 cjihrig
commented
1 year ago
cjihrig
commented
1 year ago @manekinekko is there any update on this? I think this is probably the highest priority item for the test runner at this point.
Closed manekinekko closed 1 year ago
cjihrig
commented
1 year ago @manekinekko is there any update on this? I think this is probably the highest priority item for the test runner at this point.
 MoLow
commented
1 year ago
MoLow
commented
1 year ago I think this is probably the highest priority item for the test runner at this point.
+1. if there is any help needed with this LMK.
additionaly - will this solution support arbitrary console.log statements? https://github.com/nodejs/node/issues/44372
 manekinekko
commented
1 year ago
manekinekko
commented
1 year ago Sorry for the delay guys. Had to deliver some work lately.
So, the biggest challenge I need to work on solving right now is redesigning the lexer so it can support async scanning and make the parser support partial parsing, and emit the results once they are available (as discussed with @cjihrig over Twitter).
A draft of a public API I am thinking of would look something like this:
const parser = new TapParser(/* probably a flag to enable stream support */);
child.stdout.on('data', (chunk) => {
parser.parse(chunk);
});
child.stdout.on('end', () => {
const status = parser.end();
assert.strictEqual(status.ok, true);
});@MoLow @cjihrig do you have any ideas about a different design / or a concern?
cjihrig
commented
1 year ago Is the lexer right now reading individual characters? If so, I think we can leverage the fact that TAP is line based. That would make it significantly simpler than a parser for something like a programming language. I think that would also make it simpler to handle streaming.
manekinekko
commented
1 year ago The parser is already splitting tokens (scanned by the lexer) into subsets, separated by EOL. The resulting array basically contains all tokens scanned at each TAP line.
from [ token1, EOL, token2, EOL, ..., EOL, tokenN-1, tokenN ]
to [ [token1], [token2], [...], [tokenN-1, tokenN] ]So I was thinking of leveraging this logic for streams. is that was you were referring to?
cjihrig
commented
1 year ago I guess I'm just wondering if we need a full blown lexer. Would it be simpler (less code, faster for us to get something shipped) to read input, turn it into lines, and parse each line. There are only a handful of line types outside of yaml blocks, and we can generally distinguish them by looking at just the first few characters of the line (whitespace, 'ok', 'not ok', 'TAP version', etc.).
MoLow
commented
1 year ago @cjihrig how would you expect a console.log or any invalid tap to behave?
MoLow
commented
1 year ago we can generally distinguish them by looking at just the first few characters of the line (whitespace, 'ok', 'not ok', 'TAP version', etc.).
There is something vere similar here https://github.com/nodejs/tap2junit just FYI
cjihrig
commented
1 year ago @cjihrig how would you expect a
console.logor any invalid tap to behave?
According to the spec:
Any output that is not a version, a plan, a test line, a YAML block,
a diagnostic or a bail out is incorrect. How a harness handles the
incorrect line is undefined. Test::Harness silently ignores incorrect
lines, but will become more stringent in the future. TAP::Harness
reports TAP syntax errors at the end of a test run.and
In this document, the “harness” is any program analyzing TAP
output. Typically this will be Perl’s runtests program, or the underlying
TAP::Harness-runtests> method. A harness must only read TAP
output from standard output and not from standard error. Lines written
to standard output matching /^(not )?ok\b/ must be interpreted as test
lines. After a test line a block of lines starting with ‘—’ and ending with
‘…’ will be interpreted as an inline YAML document providing extended
diagnostic information about the preceding test. All other lines must not
be considered test output.I think if there are extra lines, that might come from console.log()s, we should try to keep them but definitely not error because users would not be able to add logging statements in their tests. If the TAP lines themselves are malformed I think we should report an error (unless I missed something about this in the spec, in which case I defer to the spec).
manekinekko
commented
1 year ago I agree with @cjihrig on the specs. The parser in this PR will error if a line starts with an unrecognized token. Pragmas are parsed but not yet applied.
Could we print those console.logs as comments?
