 mycroes
commented
2 years ago
mycroes
commented
2 years ago I only looked at your message and comments for now, but again I'm very impressed. Will take a look at the rest soon, for now I haven't seen anything which would make me hesitant to merge this.
 scamille
scamille gfoidl
gfoidl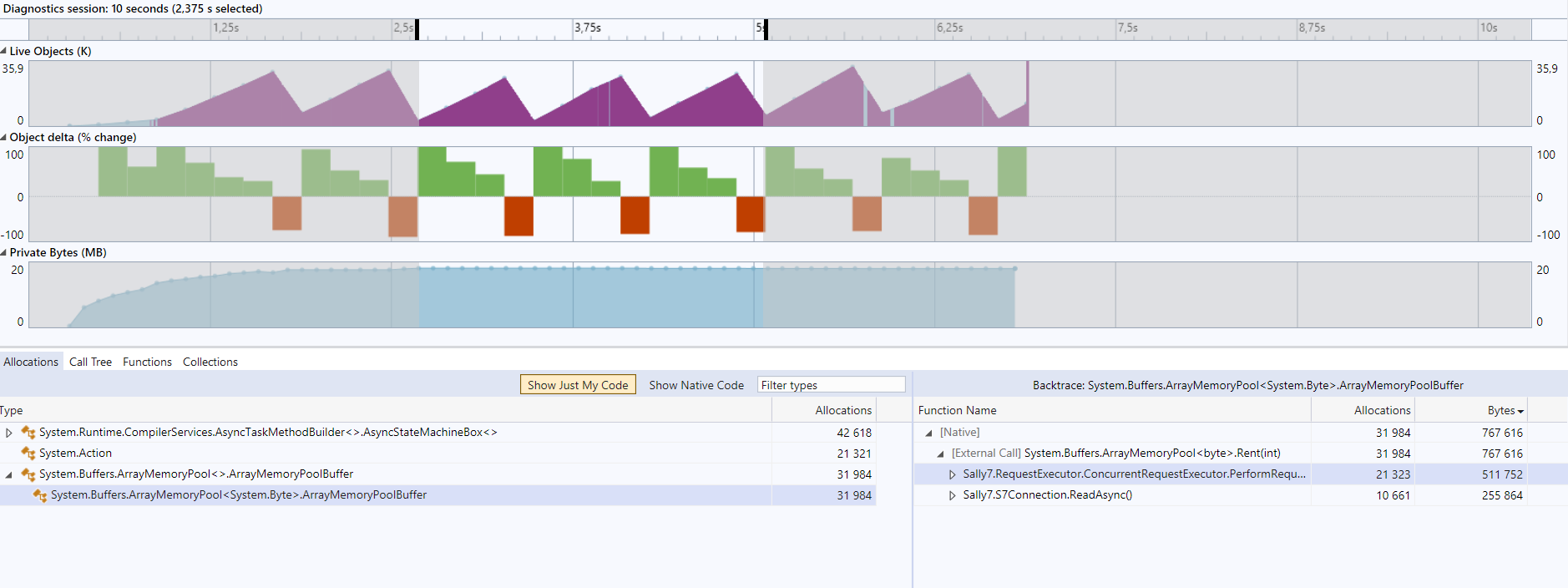{kind=link}
Description
Reading values from a PLC was run with a profiler, there some allocations appeared that could be avoided. This PR tries to reduce some of these allocations.
Some APIs needed for this are only available beginning with .NET 5, hence a new build-target was added.
Benchmarks
Benchmarks for reading from a SoftPLC
The PLC is run in virtual machine (https://github.com/fbarresi/SoftPlc docker), and simple short-values are read. Measured time isn't that accurate here (network latencies, etc.), and they are quite flaky, but my main point is reduction of allocations.
Baseline
Custom memory pool
As mentioned above a profiler showed allocations for the default (= shared) memory pool.
