 mrquincle
commented
4 years ago
mrquincle
commented
4 years ago In A Consistent Metric for Performance Evaluation of Multi-Object Filters, the authors introduce OSPA (optimal subpattern assignment) and argue that it is an improvement on OMAT (optimal mass transfer). Both methods are based on Wasserstein and address multi-object (tracking) problems. The first method is just the p-Wasserstein distance between two point clouds. The second method is also a p-Wasserstein distance, but it has a cut-off parameter, c. It assigns a maximum value to points that are left unassigned. Using this additional parameter the authors have a way to tradeoff localization errors with cardinality errors. By increasing c, cardinality errors receive a larger weight. By increasing the order parameter p, outliers are also penalized more (large weights become even more pronounced).
This adjusted metric is not what we need for establishing locality sensitivity. It establishes a way to cope with outlier points. It is not describing how to match a point cloud of 100 points with two point clouds of 50 points, where all of the point clouds are organized in spatially separated circles or squares. It is how hopeful though that additional properties are deemed important by the authors.
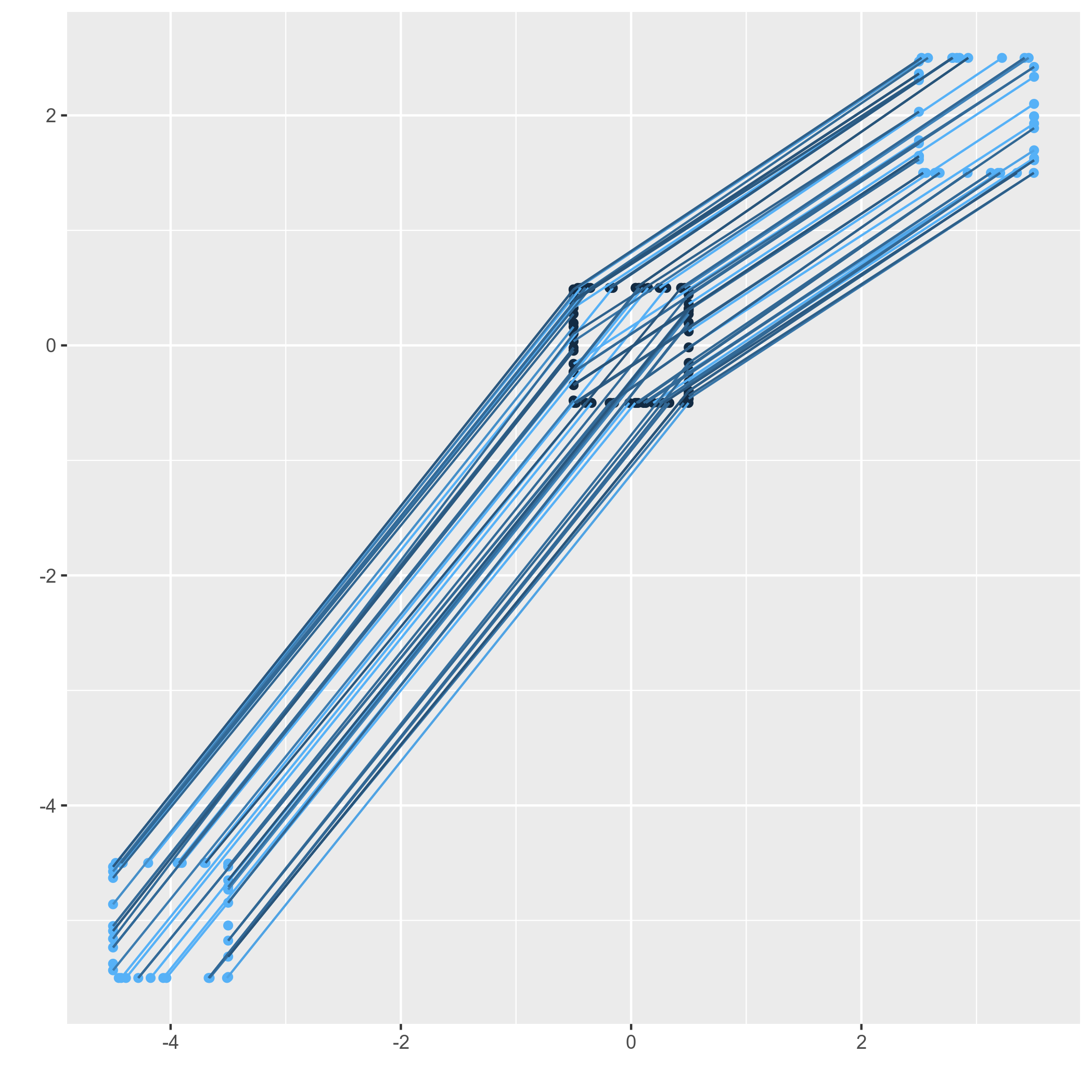
Earth mover's distance is limited to two distributions where there is no concern for internal structure. For example, if we would consider a car being moved from A to B with EMD, it would physically deconstruct the entire car and transfer them atom by atom. This is in contrast with the real world in which we would load the car on a truck move it in its entirety to its destination and unload it there.
This limitation of EMD is very visible when for example transferring points of a point cloud that makes up a circle "object" towards another circle "object". The points will be transferred according to a global distance metric. The "local neighborhood distance" between points is not preserved.
We need to find generalized EMD metrics that take into account local structure.