MoLow
commented
1 year ago I think it is ok to print invalid tap as a comment or something else, but we should not just ignore it
manekinekko
commented
1 year ago @cjihrig @MoLow wdyt about this API?
const args = ['--test', testFixtures];
const child = spawn(process.execPath, args);
const parser = new TapParser(); //<-- create a parser instance
child.stdout.on('data', (chunk) => {
const line = chunk.toString('utf-8');
const test = parser.parseChunk(line); //<--- call parseChunk()
console.log(test);
});The test output can be either:
undefined (when we parse non-testpoint entries like pragmas or comments) {
"status": { fail: false, pass: true, todo: false, skip: false },
"id": "1",
"description": "/home/wassimchegham/oss/@nodejs/node/test/fixtures/test-runner/index.test.js",
"reason": "",
diagnostics: [ 'duration_ms: 0.033821156', 'duration_ms: 0.033821156' ]
}@manekinekko I would expect something based on node:readline, like:
class TapParser extends readline.InterfaceConstructor {
constructor(input, output) {
super(input, output);
this.on('line', (line) => {
..parse the line and
this.emit('test') / this.emit('diagnostic') etc
})
}
}either that or
class TapParser extends TapStream {
constructor(input) {
this.handle = readline.createInterface({ input });
this.handle.on('line', (line) => {
..parse the line and
this.ok(data) / this.fail(data) etc
})
}
}that is obviously very simplistic since TAP parsing can include multilines, etc
manekinekko
commented
1 year ago @MoLow My understanding is that @cjihrig wanted this parser to read the child's output. Is that still the case?
MoLow
commented
1 year ago @MoLow My understanding is that @cjihrig wanted this parser to read the child's output. Is that still the case?
yeah - if you follow one of these examples: new TapParser({ input: child.stdout })
cjihrig
commented
1 year ago I think building on top of readline could work. I'm not sure if it will introduce some overhead, but we can always address that in the future if it's the case - a slow parser is better than no parser. I don't think the parser should extend TapStream though since TapStream is for generating TAP and the parser is for consuming it.
As for the question about the API - the parser will need to consume data chunks from the child processes (note that lines can span multiple chunks, so that needs to be accounted for). As tests are processed, it should emit some event for the test including all of the things we would want to print from the main test runner process. It will also need to handle errors, bail outs, and warnings that might come from the child process. I think looking at the current test runner tests in test/message will help identify the various cases that need to be supported.
EDIT: Another thing worth investigating is whether is makes sense to have the parser be a Node transform stream.
manekinekko
commented
1 year ago Another thing worth investigating is whether is makes sense to have the parser be a Node transform stream.
I was considering this also, after chatting with @benjamingr the other day.
MoLow
commented
1 year ago Small update:
I have created a a POC that parses the output with Regexes.
I discussed this with @manekinekko and we had a session where we took some parts from my code into this branch allowing the full flow to work with the TapParser.
once @manekinekko finalizes his implementation we can decide which approach is better to use (Full LL(1) parser vs simplistic regex).
a few considerations I raised:
cjihrig
commented
1 year ago performance: does one solution performs significantly better than another?
I think another consideration is the complexity of the code. My gut feeling is that an LL(1) parser will require more code and be more work to maintain (especially for people new to the code or people unfamiliar with compiler theory 😅).
will we want to expose in the future the tap parser so reporters can be implemented in user-land? if so, is one of the APIs better in terms of DX? can the other API be adjusted?
I think this one is important. People are already asking for reporters, and there is a good chance that all/most of them will be implemented on top of the parser that comes out of this work.
MoLow
commented
1 year ago @manekinekko @cjihrig I have created a branch comparing the two implementations,
in terms of performance, they seem to be very similar with a very small advantage to the regex parser (tested 1000 runs on my machine):
node-benchmark-compare benchmark/tap_parser/out.csv ✔ 32m 4s 15:44:37
confidence improvement accuracy (*) (**) (***)
tap_parser/compare.js n=1 *** -0.83 % ±0.49% ±0.64% ±0.82%
Be aware that when doing many comparisons the risk of a false-positive result increases.
In this case, there are 1 comparisons, you can thus expect the following amount of false-positive results:
0.05 false positives, when considering a 5% risk acceptance (*, **, ***),
0.01 false positives, when considering a 1% risk acceptance (**, ***),
0.00 false positives, when considering a 0.1% risk acceptance (***)in terms of functionality - the LL(1) parser still lacks some of the nested details.
see the diff of running ./node --no-warnings --test test/fixtures/test-runner/index.test.js test/fixtures/test-runner/nested.js test/fixtures/test-runner/invalid_tap.js:
https://www.diffchecker.com/0vVknpus
many of the yaml details are ommited from the LL(1) output
manekinekko
commented
1 year ago Thanks @MoLow for doing this benchmark. Would you mind sharing a guide on how to run the benchmark locally? I am not familiar with the benchmark process included in node core.
many of the yaml details are ommited from the LL(1) output in terms of functionality - the LL(1) parser still lacks some of the nested details.
