 mpip
commented
9 years ago
mpip
commented
9 years ago You are right. At the moment we try to figure out how good the OpenMP support of FFTW works. We have some problems with the scaling of threaded matrix transposition that is part of the FFTW guru interface. It seems like this step does not scale at all and we have to find a way to fix it.
 rainwoodman
rainwoodman LadaF
LadaF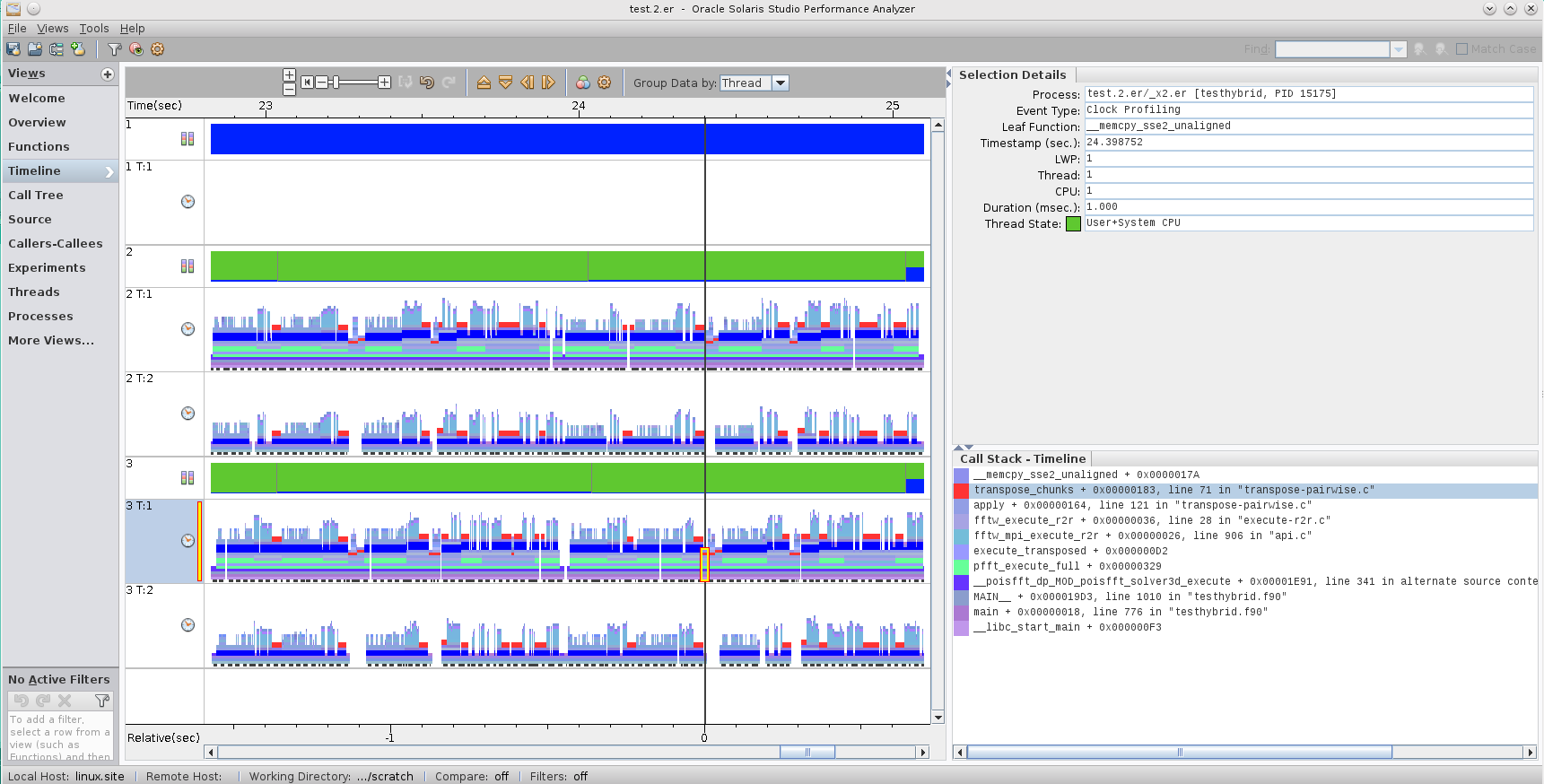
The next generation of Intel will have something like 70+ cores (Knight Landing); mass deployment to major computing facilities will be next year.
It may be a good case if PFFT can both scale out and scale in.