 SanghyukChun
commented
7 months ago
SanghyukChun
commented
7 months ago I am not confident whether I understood your question correctly, but the code is for replacing the original keyword tokens with the projected text embeddings.
Namely,
caption = gray cat sleeps on a pillow
keyword masked caption = $ sleeps on $
replaced caption =
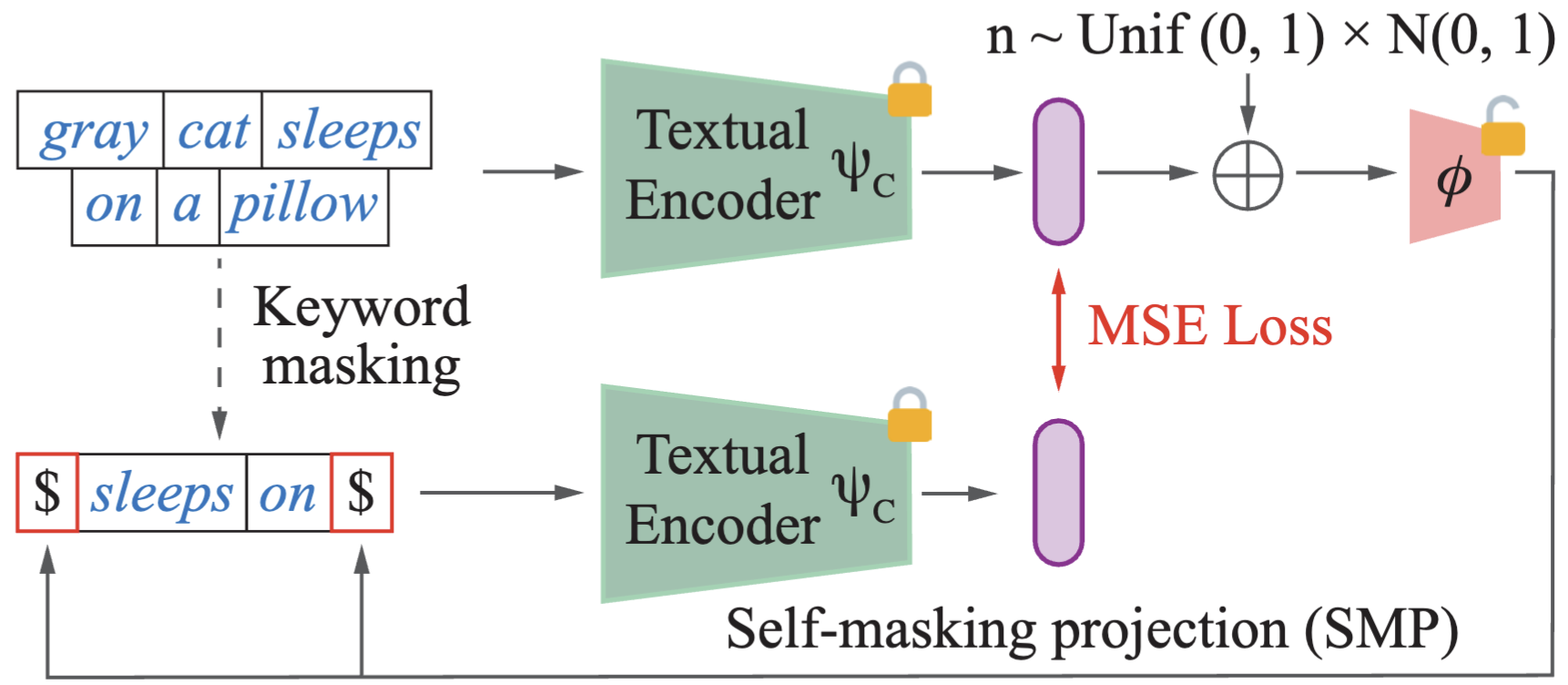
259 is the token index for $ (special token)
 Chenyan722
Chenyan722 Pefect96
Pefect96
Great work! In the line 32 of encode_with_pseudo_tokens.py, i.e., https://github.com/navervision/lincir/blob/6ffbdebb665878285afcb8f5263a1f8a44937ad4/encode_with_pseudo_tokens.py#L32. Why input the text embedding of the caption? and the dimension of pseudo_tokens is [bs, 768], while the dimension of x is [bs, 77, 768]. Thus, why input the embedding of the single pseudo_tokens to each position of mask with the same embedding? And then x will be input to the clip text emcoder. The logic seems to be incomprehensible. Looking forward to your reply!