This is because I forgot to remove this code I copied from your other PR which is not relevant for the LL parser. Once removed, top-level diagnostics should be parsed.

MoLow
commented
1 year ago Would you mind sharing a guide on how to run the benchmark locally? I am not familiar with the benchmark process included in node core.
This is because I forgot to remove [this code I copied from your other PR]
let's perform another comparison once this PR works as expected
manekinekko
commented
1 year ago Thank you @MoLow for the link to the guide. I've temporarily added to this PR the benchmark files + your regex parser from your PR and other files (I will remove all unnecessary files once we move on to the next step). I did a few changes to make the LL parser handles more edge cases + some refactoring.
Here are the results of my benchmark, and as you mentioned, both parsers perform almost the same. The difference is barely noticeable.
➜ node benchmark/compare.js \
--old ./node-ll-parser \
--new ./node-regex-parser \
--runs 500 \
--filter compare.js tap_parser > benchmark/tap_parser/out.csv
[00:14:43|% 100| 1/1 files | 1000/1000 runs | 1/1 configs]: Done
➜ node-benchmark-compare benchmark/tap_parser/out.csv
confidence improvement accuracy (*) (**) (***)
tap_parser/compare.js n=1 -0.17 % ±0.22% ±0.29% ±0.38%
Be aware that when doing many comparisons the risk of a false-positive result increases.
In this case, there are 1 comparisons, you can thus expect the following amount of false-positive results:
0.05 false positives, when considering a 5% risk acceptance (*, **, ***),
0.01 false positives, when considering a 1% risk acceptance (**, ***),
0.00 false positives, when considering a 0.1% risk acceptance (***)Here is the diff (Left: regex - Right: LL) (I cleaned the file paths to have less diffs)

cjihrig
commented
1 year ago @MoLow and @manekinekko thank you so much for the benchmark work! If the performance of both approaches is roughly the same, I think we should go with whatever is going to be the simplest to maintain.
MoLow
commented
1 year ago I think we should go with whatever is going to be the simplest to maintain.
I think the regex-based parser is easier to understand - but I am the one who wrote it so I am probably not objective
manekinekko
commented
1 year ago Thank you @cjihrig this means a lot.
Here are some random thoughts about the regex and LL lexer/parsers based on my experience. I will try to make it as objective as possible:
Obviously, both parsers perform almost the same. The difference is barely noticeable. This is true for the current implementation of both parsers. Also, given the fact that the LL parser is hand-written, it could be easily optimized/tweaked/extended in the future (if needed).
The LL parser is undoubtedly more verbose, but this is because of the code that supports non-stream scenarios. We can easily remove 1/3 of the code if we delete all the visitors' API. We can also refactor this part of the code in the future. However, if we are planning to expose the parser API to userland, I guess we might need to allow non-stream scenario (but I won't push for it). You guys can decide.
The regex parser is more maintainable for sure, it's less verbose, however, not everyone is familiar with regular expressions, nor can write efficient regex. I am not saying regex is slow, I understand that Irregexp runs tons of optimizations. But in general, regex can be error-prone and hard to debug.
The LL parser provides out-of-the-box line/column/position for each token, which could be useful for the reporters/consumer. This can help point users to the exact line/column/position where the TAP error is. I guess this could be added to the regex parser with some additional code.
As for maintenance of the LL parser, I can assure you there are no fancy algorithms whatsoever nor compiler theory necessary. In fact, the LL is not a complete LL parser (as per the strict definition) but a simple mapping of the TAP specifications, as you can tell from the method naming. The rest of the code is glue code. Also, don't judge the complexity of the LL parser by the number of lines in that file, that file contains so many comments and inline explanations :)
As mentioned to @cjihrig and @MoLow (as well as @fhinkel and @benjamingr) I am committed to delivering this feature and helping with future maintenance. Please also know that I have full support from my leadership at Microsoft.
With all that being said, I am happy to support @MoLow with the regex parser implementation, if that is your choice.
