 DonaldTsang
commented
6 years ago
DonaldTsang
commented
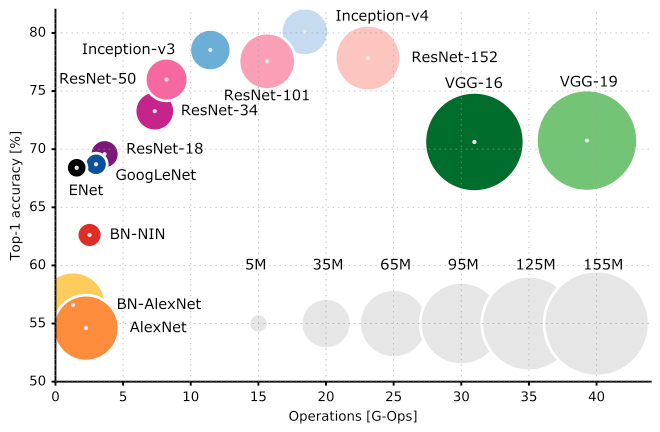
6 years ago - Is it possible to replace caffe (the slowest in the Python platform) with PyTorch (fastest overall) or MXNet (can beat PyTorch in parallel GPUs)
- Is it possible to replace VGG7 with Inception or ResNet, which out-performs VGG7?
 nagadomi
nagadomi 2ji3150
2ji3150
 yu45020
yu45020