 wxchan
commented
7 years ago
wxchan
commented
7 years ago maybe you can use GroupKFold + ParameterGrid to simulate GridSearchCV. http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.ParameterGrid.html
btw, could you give a simple runnable case we can debug on? we might try make GridSearchCV work. thanks
 mandeldm
mandeldm julioasotodv
julioasotodv guolinke
guolinke Interstella12
Interstella12 bhaskar-c
bhaskar-c louisabraham
louisabraham seahrh
seahrh lbo34
lbo34 suissemaxx
suissemaxx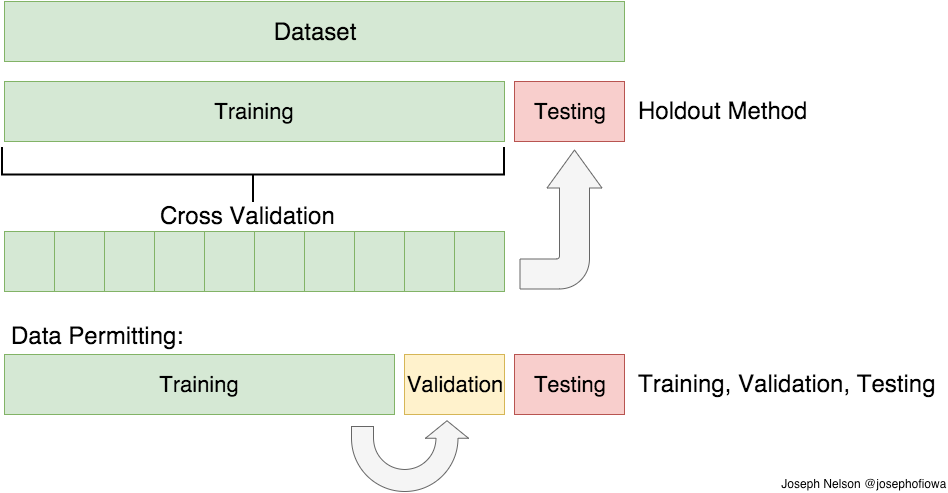{kind=link}
I'm using LGBMRegressor with sklearn.model_selection.GridSearchCV, with cross-validation split based on sklearn.model_selection.GroupKFold. When I include early_stopping_rounds=5 in the estimator, I get the following error:
ValueError: For early stopping, at least one dataset and eval metric is required for evaluation
Without the early_stopping_rounds argument the code runs fine.
I could be wrong, but it seems that LGBMRegressor does not view the
cvargument in GridSearchCV andgroupsargument in GridSearchCV.fit as a legitimate eval dataset.Is there a proper way to use early_stopping_rounds with GridSearchCV / GroupKFold?
Thank you.