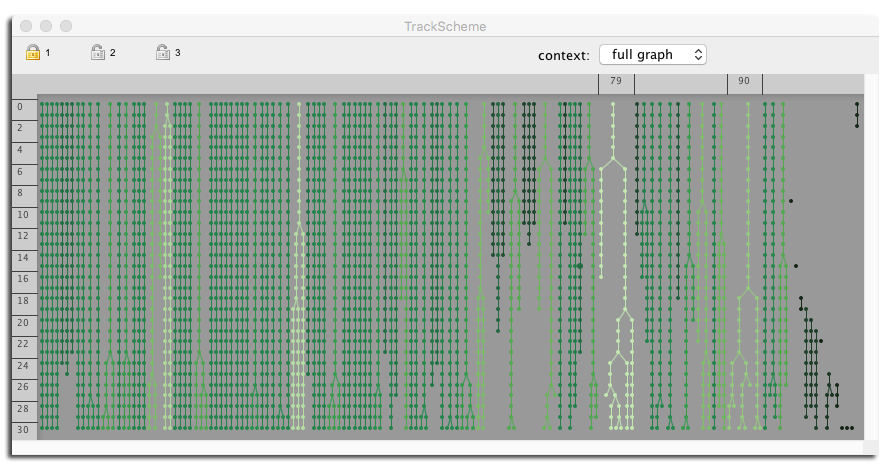
TrackScheme coloring.
The TrackScheme coloring menu now includes feature-based color modes. The color modes that are invalid (depending on feature that are not yet computed) appear disabled in the menu: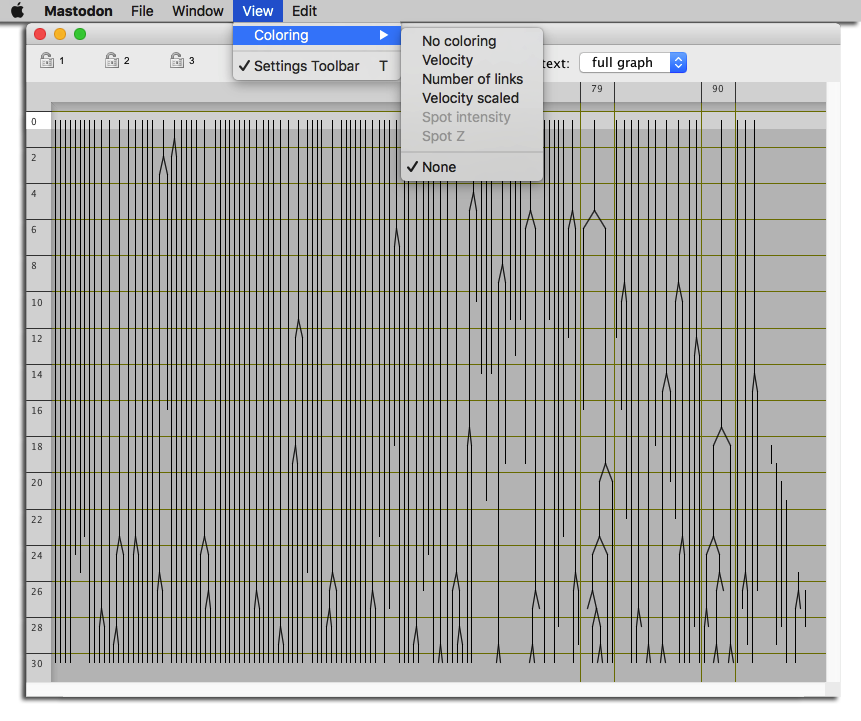
It looks like this on Windows platform: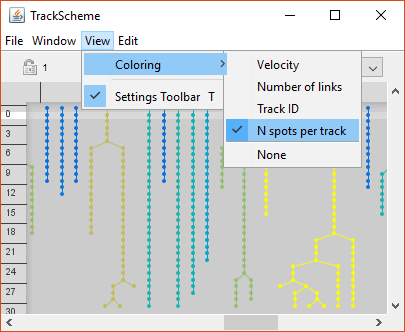
Here is an example: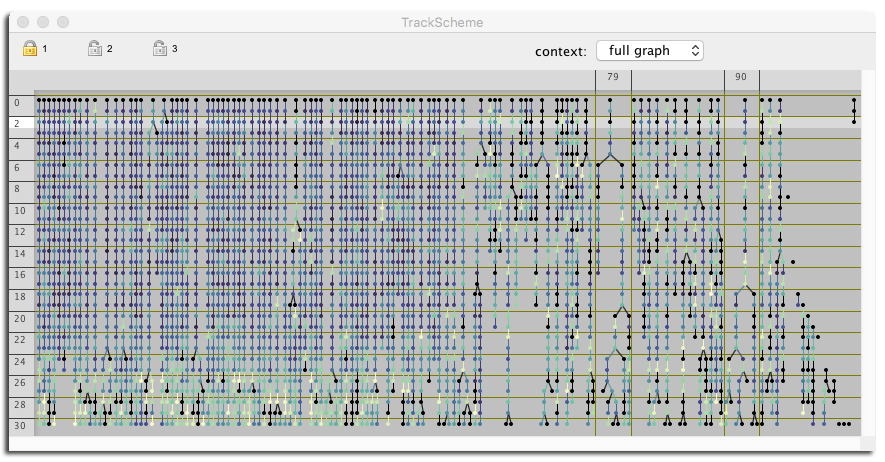
Another example for a track feature: all the spots of a track have the same feature values, ergo the same color: