 liufeng5200
commented
2 years ago
liufeng5200
commented
2 years ago 作者写的真不错,另外请问一下,训练好模型有吗
Open netpi opened 2 years ago
liufeng5200
commented
2 years ago 作者写的真不错,另外请问一下,训练好模型有吗
 netpi
commented
2 years ago
netpi
commented
2 years ago @liufeng5200 作者写的真不错,另外请问一下,训练好模型有吗
参考下 :https://colab.research.google.com/drive/1M4-dW3PXrr8BUynejLHiZIbIV7XdpN9I?usp=sharing 有个训练好的用来测试的小模型可以看看。
大模型,这两天整理下流程,传上去。
netpi
commented
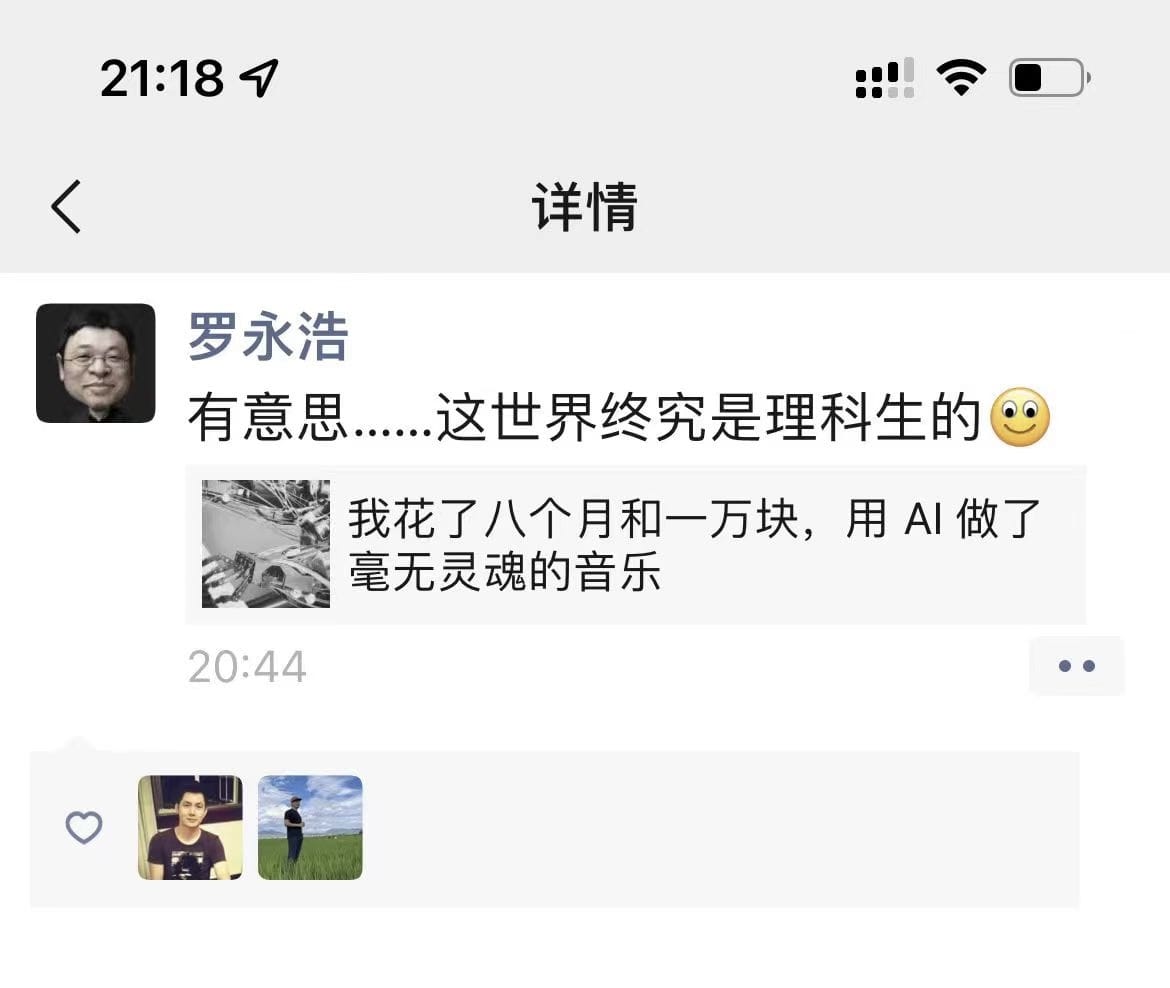
2 years ago 最近被果壳邀请撰稿,写了一个更加通俗的版本。
得到了一些反馈,罗永浩也转发了。
liufeng5200
commented
2 years ago @netpi
@liufeng5200 作者写的真不错,另外请问一下,训练好模型有吗
参考下 :https://colab.research.google.com/drive/1M4-dW3PXrr8BUynejLHiZIbIV7XdpN9I?usp=sharing 有个训练好的用来测试的小模型可以看看。
大模型,这两天整理下流程,传上去。
太好了,非常感谢!!!
