 mratsim
commented
4 years ago
mratsim
commented
4 years ago Some more readings:
-
A Unified Scheduler for Recursive and TaskDataflow Parallelism
http://www.cs.qub.ac.uk/~H.Vandierendonck/papers/PACT11_unified.pdf
-
Nabbit, Executing Dynamic Task Graph Using Work-Stealing
https://pdfs.semanticscholar.org/7c1d/5701d6f8f1a311b99e96f25c501ae70e7b58.pdf
-
Combining Dataflow programming with Polyhedral Optimization
Also it seems like Cholesky decomposition would be a good candidate to test dataflow dependencies
- It is cited in all dataflow papers i've read
- Lots of references
- Can nest optimized GEMM
- Can be reused as a baseline for the Lux compiler in laser






 StarPU and HPX to be checked.
StarPU and HPX to be checked.






From commits:
I am almost there to port a state-of-the-art BLAS to Weave and compete with OpenBLAS and MKL, however parallelizing 2 nested loops with read-after-writes dependencies causes issues.
Analysis
The current barrier is Master thread only and is only suitable for the root task
https://github.com/mratsim/weave/blob/7802daf62652754c4e0815e139842fe820600870/weave/runtime.nim#L88-L96
Unfortunately in nested parallel loops normal workers could also reach it and will not be stopped and they will create more tasks or continue on their current one even though dependencies are not resolved.
Potential solutions
Extending the barrier
Extend the current barrier to work with worker threads in nested situations. An implementation of typical workload with nested barriers should be added to the bench suite to test behaviour in with a known testable workload.
Providing static loop scheduling
Providing static loop scheduling, by eagerly splitting the work may (?) prevent one thread running away creating tasks when their dependencies were not resolved. Need more thinking as I have trouble considering all the scenarios.
Create a waitable nested-for loops iterations
Weave already provides very-fine grained synchronization primitives with futures, we do not need to wait for threads but just for the iteration that does the packing work we depend on to. A potential syntax would be:
This would create a dummy future called
icForLoopthat could waited on by calls that are further nested.Unknowns:
Task graphs
While a couple of other frameworks are expressing such as task graphs:
The syntax of make_edge/precede is verbose, it doesn't seem to address the issues of fine-grained loop.
I believe it's better to express emerging dependencies via data dependencies, i.e. futures and waitable ranges
OpenMP tasks dependencies approach could be suitable and made cleaner, from OpenMP 4.5 doc: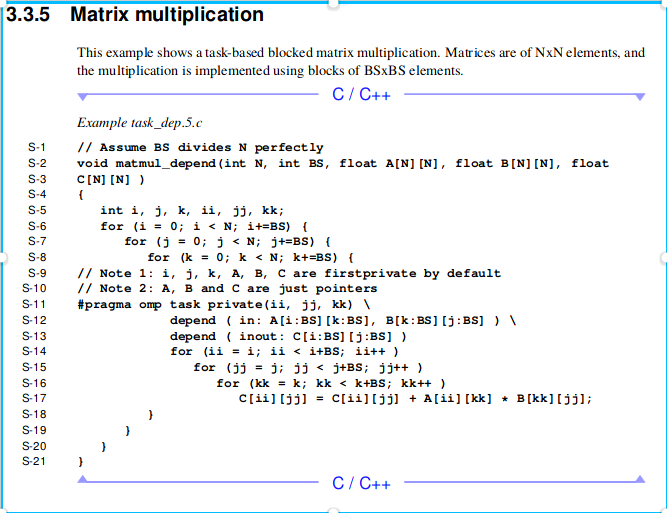
Or CppSs (, https://gitlab.com/szs/CppSs, https://www.thinkmind.org/download.php?articleid=infocomp_2013_2_30_10112, https://arxiv.org/abs/1502.07608)
Or Kaapi (https://tel.archives-ouvertes.fr/tel-01151787v1/document)
Create a polyhedral compiler
Well, the whole point of Weave is easing creating a linear algebra compiler so ...
Code explanation
The way the code is structured is the following (from BLIS paper [2]):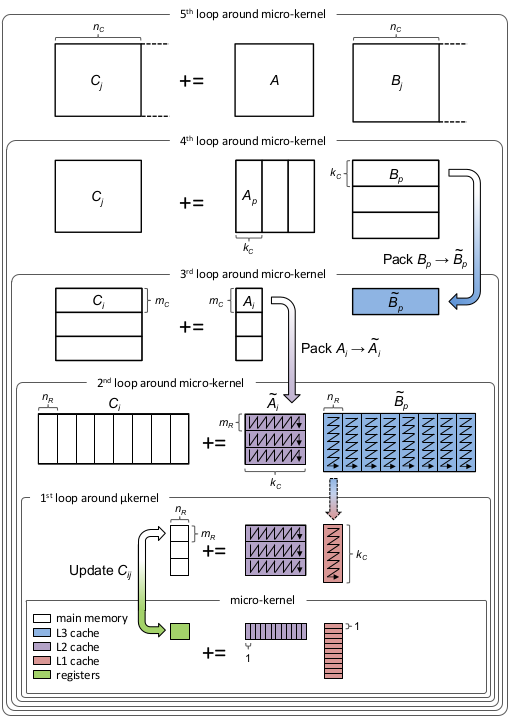
For MxN = MxK KN Assuming a shared memory arch with priavate L1-L2 cache per core and shared L3, Tiling for CPU caches and register blocking is done the following way:
mc*kc/(2mc+2kc) with mc*kc < KLoop: Difficult to parallelize
as K is the reduction dimension
so parallelizing K
requires handling conflicting writes
Normally parallelized but missing a way to express dependency or a worker barrier
References
[1] Anatomy of High-Performance Matrix Multiplication (Revised) Kazushige Goto, Robert A. Van de Geijn
http://www.cs.utexas.edu/~flame/pubs/GotoTOMS_revision.pdf
[2] Anatomy of High-Performance Many-Threaded Matrix Multiplication Smith et al
http://www.cs.utexas.edu/users/flame/pubs/blis3_ipdps14.pdf
[3] Automating the Last-Mile for High Performance Dense Linear Algebra Veras et al
https://arxiv.org/pdf/1611.08035.pdf
[4] GEMM: From Pure C to SSE Optimized Micro Kernels Michael Lehn
http://apfel.mathematik.uni-ulm.de/~lehn/sghpc/gemm/index.html
Laser wiki - GEMM optimization resources