CBCのフレームワークはprobability tree diagram Tに基づいた確率モデルをもとにしている. Tree Tは初期エッジでクラスcの事前クラス確率P(c)となるsub-tree に分解することができる.
sub-treeをFig. 2に示す.
probability tree diagramは, 以下の5つの変数からなる.
[7] : C. Chen, O. Li, C. Tao, A. J. Barnett, J. Su, and C. Rudin. This looks like that: Deep learning
for interpretable image recognition. arXiv preprint arXiv:1806.10574, 2018.
[11] : I. Biederman. Recognition-by-components: A theory of human image understanding. Psychological review, 94(2):115, 1987.
[12] : J. Bromley, I. Guyon, Y. LeCun, E. Säckinger, and R. Shah. Signature verification using a
"Siamese" time delay neural network. In Advances in Neural Information Processing Systems,
pages 737–744, 1994.
[20] : K. Marino, R. Salakhutdinov, and A. Gupta. The more you know: Using knowledge graphs for
image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition, pages 2673–2681, 2017.
[21] : C. Jiang, H. Xu, X. Liang, and L. Lin. Hybrid knowledge routed modules for large-scale object detection. In Advances in Neural Information Processing Systems, pages 1559–1570, 2018.
[22] : X. Chen, L.-J. Li, L. Fei-Fei, and A. Gupta. Iterative visual reasoning beyond convolutions.
In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages
7239–7248, 2018.
[26] : S. Chopra, R. Hadsell, and Y. LeCun. Learning a similarity metric discriminatively, with
application to face verification. In Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition, pages 539–546, 2005.
[27] : R. Salakhutdinov and G. Hinton. Learning a nonlinear embedding by preserving class neighbourhood structure. In Artificial Intelligence and Statistics, pages 412–419, 2007.
[28] : G. Koch, R. Zemel, and R. Salakhutdinov. Siamese neural networks for one-shot image recognition. In International Conference on Machine Learning – Deep Learning Workshop, 2015.
[29] : T. Mensink, J. Verbeek, F. Perronnin, and G. Csurka. Metric learning for large scale image
classification: Generalizing to new classes at near-zero cost. In European Conference on Computer Vision, pages 488–501. Springer, 2012.
[30] : J. Snell, K. Swersky, and R. Zemel. Prototypical networks for few-shot learning. In Advances
in Neural Information Processing Systems, pages 4077–4087, 2017.
[31] : O. Li, H. Liu, C. Chen, and C. Rudin. Deep learning for case-based reasoning through prototypes: A neural network that explains its predictions. In Thirty-Second AAAI Conference on
Artificial Intelligence, 2018.
[32] : N. Papernot and P. McDaniel. Deep k-nearest neighbors: Towards confident, interpretable and robust deep learning. arXiv preprint arXiv:1803.04765, 2018.
[33] : H.-M. Yang, X.-Y. Zhang, F. Yin, and C.-L. Liu. Robust classification with convolutional
prototype learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition, pages 3474–3482, 2018.
[34] : T. Plötz and S. Roth. Neural nearest neighbors networks. In Advances in Neural Information
Processing Systems, pages 1093–1104, 2018.
[35] : S. O. Arik and T. Pfister. Attention-based prototypical learning towards interpretable, confident and robust deep neural networks. arXiv preprint arXiv:1902.06292, 2019.
[36] : O. Vinyals, C. Blundell, T. Lillicrap, K. Kavukcuoglu, and D. Wierstra. Matching networks for
one shot learning. In Advances in Neural Information Processing Systems, pages 3630–3638,
2016.
[37] : A. Santoro, S. Bartunov, M. Botvinick, D. Wierstra, and T. Lillicrap. Meta-learning with
memory-augmented neural networks. In International Conference on Machine Learning,
pages 1842–1850, 2016.
[38] : S. Gidaris and N. Komodakis. Dynamic few-shot visual learning without forgetting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4367–
4375, 2018.
[39] : L. Bertinetto, J. Valmadre, J. F. Henriques, A. Vedaldi, and P. H. S. Torr. Fully-convolutional
siamese networks for object tracking. In European Conference on Computer Vision, pages
850–865. Springer, 2016.
Classification-by-Components: Probabilistic Modeling of Reasoning over a Set of Components
Paper link : http://papers.nips.cc/paper/8546-classification-by-components-probabilistic-modeling-of-reasoning-over-a-set-of-components Author : Saralajew, Sascha and Holdijk, Lars and Rees, Maike and Asan, Ebubekir and Villmann, Thomas Conference : NeurIPS 2019 Code link : https://github.com/saralajew/cbc_networks
概要
分類問題の予測において推論ベースの説明性を与えるClassification-By-Components network (CBC)を提案した. CBCはBIEDERMAN’s theory [11] (人間は複雑な物体をcomponentと呼ばれる構造的に原始的で一般的なものに分解することで認識している)から着想を得た手法となっている.