 KQDtianxiaK
commented
2 years ago
KQDtianxiaK
commented
2 years ago 麻烦大佬可以解答下这个问题吗?实在是run不了[泪目]

netpi
commented
2 years ago @KQDtianxiaK
如果是 numpy 版本不同 (1.21.x),可以指定 dtype:
mt.train_step(np.array(seqs, dtype=np.int64))
KQDtianxiaK
commented
2 years ago @netpi
@KQDtianxiaK
如果是 numpy 版本不同 (1.21.x),可以指定 dtype:
mt.train_step(np.array(seqs, dtype=np.int64))多谢多谢,问题解决了
liufeng5200
commented
2 years ago @KQDtianxiaK 麻烦大佬可以解答下这个问题吗?实在是run不了[泪目]
我也遇到这个问题,我是把代码转了一下类型: def accuracy_function(real, pred): aa = tf.argmax(pred, axis=2) x = tf.cast(real, tf.int32) y = tf.cast(aa, tf.int32) accuracies = tf.equal(x, y) mask = tf.math.logical_not(tf.math.equal(real, 0)) accuracies = tf.math.logical_and(mask, accuracies)
accuracies = tf.cast(accuracies, dtype=tf.float32)
mask = tf.cast(mask, dtype=tf.float32)
return tf.reduce_sum(accuracies)/tf.reduce_sum(mask)真心希望作者能把训练好的模型放到百度网盘或github上。google要翻墙,下载不方便。
KQDtianxiaK
commented
2 years ago @liufeng5200
@KQDtianxiaK 麻烦大佬可以解答下这个问题吗?实在是run不了[泪目]
我也遇到这个问题,我是把代码转了一下类型: def accuracy_function(real, pred): aa = tf.argmax(pred, axis=2) x = tf.cast(real, tf.int32) y = tf.cast(aa, tf.int32) accuracies = tf.equal(x, y) mask = tf.math.logical_not(tf.math.equal(real, 0)) accuracies = tf.math.logical_and(mask, accuracies)
accuracies = tf.cast(accuracies, dtype=tf.float32) mask = tf.cast(mask, dtype=tf.float32) return tf.reduce_sum(accuracies)/tf.reduce_sum(mask)
 我是根据大佬的回答在这直接指定dtype
我是根据大佬的回答在这直接指定dtype
netpi
commented
2 years ago @liufeng5200 真心希望作者能把训练好的模型放到百度网盘或github上。google要翻墙,下载不方便。
可以先用这个模型 : ckpt28500
# 模型参数如下,其他按照 demo 就好
# [Family Bar/position Pitch Velocity Duration Chord Rest Tempo]
emb_sizes = [64, 256, 768, 256, 512, 256, 256, 256]后续我再整理传到 github,不过还是建议多用 Google,科学上网很重要呀 :)。
KQDtianxiaK
commented
2 years ago  大佬我又来了,跑了一个小时跑出来这个(:з」∠)
大佬我又来了,跑了一个小时跑出来这个(:з」∠)
netpi
commented
2 years ago @KQDtianxiaK
在指定位置手动创建一个 gen_midi 文件夹
KQDtianxiaK
commented
2 years ago @netpi
@KQDtianxiaK
在指定位置手动创建一个
gen_midi文件夹
麻烦大佬回复这么简单的问题了😓
liufeng5200
commented
2 years ago @netpi
@liufeng5200 真心希望作者能把训练好的模型放到百度网盘或github上。google要翻墙,下载不方便。
可以先用这个模型 : ckpt28500
# 模型参数如下,其他按照 demo 就好 # [Family Bar/position Pitch Velocity Duration Chord Rest Tempo] emb_sizes = [64, 256, 768, 256, 512, 256, 256, 256]后续我再整理传到 github,不过还是建议多用 Google,科学上网很重要呀 :)。
老师,我用[ckpt28500]这个模型,运行到mt.load_weights(checkpoint_path)出现如下错误: ValueError: Shapes (128, 1024) and (512, 1024) are incompatible
netpi
commented
2 years ago @liufeng5200
@netpi
@liufeng5200 真心希望作者能把训练好的模型放到百度网盘或github上。google要翻墙,下载不方便。
可以先用这个模型 : ckpt28500
# 模型参数如下,其他按照 demo 就好 # [Family Bar/position Pitch Velocity Duration Chord Rest Tempo] emb_sizes = [64, 256, 768, 256, 512, 256, 256, 256]后续我再整理传到 github,不过还是建议多用 Google,科学上网很重要呀 :)。
老师,我用[ckpt28500]这个模型,运行到mt.load_weights(checkpoint_path)出现如下错误: ValueError: Shapes (128, 1024) and (512, 1024) are incompatible
oh sorry, config 当中的参数也有变化 ~
# 模型参数如下,其他按照 demo 就好
# [Family Bar/position Pitch Velocity Duration Chord Rest Tempo]
emb_sizes = [64, 256, 768, 256, 512, 256, 256, 256]
config = {
"vocab_sizes": vocab_sizes,
"emb_sizes": emb_sizes,
"d_model": 512,
"dff": 1024,
"num_layers": 12,
"num_heads": 4,
"dropout_rate": 0.1,
"length": 1024,
"rpr": True,
"dataset": f'{database_name}_{train_seq_length}',
}@netpi
@liufeng5200
@netpi
@liufeng5200 真心希望作者能把训练好的模型放到百度网盘或github上。google要翻墙,下载不方便。
可以先用这个模型 : ckpt28500
# 模型参数如下,其他按照 demo 就好 # [Family Bar/position Pitch Velocity Duration Chord Rest Tempo] emb_sizes = [64, 256, 768, 256, 512, 256, 256, 256]后续我再整理传到 github,不过还是建议多用 Google,科学上网很重要呀 :)。
老师,我用[ckpt28500]这个模型,运行到mt.load_weights(checkpoint_path)出现如下错误: ValueError: Shapes (128, 1024) and (512, 1024) are incompatible
oh sorry, config 当中的参数也有变化 ~
# 模型参数如下,其他按照 demo 就好 # [Family Bar/position Pitch Velocity Duration Chord Rest Tempo] emb_sizes = [64, 256, 768, 256, 512, 256, 256, 256] config = { "vocab_sizes": vocab_sizes, "emb_sizes": emb_sizes, "d_model": 512, "dff": 1024, "num_layers": 12, "num_heads": 4, "dropout_rate": 0.1, "length": 1024, "rpr": True, "dataset": f'{database_name}_{train_seq_length}', }
您提供的 ckpt28500模型已经可以运行成功了,感谢老师! 现在有些不明白的地方,还想跟老师咨询一下,如何根据这个模型,来生成不同曲子。可以根据输入一段音频、一段文字等不同场景自动作曲吗?
netpi
commented
2 years ago @liufeng5200
@netpi
@liufeng5200
@netpi
@liufeng5200 真心希望作者能把训练好的模型放到百度网盘或github上。google要翻墙,下载不方便。
可以先用这个模型 : ckpt28500
# 模型参数如下,其他按照 demo 就好 # [Family Bar/position Pitch Velocity Duration Chord Rest Tempo] emb_sizes = [64, 256, 768, 256, 512, 256, 256, 256]后续我再整理传到 github,不过还是建议多用 Google,科学上网很重要呀 :)。
老师,我用[ckpt28500]这个模型,运行到mt.load_weights(checkpoint_path)出现如下错误: ValueError: Shapes (128, 1024) and (512, 1024) are incompatible
oh sorry, config 当中的参数也有变化 ~
# 模型参数如下,其他按照 demo 就好 # [Family Bar/position Pitch Velocity Duration Chord Rest Tempo] emb_sizes = [64, 256, 768, 256, 512, 256, 256, 256] config = { "vocab_sizes": vocab_sizes, "emb_sizes": emb_sizes, "d_model": 512, "dff": 1024, "num_layers": 12, "num_heads": 4, "dropout_rate": 0.1, "length": 1024, "rpr": True, "dataset": f'{database_name}_{train_seq_length}', }您提供的 ckpt28500模型已经可以运行成功了,感谢老师! 现在有些不明白的地方,还想跟老师咨询一下,如何根据这个模型,来生成不同曲子。可以根据输入一段音频、一段文字等不同场景自动作曲吗?
恭喜你呀,成功运行。 根据场景作曲,属于限制条件的作曲,我也在探索之中。
 ZheRao
commented
2 years ago
ZheRao
commented
2 years ago 您好,非常感激文中对如何pre-process一段音符详细的讲解:),请问一般钢琴曲有左右手两个track,如何让模型同时处理两个array of tokens呢?
netpi
commented
2 years ago @ZheRao 您好,非常感激文中对如何pre-process一段音符详细的讲解:),请问一般钢琴曲有左右手两个track,如何让模型同时处理两个array of tokens呢?
如果只有一种乐器一般是合并成一个 track 处理。如果必须独立处理,可以尝试 PITCH-[TRK], DURATION-[TRK], and VELOCITY-[TRK] 这样的标记方式。
ZheRao
commented
2 years ago @netpi
@ZheRao 您好,非常感激文中对如何pre-process一段音符详细的讲解:),请问一般钢琴曲有左右手两个track,如何让模型同时处理两个array of tokens呢?
如果只有一种乐器一般是合并成一个 track 处理。如果必须独立处理,可以尝试 PITCH-[TRK], DURATION-[TRK], and VELOCITY-[TRK] 这样的标记方式。
谢谢!我想用LSTM和GRU先做两个简单的模型,然后发现REMI output的是两个array,所以比较困惑怎么combine这两个track然后放到模型里面让它学,请问您附的那篇文章有combine的方法吗?我好好研究一下!谢谢!
KQDtianxiaK
commented
2 years ago  我尝试运行ckpt28500模型,但不知我这样设置是否正确,因为运行后它从我之前训练的一个模型一万五千多step又继续开始训练了,不知道何时停。
我尝试运行ckpt28500模型,但不知我这样设置是否正确,因为运行后它从我之前训练的一个模型一万五千多step又继续开始训练了,不知道何时停。
 这是尝试运行ckpt28500模型过程中出现的报错,想请问下如何运行已训练好的模型(:з」∠)
这是尝试运行ckpt28500模型过程中出现的报错,想请问下如何运行已训练好的模型(:з」∠)
 NaCl0w0
commented
2 years ago
NaCl0w0
commented
2 years ago 写的真的非常棒,无论是算法部分还是后面的感言部分!之后我尝试去colab运行模型,不过训练了大概六个小时后,生成MIDI阶段报错“TimeSignature”,请问大佬该如何解决呀...
NaCl0w0
commented
2 years ago 另外的话,我也想问,如何运行已经训练好的模型呀...
netpi
commented
2 years ago @NaCl0w0 写的真的非常棒,无论是算法部分还是后面的感言部分!之后我尝试去colab运行模型,不过训练了大概六个小时后,生成MIDI阶段报错“TimeSignature”,请问大佬该如何解决呀...
