 dreasysnail
commented
4 years ago
dreasysnail
commented
4 years ago Hi @xhlulu. This is a known issue that transformers tend to copy things. My suggestion would be that you can try either doing random generation with higher temperature, or adding a repetition penalty to the generation to explicitly penalize repeating the context.
 xhluca
xhluca pablonm3
pablonm3 saleemsum
saleemsum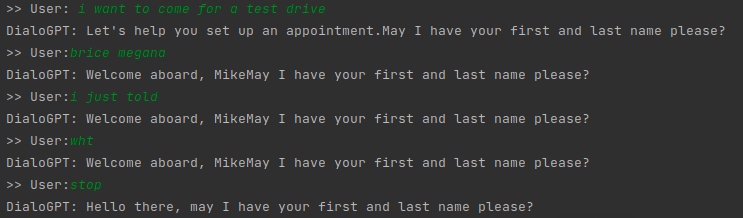
17-29-56](https://user-images.githubusercontent.com/100835253/167351438-02aca624-ae43-4aeb-b7fc-783a287afe3c.png)
 JayLee1002
JayLee1002

 Yamaxn
Yamaxn
I tried running the large model (in a colab notebook) using the approach described in the model card from the huggingface library:
Unfortunately, the output seems to quickly repeat the same sentence over and over again. In example 1 and 2, it repeats the same sentence from the beginning. In the 3rd case, the model starts fine, but as the conversation progresses, it starts repeating the same thing (or parts of it).
Is that an intended behavior?
Example 1
Example 2
Example 3