 iofu728
commented
2 weeks ago
iofu728
commented
2 weeks ago Hi @SimJeg, thanks for your great question.
First, while RoPE is certainly related to the slash pattern, it is not the sole factor. The main reasons are as follows:
1) Even in BERT, a bidirectional encoder with absolute position encoding, some work observe the emergence of such slash sparse attention patterns[1].
Figure 1. The sparse pattern in BERT.
2) Our analysis of T5, an encoder-decoder model with learned relative position embeddings, also shows similar vertical and slash patterns.
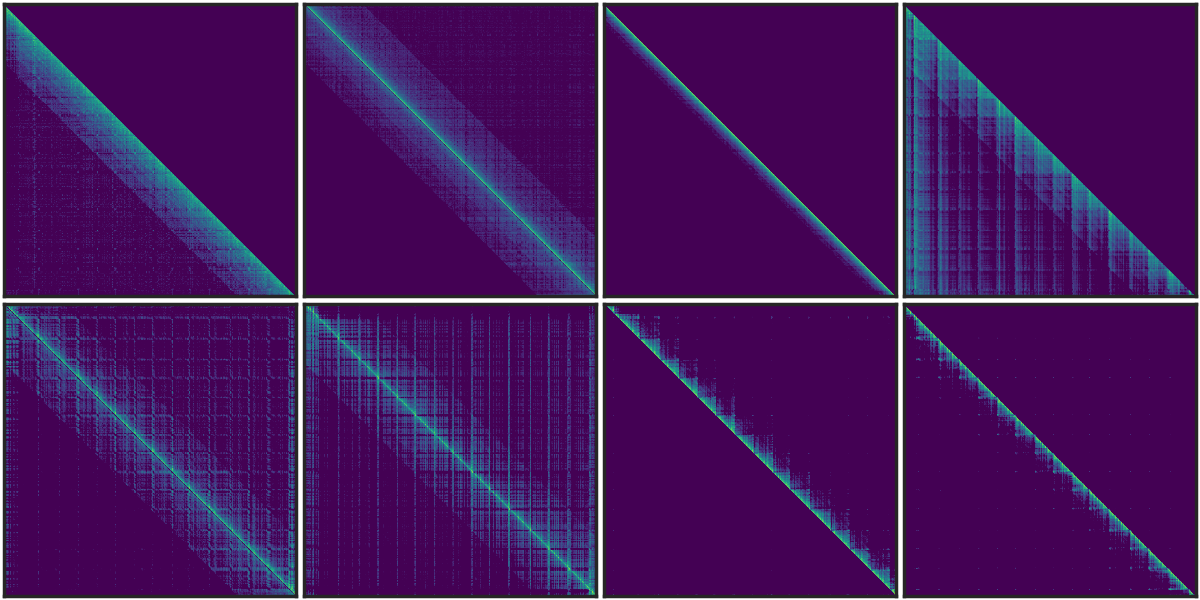
Figure 2. The sparse pattern in T5 Encoder using FLAN-UL2.
3) Recent research[2] has discovered similar sparse patterns in MLLMs, including LLaVA and InternVLM.
Figure 3. The sparse pattern in MLLM Encoder.
Regarding the intuition behind these patterns, we currently believe that these patterns represent some kind of information transmission channel, learned from world knowledge. However, this hypothesis requires further theoretical analysis for validation.
[1] SparseBERT: Rethinking the Importance Analysis in Self-Attention, ICML 2021.
[2] LOOK-M: Look-Once Optimization in KV Cache for Efficient Multimodal Long-Context Inference, 2024.
Describe the issue
Hello,
Vertical lines in attention correspond to "heavy hitters", tokens that are attended every time.
I don't really get what the intuition behind the off diagonal lines in the attention matrix. Is it only an "artifact" related to the periodicity of RoPE ? What is your understanding of this phenomenon ?