 edwardjhu
commented
1 year ago
edwardjhu
commented
1 year ago Hi Zach,
Thanks your for your interest in muP!
A couple things come to mind.
- It might help to locate the layer with the very small activation norm and reason if it's expected.
- The range of width in your coord check plots seems pretty narrow. You can extend the range and see if the muP curves are still stable.
- The AUPRC curves seem a bit noisy. If they are from a single random seed, it might help to see if wider is better after averaging over more seeds.
Happy to look into it further if doing the above still doesn't resolve the issue.
 zanussbaum
zanussbaum shjwudp
shjwudp


 ndey96
ndey96
Hi all, attaching the coord check plots and also a screen shot of the train loss and auprc plots. I used the Conv1D from the branch, but have also tried
I was looking at the conv plots from the examples and I noticed that one of the layers is constant across width, but after the first step is significantly smaller. Is that an issue?
Mup plot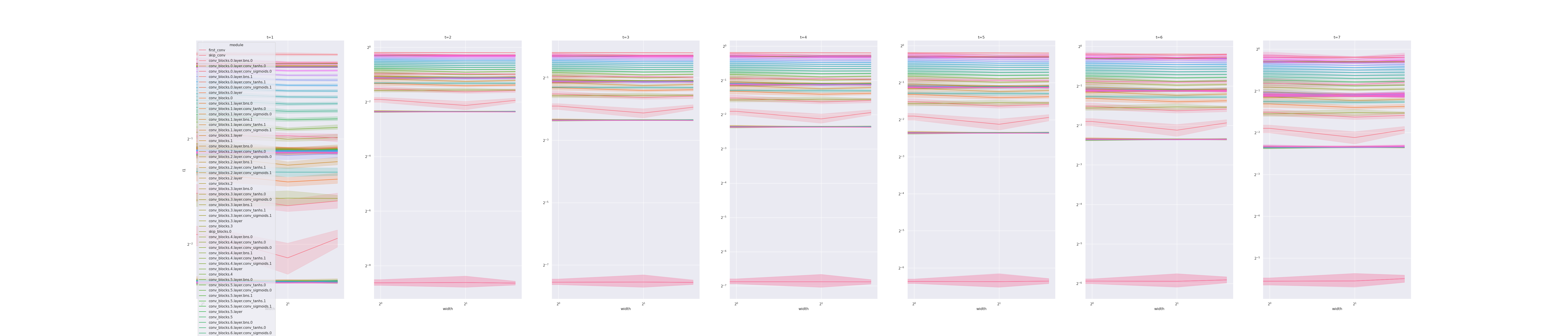
Sp Plot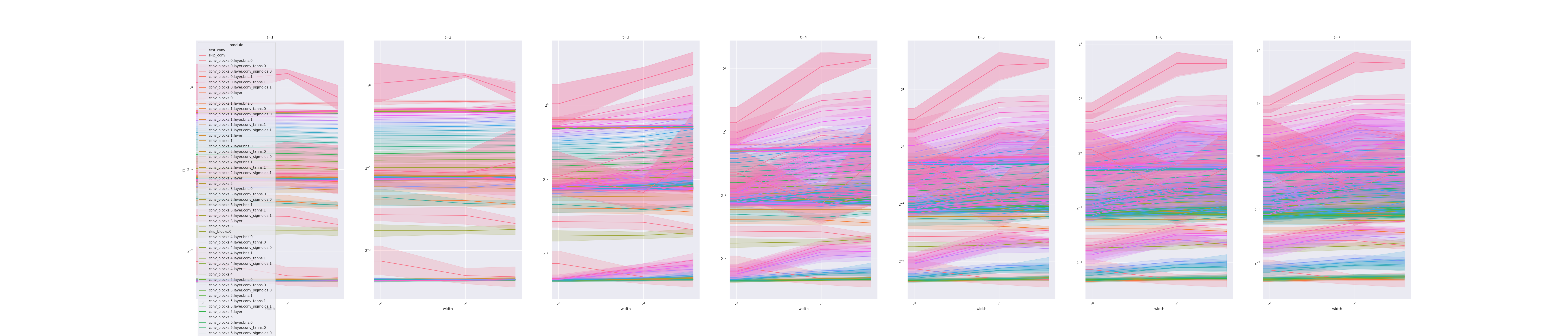
Train Loss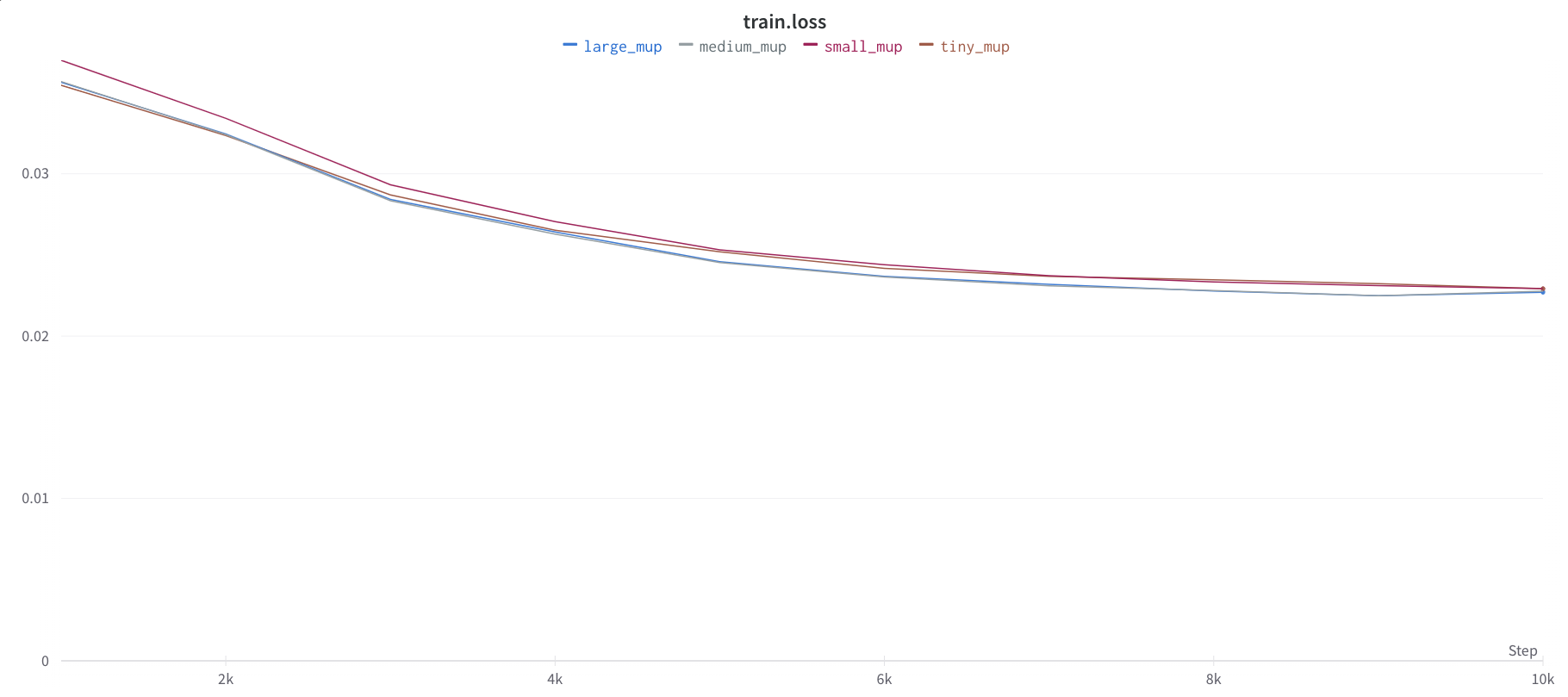
Train AUPRC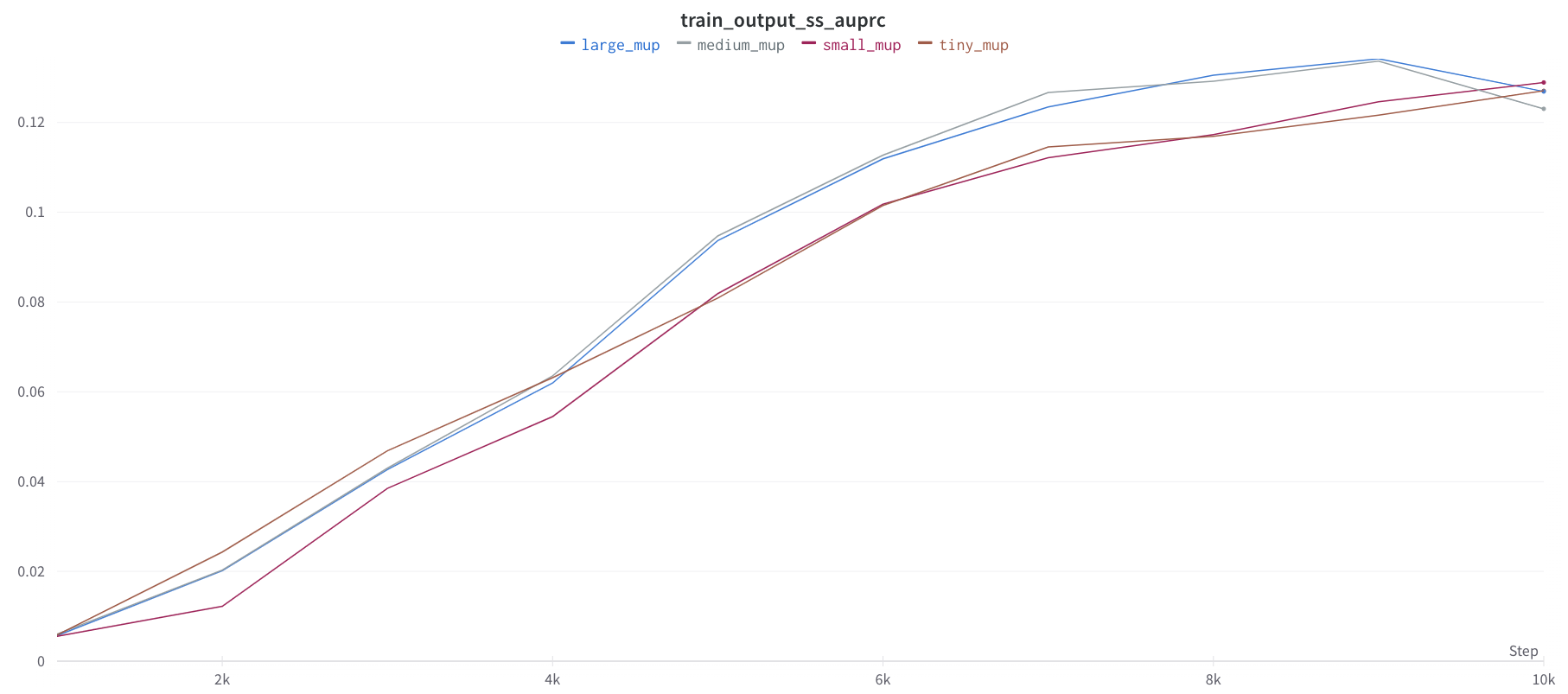
I also tried this with a transformer based model and found similar results where the transferred HPs did not result in better performance. I can regenerate those plots if needed.
Is this expected? What can I do to fix this? Having
mupwork would be a huge unlock for us :D