 137-rick
commented
1 year ago
137-rick
commented
1 year ago Open ninehills opened 1 year ago
137-rick
commented
1 year ago  Nietism
commented
1 year ago
Nietism
commented
1 year ago 从 ChatGLM-6B 到 ChatGLM2-6B 平均分的提升主要在数学以外的科目。
马克思主义和中国特色社会主义这两个科目分别从 52 和 53.4 升到了 69.3 和 68.9,初中化学、高中化学则分别从 40.5 和 28.5 提高到了 84.9 和 63.4,对底座模型的二次预训练使得 ChatGLM2 在这几门科目上提升巨大。而在数学方面,从 ChatGLM-6B 到 ChatGLM2-6B,高等数学、离散数学、高中数学、初中数学的分数则从 30.1 / 24.2 / 31.9 / 26 提高到了 32.4 / 27.5 / 32.5 / 36.7,可以看到在这几门较大程度上能反应推理能力、逻辑能力的科目上,从 ChatGLM-6B 到 ChatGLM2-6B 的提升并不明显。
Nietism
commented
1 year ago 从 ChatGLM-6B 到 ChatGLM2-6B 平均分的提升主要在数学以外的科目。
马克思主义和中国特色社会主义这两个科目分别从 52 和 53.4 升到了 69.3 和 68.9,初中化学、高中化学则分别从 40.5 和 28.5 提高到了 84.9 和 63.4,对底座模型的二次预训练使得 ChatGLM2 在这几门科目上提升巨大。而在数学方面,从 ChatGLM-6B 到 ChatGLM2-6B,高等数学、离散数学、高中数学、初中数学的分数则从 30.1 / 24.2 / 31.9 / 26 提高到了 32.4 / 27.5 / 32.5 / 36.7,可以看到在这几门较大程度上能反应推理能力、逻辑能力的科目上,从 ChatGLM-6B 到 ChatGLM2-6B 的提升并不明显。
另外,在报告的几个 benchmark 上,ChatGLM2 的最高表现都来自于 base model + few-shot prompting (w/o CoT),chat model + zero-shot CoT 的表现反而没有前者高,跟百川一样,数学题也是没有 CoT 过程直接预测答案的。
 OedoSoldier
commented
1 year ago
OedoSoldier
commented
1 year ago 我用文心一言,遵照官方给出的 prompt 格式(zero-shot)测试了 op 的几道题目,答案是:CDABD,对了 4 道题。我体感是,文心一言经过数次迭代后最新版本(0621 V2.1.0)能力已经很强了,不过可惜 API 尚未大范围开放,无法进行批量评测
