 erogol
commented
4 years ago
erogol
commented
4 years ago try without forward attention but location sensitive attention. 2nd one looks fine btw. Reopen if you need it.
Closed OswaldoBornemann closed 4 years ago
erogol
commented
4 years ago try without forward attention but location sensitive attention. 2nd one looks fine btw. Reopen if you need it.
 OswaldoBornemann
commented
4 years ago
OswaldoBornemann
commented
4 years ago @erogol But how could you successfully used forward attention with LJSpeech dataset ?
erogol
commented
4 years ago I don'rt remember how I trained it before but currently I sue it for inference only.
OswaldoBornemann
commented
4 years ago @erogol thanks a lot ! And happy new year ~
I am trying Tacotron2 based on LJSpeech dataset and try to reproduced the result that
erogoldid. But both two experiments did not work well, both of two seem to have high stop loss.The first experiment main config is below
The results are below
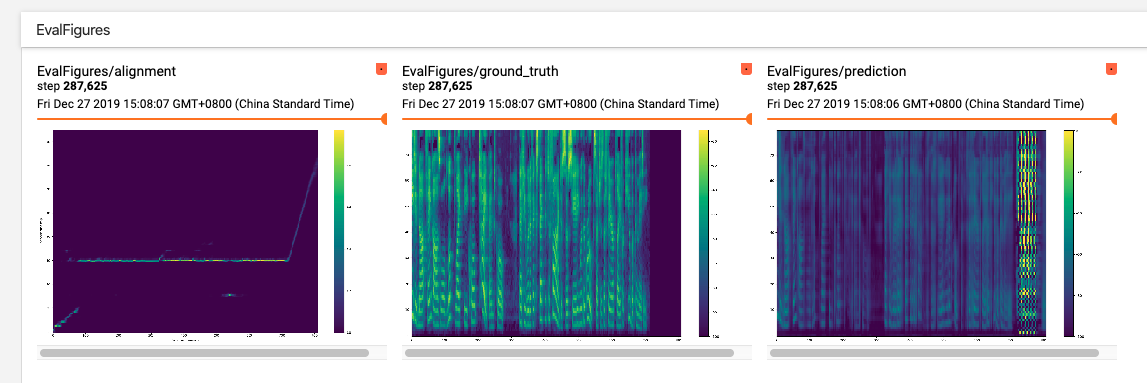
The second experiment main config is below
Both two experiments have been trained almost 10 days.