 edwardjhu
commented
1 year ago
edwardjhu
commented
1 year ago Hi shjwudp,
Thanks for your interest in our work!
Your coordinate check plots seem identical across time steps, which is a sign that the learning rate is too small for the function to change. Can you try rerunning with a larger learning rate? It's possible that with a moderately larger learning rate, the muP run might blow up after a couple steps, in which case we can look into it further.
 shjwudp
shjwudp The same hyperparameters, 1.3B model and 2.7B model comparison:
The same hyperparameters, 1.3B model and 2.7B model comparison:  leenachennuru
leenachennuru
Hello, μP team! Very excited to see you open source your excellent work! I was looking to apply μP on our work, and on Megatron-DeepSpeed I modified the training script as suggested in the tutorial, set the infshape, reset parameters initialization, put on MuAdam, and got a coord_check that looked successful. But when we transfer the learning rate that performed well on the 350M GPT model to the large model 1.3B, we found that the 1.3B could not withstand such a large learning rate and eventually produced NaN.
I was wondering what details might not have been taken into account, or the conditions were not met, causing μTransfer to fail. How should I debug, or μTransfer just won't work under this condition?
The following is the experimental information.
350M -> 1.3B GPT model μTransfer training loss( tensorborad link ):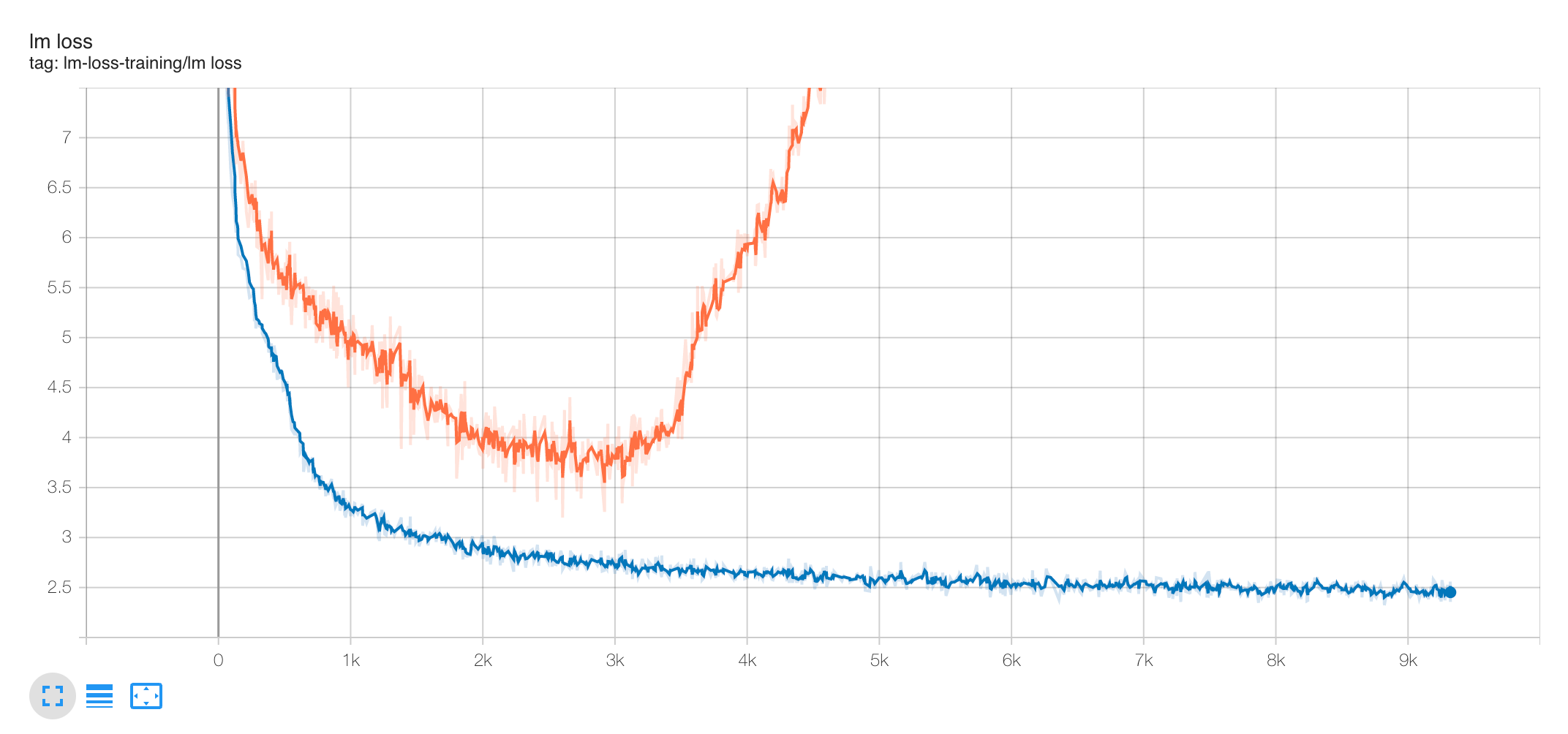
I think it may be a bit redundant, but if you are interested, the transformation of μP is here:
MuReadout._rescale_parametersoperation, https://github.com/shjwudp/Megatron-LM/blob/mup/megatron/mpu/layers.py#L191