具体答案如下:


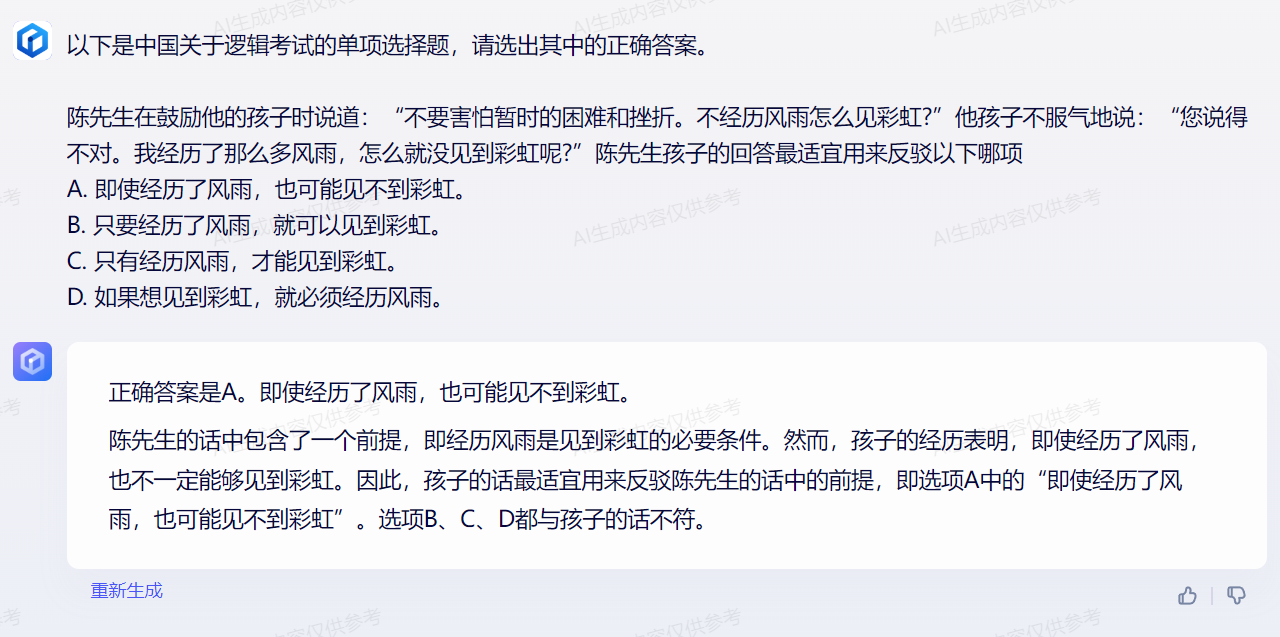
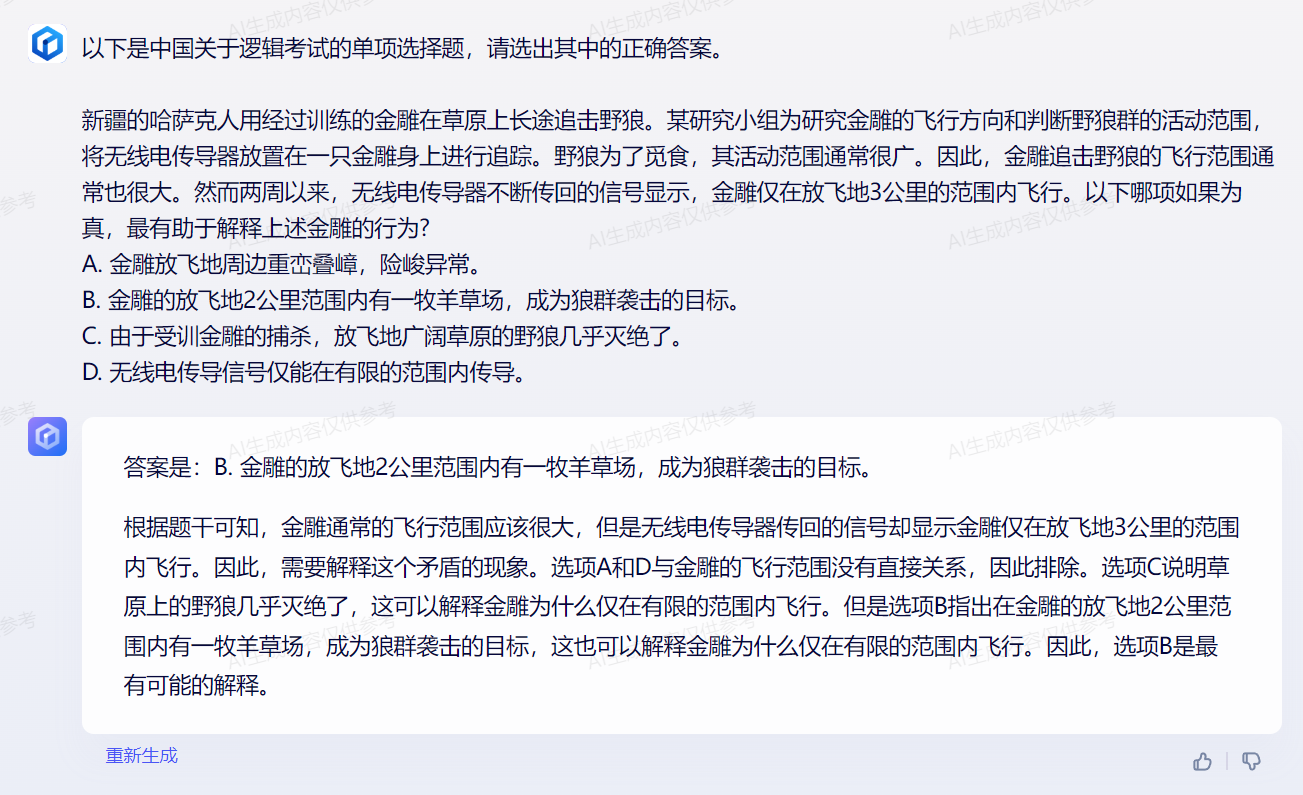
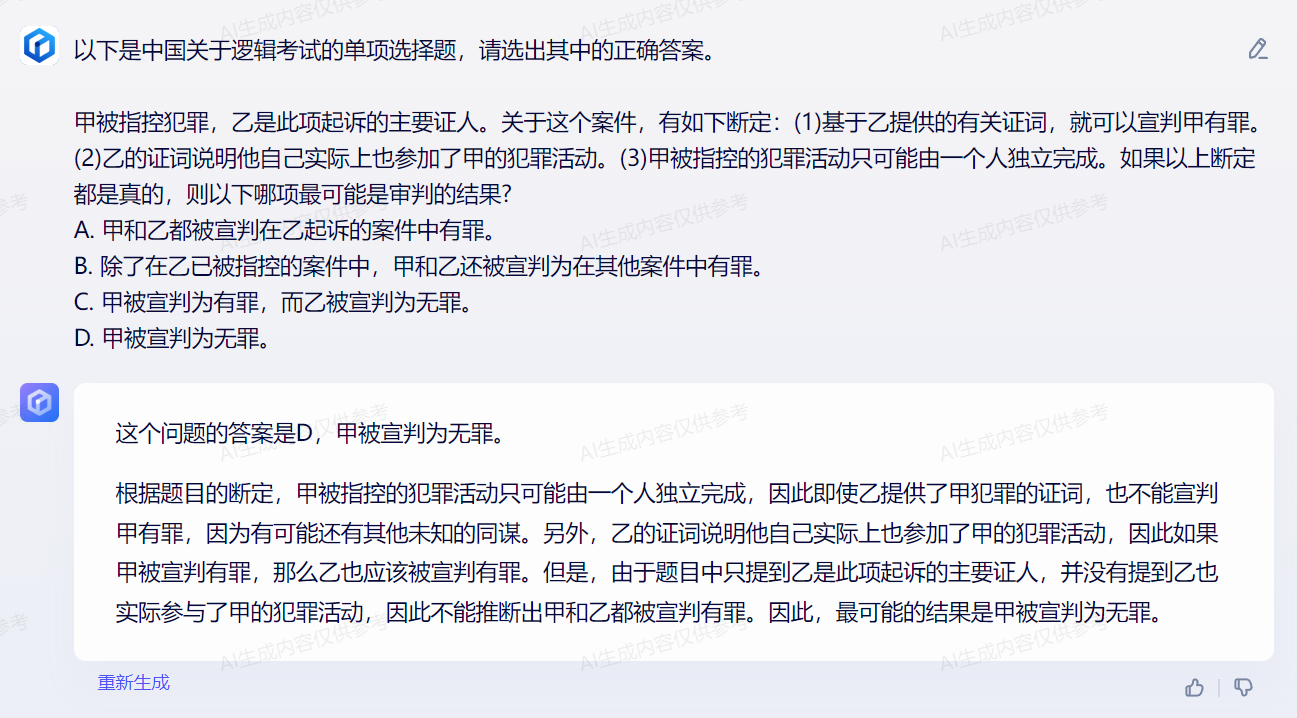
最近 C-Eval 有较多中文开源模型打榜,分数一度超越 GPT-4,今天做一下简单的复盘。
首先排名靠前的几位全部是封闭模型,连API也不对外提供,无法进行评测。
顺序找下去,发现 ChatGLM2-6B 可以用,来做一次简单的分析。
评测大模型的能力,最难的莫过于逻辑能力和数学能力,我们用 ChatGPT 3.5对比,根据 C-Eval 官方榜单的详细评测项目:
可以发现 ChatGLM2-6B 总的来说和 ChatGPT 区别不大,可喜可贺。我们选择分数最为接近的 Logic ,用 c-eval 官方提供的验证数据集(有答案)共 21 道题中随机选5道题,进行 Zero-shot 对比。同时用我觉得中文模型数学和逻辑能力还不错的讯飞星火做对比。
3:0:1,我相信这个并不仅仅是误差。当然因为实际榜单里使用的是 Few-shot,可能会让能力有所提升。但是我想本身Zero-shot 能力也是模型能力的一部分,多数大模型使用场景还是 Zero-shot。
有时间一定要做一次评测复现。