以下でCBCの推論方法を説明する. ある物体からcomponentが抽出されたかどうかの情報 (extracted decomposition plan, extracted DP)と, 各クラスのcomponentの情報 (class Decomposition Plan,class DP)を照合することにより, 物体を分類する. class DPは特定のクラスの分類において, どのcomponentを検知することが重要であり, どのcomponentを検知しないことが重要でないかを決定する. 手書き文字の分類の例を示す (Fig. 1). ある画像について, あるcomponentsの検出を行い, 検出された場合”1”, 検出されなかった場合"0"とする (extracted decomposition plan, Fig. 1 : left). 次に各クラスでcomponentsでそのcomponentsがそのクラスの予測に肯定的か (positive)・否定的か (negative)・意味をなさないのか (indefinite)を決定する (class DP, Fig.1 : right). その後, 1とpositive, 0とnegativeのマッチングを行う (indefiniteはdon't careとして扱う) (Fig. 1 : middle). その結果をもとに分類を行う.
貢献
本論文の貢献はCBCと呼ばれる分類方法である. また, 次の4つの重要な性質がある.
2. The classification-by-components network
以下では, CBCのネットワークと訓練方法を述べる.
2.1 Reasoning over a set of full-size components
CBCのフレームワークはprobability tree diagram Tに基づいた確率モデルをもとにしている. Tree Tは初期エッジでクラスcの事前クラス確率P(c)となるsub-tree に分解することができる.
sub-treeをFig. 2に示す.
probability tree diagramは, 以下の5つの変数からなる.
に分解することができる.
sub-treeをFig. 2に示す.
probability tree diagramは, 以下の5つの変数からなる.
Extracting the decomposition plan
入力 と訓練可能なcomponents
と訓練可能なcomponents  とする.
初めに, 入力xであるcomponent
とする.
初めに, 入力xであるcomponent  が存在するかを検出する. 次に重み
が存在するかを検出する. 次に重み を持ち, 出力が
を持ち, 出力が&space;\in&space;\mathbb{R}^{m_x}) となる特徴抽出器
となる特徴抽出器=f(\bm{x};\bm{\theta})) を用いる. 特徴抽出器としてSiamese architecture 12を用いて入力と全componentsの特徴を抽出する.
その後, 検出確率関数
を用いる. 特徴抽出器としてSiamese architecture 12を用いて入力と全componentsの特徴を抽出する.
その後, 検出確率関数&space;=&space;d(f(\bm{x}),f(\bm{\bm{\kappa},\bm{x}}))&space;\in&space;[0,1]&space;~~(f(\bm{x})=f(\bm{\bm{\kappa},\bm{x}})~&space;implies&space;~d_k(\bm{x})=1)
) (例 : 二乗距離の負の指数関数)を計算する. 最後に, extracted DPに検出確率がベクトルとして収集される.
(例 : 二乗距離の負の指数関数)を計算する. 最後に, extracted DPに検出確率がベクトルとして収集される.
Modeling of the class decomposition plans
次に, 各クラス のclass DPについて議論する.
のclass DPについて議論する. ) を肯定的な推論,
を肯定的な推論, ) を否定的な推論,
を否定的な推論, ) を重要でない推論と定義する. これらは確率空間で形成され,
を重要でない推論と定義する. これらは確率空間で形成され,  を満たす. そして, class-wiseなベクトル
を満たす. そして, class-wiseなベクトル^T&space;\in&space;[0,1]^{\&hash;\mathcal{\kappa}}&space;~and&space;~\bm{r}_{c,k}^-~and~\bm{r}_{c,k}^0) として集められる.
として集められる.
Reasoning
あるクラスに属する確率を重要度の条件を考慮して計算する. agreement Aはtree T内でDとRもしくは,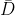 と
と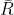 の経路である. Agreementな経路はFig. 2で棒線記されている.
の経路である. Agreementな経路はFig. 2で棒線記されている. ) をP(A|I,x,c)を用いて以下のように設定する.
をP(A|I,x,c)を用いて以下のように設定する.
 正しいクラスと最も可能性の高い異なるクラスとの間の確率の差分を損失とする.
正しいクラスと最も可能性の高い異なるクラスとの間の確率の差分を損失とする.
Training of a CBC
確率的勾配降下法を用いて以下のcontrastive lossを最小化する.
Extension to patch components
3. Related Work
Reasoning in neural networks
NNは既に推論に基づいて決定を下していると主張することができる. NNが多層パーセプトロンに完全に類似していると考えるならば, 各重みの符号は対応する特徴に対する否定的または肯定的な推論として解釈できる. ただし, ReLU関数を使用すると強制的に肯定的な推論のみになる.