Before:
After: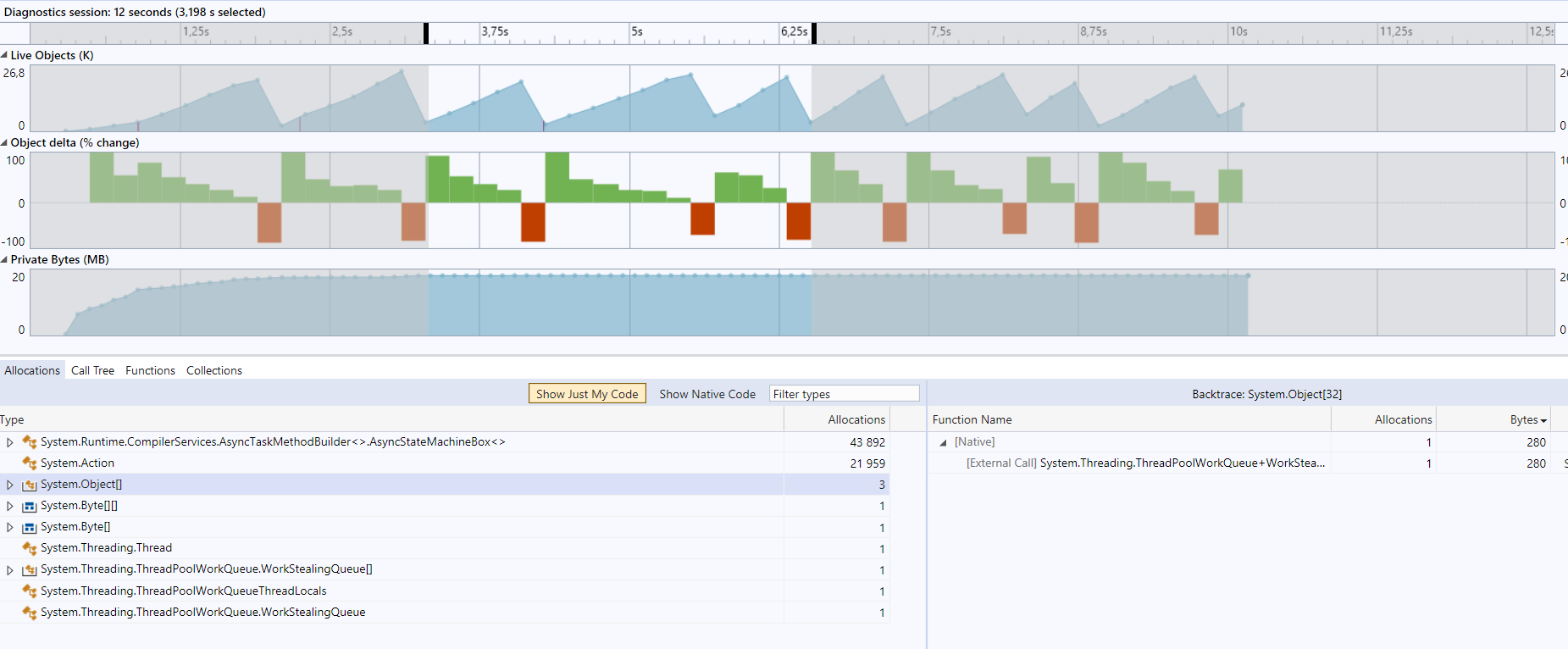
The custom memory pool is free, and pinning the memory needs to be done in the socket.
Sally7MemoryPoolhas the advantage over theArrayPool<byte>.Sharedthat the memories are created from already pinned arrays (on .NET 5 onwards only), so that pinning the MemoryFinal
Custom memory pool + ValueTask (VT) based socket operations (for > .NET Standard 2.1)
ActiontoAsyncStateMachineBox<>got better from 21.959 / 43.892 to 13.461 / 53.836 -- so less allocations for action-delegates are needed.As the code for .NET 5 and .NS 2.1 is quite different from the code for older runtimes (sometimes referred as "desktop"), two separate cs-files are created, and included via settings in the csproj-file, instead of using conditional compilation.
Note: the difference of 72 bytes to the previous step (custom memory pool) is exactly the size of a task (that is saved by the value task).
The VT based version tries to read as much from the socket, namely the
SocketTpktReader, so ideally can avoid some further reads, as all data is already there.Benchmarks for the custom memory pool
To demonstrate the benefit of the custom memory pool a bit further, a benchmark that "simulates" a socket operation. I.e. rent a memory from the pool, pin the memory (for the IO-operation), then unpin and return the memory to the pool.
For .NET 5.0, and newer, the arrays are allocated on the pinned object heap (POH). Hence pinning the memory is free (or at very little cost), whilst pinning a memory, where the backing array isn't pre-allocated, has quite a huge cost. That's the main reason for the 3x speedup.
Benchmark code
```c# using System; using System.Buffers; using BenchmarkDotNet.Attributes; using Sally7.Infrastructure; [MemoryDiagnoser] public class BenchMemoryPool { private const int Size = 967; private static readonly Sally7MemoryPool s_sally7MemoryPool = new(Size); [Benchmark(Baseline = true)] public void Default() { using IMemoryOwner