 mwaskom
commented
8 years ago
mwaskom
commented
8 years ago As of v0.13, normalization is built directly into countplot:
sns.countplot(diamonds, x="cut", stat="percent") # or "proportion"
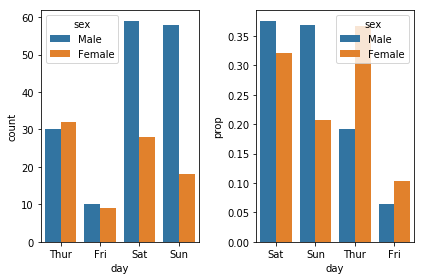
The recommendation is otherwise to use histplot, which has a flexible interface for normalizing the counts (see the stat parameter, along with common_norm), although its defaults are not identical to countplot so you'll need to be mindful of that. Here's an example:
sns.histplot(tips, x="day", hue="sex", stat="percent", multiple="dodge", shrink=.8)
Original answer (context for the rest of the thread):
This is already pretty easy to do with barplot, e.g.
import numpy as np
import pandas as pd
import seaborn as sns
df = pd.DataFrame(dict(x=np.random.poisson(4, 500)))
ax = sns.barplot(x="x", y="x", data=df, estimator=lambda x: len(x) / len(df) * 100)
ax.set(ylabel="Percent") hnykda
hnykda napsternxg
napsternxg beniz
beniz gandhis1
gandhis1 rselover
rselover joakimlustig
joakimlustig
 neutralrobot
neutralrobot turns into:
turns into:
 I compare this to ggplot in R:
I compare this to ggplot in R:
 emigre459
emigre459 ishant21
ishant21 danielkurniadi
danielkurniadi amueller
amueller
 gupta-rajat7
gupta-rajat7 Divjyot
Divjyot




Hello,
I would like to make a proposal - could we add an option to a countplot which would allow to instead displaying counts display percentages/frequencies? Thanks