 awni
commented
9 months ago
awni
commented
9 months ago @danilopeixoto I've been thinking about having this in MLX LM recently. Any interest in sending a PR?
It might make to do it after we have a more manageable config (https://github.com/ml-explore/mlx-examples/pull/503) but that should be landed soon!
 ivanfioravanti
ivanfioravanti N8python
N8python lin72h
lin72h kishoretvk
kishoretvk developerlin
developerlin
Introduce one Reinforcement Learning from Human Feedback (RLHF) example, such as Direct Preference Optimization (DPO) method.
Paper
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Notes
Direct Preference Optimization (DPO): A Simplified Explanation by João Lages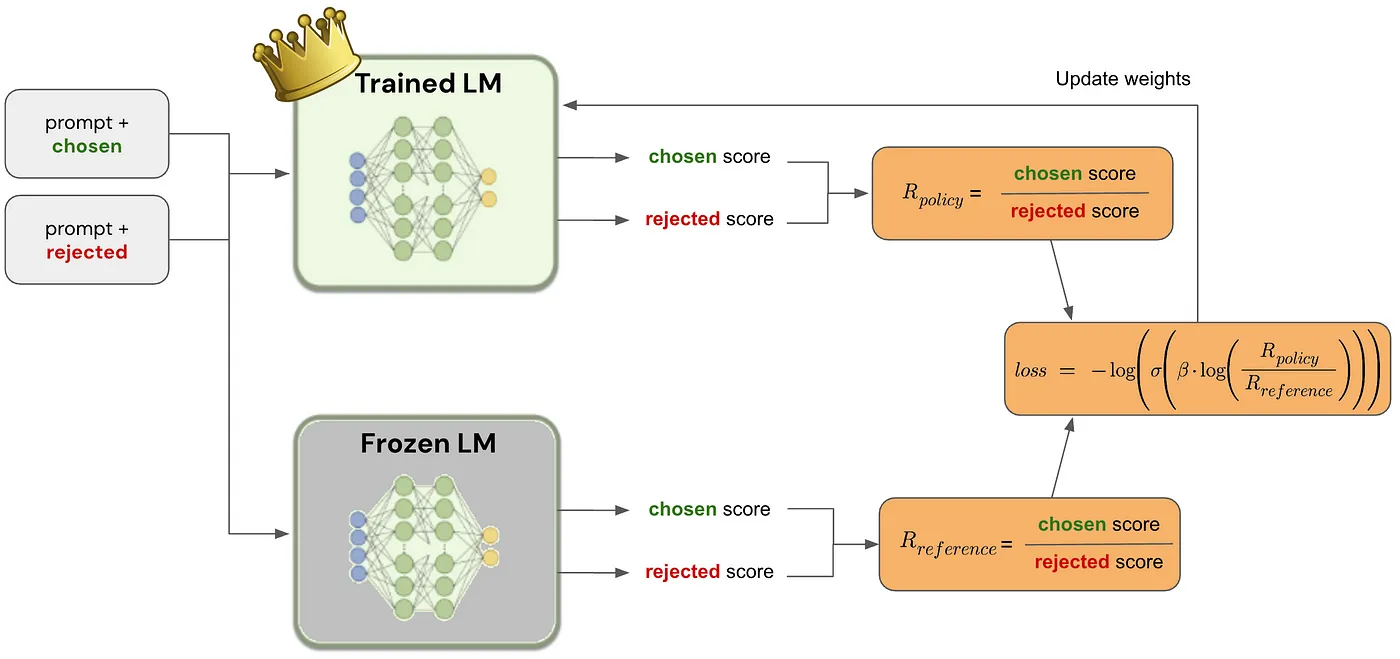
Implementation examples
Possible MLX implementation
Policy and reference log probabilities:
Loss:
Beta: The temperature parameter for the DPO loss is typically set in the range of 0.1 to 0.5. The reference model is ignored when
betaequals 0.Label smoothing: This parameter represents the conservativeness for DPO loss, assuming that preferences are noisy and can be flipped with a probability of
label_smoothing.