 tianleiwu
commented
2 years ago
tianleiwu
commented
2 years ago Based on my experience, I suggest to export FP32 ONNX model. Then use some tools to convert it to FP16 (or mixed precision) model. You will need config which part of the model computed in FP16, and other parts computed in FP32 to preserve enough accuracy.
An example conversion tool: https://github.com/microsoft/onnxconverter-common/blob/master/onnxconverter_common/float16.py
 SiChuanJay
SiChuanJay
 the onnx model of float16
the onnx model of float16

 I can get the model right, but the INT8 model is running much slower than float32's model on both CPU and GPU, I wonder why?
I can get the model right, but the INT8 model is running much slower than float32's model on both CPU and GPU, I wonder why? Alwin4Zhang
Alwin4Zhang Ki6an
Ki6an garymm
garymm thiagocrepaldi
thiagocrepaldi
Hello, When I try to export the PyTorch model as an ONNX model with accuracy of FLOAT16, in the ONNX structure diagram, the input is float16, but the output is still float32, as shown below, and an error is reported at runtime.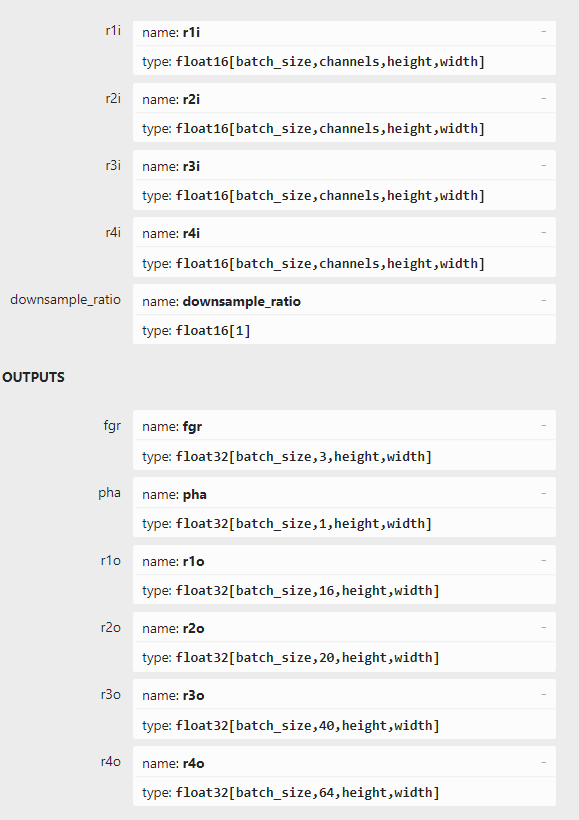
Thanks for your help!