Explicit modeling of reasoning
componentの利用および, negative・indefiniteな推論は, [7]の研究の拡張とみなすことができる. ただし, CBCは複雑な学習を必要としない. [18]では学習表現の一部を閉塞することにより不定の推論状態に類似した推論の形式が導入されている. ただしcomponentはテキスト形式となっている. 一般的に推論プロセスは[19]で述べられたアイデアやグラフ構造による知識のモデリング[20–22]とわずかに類似している.
Prototype-based classification rules and similarity learning
提案手法の重要な点は, 類似度を学習するSiamese architecture[12, 26-28]とPrototypeベースの分類規則をNNに組み込んだ [29-35]ということです (※prototypeと異なりcomponentはクラスに依存しない). [39]から, 類似性学習でprototypeをpatchに置き換えるという考え方も注目を集めている.
評価実験
MNISTおよび, IMAGENETでCBCを評価する. 検出確率関数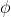 としてReLUとコサイン類似度を用いる.
としてReLUとコサイン類似度を用いる.
Fig. 4はMNISTで9つのcomponentを使用して推論を行なった図である.componentを用いて, ほとんどは肯定的な推論に基づいているが, 一部では否定的な推論を用いていることがわかる.
参考文献
[7] : C. Chen, O. Li, C. Tao, A. J. Barnett, J. Su, and C. Rudin. This looks like that: Deep learning for interpretable image recognition. arXiv preprint arXiv:1806.10574, 2018. [11] : I. Biederman. Recognition-by-components: A theory of human image understanding. Psychological review, 94(2):115, 1987. [12] : J. Bromley, I. Guyon, Y. LeCun, E. Säckinger, and R. Shah. Signature verification using a "Siamese" time delay neural network. In Advances in Neural Information Processing Systems, pages 737–744, 1994. [20] : K. Marino, R. Salakhutdinov, and A. Gupta. The more you know: Using knowledge graphs for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2673–2681, 2017. [21] : C. Jiang, H. Xu, X. Liang, and L. Lin. Hybrid knowledge routed modules for large-scale object detection. In Advances in Neural Information Processing Systems, pages 1559–1570, 2018. [22] : X. Chen, L.-J. Li, L. Fei-Fei, and A. Gupta. Iterative visual reasoning beyond convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7239–7248, 2018. [26] : S. Chopra, R. Hadsell, and Y. LeCun. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 539–546, 2005. [27] : R. Salakhutdinov and G. Hinton. Learning a nonlinear embedding by preserving class neighbourhood structure. In Artificial Intelligence and Statistics, pages 412–419, 2007. [28] : G. Koch, R. Zemel, and R. Salakhutdinov. Siamese neural networks for one-shot image recognition. In International Conference on Machine Learning – Deep Learning Workshop, 2015. [29] : T. Mensink, J. Verbeek, F. Perronnin, and G. Csurka. Metric learning for large scale image classification: Generalizing to new classes at near-zero cost. In European Conference on Computer Vision, pages 488–501. Springer, 2012. [30] : J. Snell, K. Swersky, and R. Zemel. Prototypical networks for few-shot learning. In Advances in Neural Information Processing Systems, pages 4077–4087, 2017. [31] : O. Li, H. Liu, C. Chen, and C. Rudin. Deep learning for case-based reasoning through prototypes: A neural network that explains its predictions. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018. [32] : N. Papernot and P. McDaniel. Deep k-nearest neighbors: Towards confident, interpretable and robust deep learning. arXiv preprint arXiv:1803.04765, 2018. [33] : H.-M. Yang, X.-Y. Zhang, F. Yin, and C.-L. Liu. Robust classification with convolutional prototype learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3474–3482, 2018. [34] : T. Plötz and S. Roth. Neural nearest neighbors networks. In Advances in Neural Information Processing Systems, pages 1093–1104, 2018. [35] : S. O. Arik and T. Pfister. Attention-based prototypical learning towards interpretable, confident and robust deep neural networks. arXiv preprint arXiv:1902.06292, 2019. [36] : O. Vinyals, C. Blundell, T. Lillicrap, K. Kavukcuoglu, and D. Wierstra. Matching networks for one shot learning. In Advances in Neural Information Processing Systems, pages 3630–3638, 2016. [37] : A. Santoro, S. Bartunov, M. Botvinick, D. Wierstra, and T. Lillicrap. Meta-learning with memory-augmented neural networks. In International Conference on Machine Learning, pages 1842–1850, 2016. [38] : S. Gidaris and N. Komodakis. Dynamic few-shot visual learning without forgetting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4367– 4375, 2018. [39] : L. Bertinetto, J. Valmadre, J. F. Henriques, A. Vedaldi, and P. H. S. Torr. Fully-convolutional siamese networks for object tracking. In European Conference on Computer Vision, pages 850–865. Springer, 2016.