要看看具体错误了,有报错截图的话最好
netpi
commented
2 years ago @NaCl0w0 另外的话,我也想问,如何运行已经训练好的模型呀...
用 mt.load_weights(checkpoint_path) 就是 load 已有模型
生成参看:https://colab.research.google.com/drive/1M4-dW3PXrr8BUynejLHiZIbIV7XdpN9I#scrollTo=DwMd3O0iQMxW
 476678244
commented
2 years ago
476678244
commented
2 years ago 期待您传到github!
netpi
commented
2 years ago @476678244 期待您传到github!
Github 提示最大25M,所以传到百度云了。 链接: https://pan.baidu.com/s/1nuXN7xl2eIWDmXtxH7GkaA 密码: jqud
 whiplashf
commented
2 years ago
whiplashf
commented
2 years ago 请问博主的midi可视化软件是什么?还是py的库函数呢?
netpi
commented
2 years ago @whiplashf 请问博主的midi可视化软件是什么?还是py的库函数呢?
前端的可视化么,是在 magenta.js 基础上做了一些个性化定制。
netpi
commented
2 years ago 近来有些私信我的小伙伴,希望建立一个 「AI 音乐」微信群。我考虑了一下,决定建立一个 tg 群,主要讨论算法音乐以及相关的音频技术。欢迎对 AI 音乐有兴趣的小伙伴加入讨论,一起学习。
https://t.me/sound_and_music_computing
@whiplashf @476678244 @NaCl0w0 @KQDtianxiaK @ZheRao @@liufeng5200
 LALALKY
commented
2 years ago
LALALKY
commented
2 years ago 博主您好,我在运行到“配置tf-log”这一步时出现了如下报错:
 但是我修改前面的代码后没有报错了
但是我修改前面的代码后没有报错了
 所以觉得这可能是文件夹名字的问题?但文件夹名字如下:-vocab_sizes4-36-91-35-67-20-12-35-emb_sizes32-64-256-128-128-64-64-64-d_model128-dff1024-num_layers4-num_heads4-dropout_rate0.1-length1024-rprTrue-datasetpop17_1025
并没有发现其他符号,这该怎么解决呢?
所以觉得这可能是文件夹名字的问题?但文件夹名字如下:-vocab_sizes4-36-91-35-67-20-12-35-emb_sizes32-64-256-128-128-64-64-64-d_model128-dff1024-num_layers4-num_heads4-dropout_rate0.1-length1024-rprTrue-datasetpop17_1025
并没有发现其他符号,这该怎么解决呢?
 li-car-fei
commented
2 years ago
li-car-fei
commented
2 years ago KeyError Traceback (most recent call last)
netpi
commented
2 years ago @li-car-fei 运行colab时,生成Midi报错:
是 miditok 更新了,指定一下版本就好了
pip3 install miditok==v1.1.6
netpi
commented
2 years ago @li-car-fei 生成音乐过程中,有时会出现如下错误:
vel = int(compound_token[3].value) ValueError: invalid literal for int() with base 10: 'None'
有时候又不会出现,请问怎么解决?
FYI: 这是用 CKPT28500 推理的 Colab DEMO
 r0bin-zheng
commented
1 year ago
r0bin-zheng
commented
1 year ago @LALALKY 博主您好,我在运行到“配置tf-log”这一步时出现了如下报错:
+1 同样有这个问题
r0bin-zheng
commented
1 year ago 你好,最近没有接触相关工作了,不好意思
------------------ 原始邮件 ------------------ 发件人: "netpi/netpi.github.io" @.>; 发送时间: 2023年8月3日(星期四) 上午9:55 @.>; @.**@.>; 主题: Re: [netpi/netpi.github.io] AI 作曲 (完整思路) (Issue #30)
你好 我想問一下 能否額外寫一個本地端python or colab版本 就直接載入已訓練好的權重 不需要現在有太多用不到代碼 謝謝
— Reply to this email directly, view it on GitHub, or unsubscribe. You are receiving this because you commented.Message ID: @.***>
https://eurychen.me/post/music/ai-compose-music/