 XuehaiPan
commented
5 months ago
XuehaiPan
commented
5 months ago I find the reason: metaOptimizer not detach the gradient link in optimizer. and former tensor was not release by torch due to dependency.
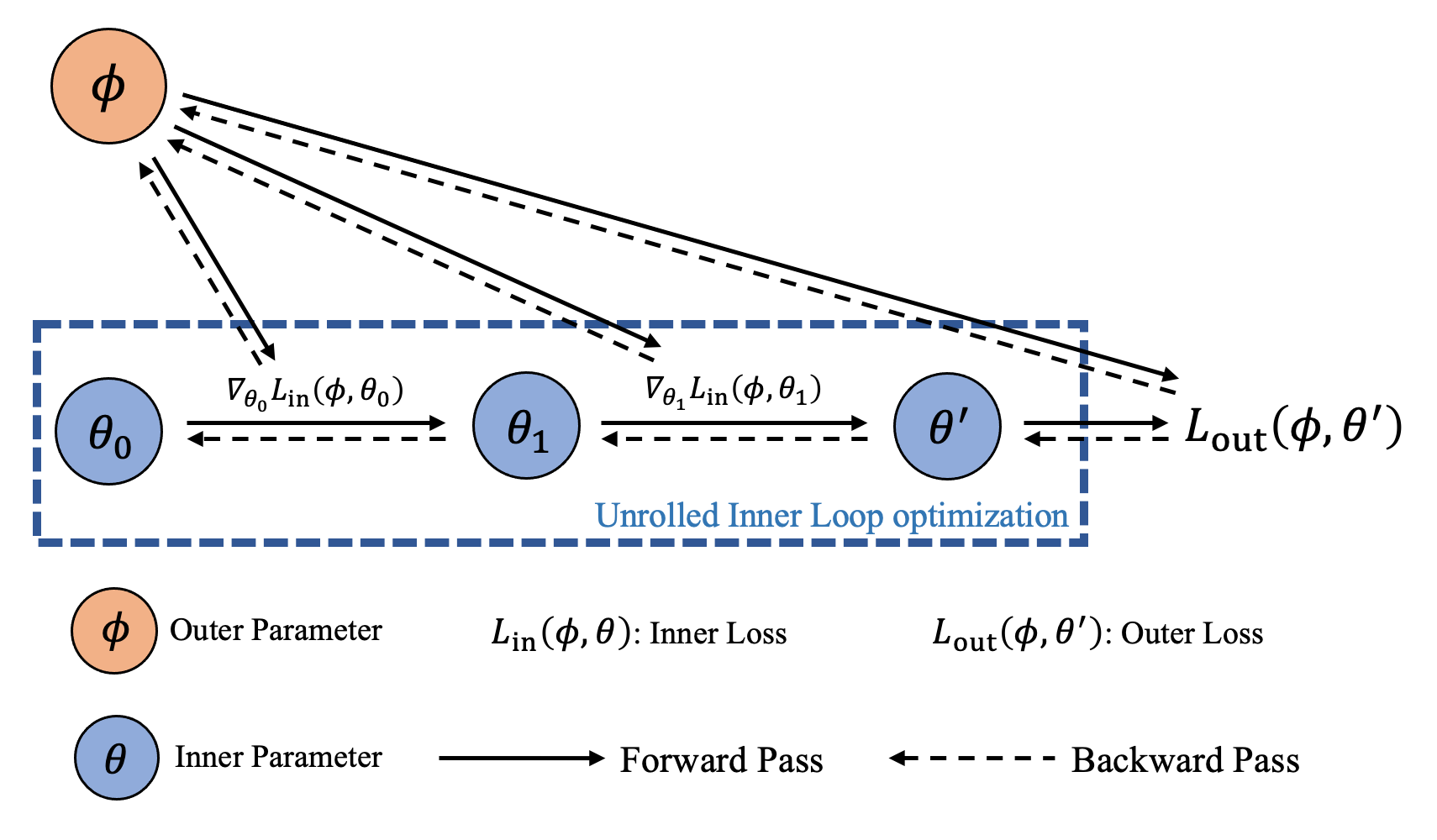
Hi @ycsos, this is intentional and it is the mechanism behind the explicit hyper-gradient.
when use torchopt.MetaAdam and step some times, the memory use in gpu are continuously increase.
You should not detach the computation graph in the inner loop. And you need to detach the graph in the outer loop using torchopt.stop_gradient. Refer to our tutorial for more detailed examples.
 ycsos
ycsos Benjamin-eecs
Benjamin-eecs
{kind=link}
Required prerequisites
What version of TorchOpt are you using?
0.7.3
System information
Problem description
when use torchopt.MetaAdam and step some times, the memory use in gpu are continuously increase. It should not be, will you excute next step, the tensor create in the former step is no need should be release. I find the reason: metaOptimizer not detach the gradient link in optimizer. and former tensor was not release by torch due to dependency.
you can run the test code, the first one memory increase by step increase. and second one (I change the code to detach the grad link) the memory is stable when step increase: before:
after:
Reproducible example code
The Python snippets:
Command lines:
Traceback
Expected behavior
Additional context
No response