 Trott
commented
1 year ago
Trott
commented
1 year ago Apologies if this is explained already and I just missed it (whew, a lot of comments on this one): Is there any reason not to land this and if someone wants to replace it with a regex parser at a future date, then hey, that's fine, as long as all the tests continue to pass, etc.? Performance can also be a consideration at that point.
 fhinkel
commented
1 year ago
fhinkel
commented
1 year ago Apologies if this is explained already and I just missed it (whew, a lot of comments on this one): Is there any reason not to land this and if someone wants to replace it with a regex parser at a future date, then hey, that's fine, as long as all the tests continue to pass, etc.? Performance can also be a consideration at that point.
Agree with @Trott, I don't think the tap parser is performance critical.
MoLow
commented
1 year ago Is there any reason not to land this and if someone wants to replace it with a regex parser at a future date, then hey, that's fine, as long as all the tests continue to pass, etc.?
The only reason is the regex parser was ready and this PR was not yet working at the time of the comparison. Assuming there is not much work completing this PR it indeed should probably land
manekinekko
commented
1 year ago @cjihrig do we need to expose the parser API to users in this PR, or should I send a different PR once this one got reviewed and merged?
cjihrig
commented
1 year ago We definitely don't need to expose the parser to userland yet.
manekinekko
commented
1 year ago How will this work with reporters? People don't like reading raw TAP all the time. It would be nice if a reporter could build on the parser API, but looking at the changes in lib/internal/test_runner/runner.js, that seems like it would be non-trivial. I envision specifying a reporter from the command line. The reporter would then consume the parser API, so we'd want to make that as straightforward as possible. It would likely need to work both with and without the CLI runner (--test). To be clear, I'm not suggesting you actually implement reporters here - we should just think about it before merging this.
Yeah. a reporter would need to call the parser API like so:
const {TapParser, TokenKind} from 'node:test';
function fancyReporter(input) {
const parser = new TapParser();
const ast = parser.parseSync(input); // or parse(callback)
// ast.check((); // they can optionally validate the TAP content
for (let index = 0; index < ast.length; index++) {
const node = ast[index];
switch (node.kind) {
case TokenKind.TAP_TEST_OK:
// node is
// {
// test: {
// status: { fail: false, pass: true, todo: false, skip: false },
// id: '1',
// description: 'foo',
// reason: 'bar',
// },
// }
}
}
}Is it possible to add unit tests for the streaming interface?
Yes, I will add those.
Is it possible to add message tests that show the whole thing working? For example, the current CLI runner only shows the output from the child processes if there is a failure. That was a workaround to get the test runner merged before the TAP parser was written. Now, with the parser in place, it would be nice to see a test file with no failures outputting TAP.
I am not totally familiar with message tests yet. Would you mind sharing an example?
manekinekko
commented
1 year ago FYI, I'm working on fixing the timeout issue in test file test/parallel/test-runner-inspect.mjs
MoLow
commented
1 year ago Regarding an interface for reporters, the parser will emit each token - that is not very helpful for reporters.
manekinekko
commented
1 year ago @MoLow the parser does not emit every token, but rather it emits what it recognizes based on the specs: version number, plan, tests plans, comments, diagnostics and pragmas.
MoLow
commented
1 year ago I am not totally familiar with message tests yet. Would you mind sharing an example?
@manekinekko my implementation included a message test, input
and output
note I have introduced the FlagsOnly notion to the python test runner but that might not be needed and you can just run spwan(fixture, { stdio: 'inherit' })
you can run the test with python tools/test.py test/message/test_runner_cli_output.js
for refrence see/run other files in the test/message directory
MoLow
commented
1 year ago I think this is pretty good for internal usage, but exposing the interface for reporters still requires a little improvment IMHO:
node be changed to test? or something else?lexme mean? https://github.com/nodejs/node/blob/d97256a32c171e06a9b413e68db5ef12cdec5dbf/lib/internal/test_runner/runner.js#L235manekinekko
commented
1 year ago
- the parser emits the test data in two different objects: test_runner: add TAP parser #43525 (comment)
This should be fixed by https://github.com/nodejs/node/pull/43525/commits/53a4e58778ac14043e03e947431f1a595b63ae14
- some naming might be confusing should
nodebe changed to test? or something else?
Here node represents an emitted node from the AST. This can be one of the recognized features (test point, version, plan, ...)
- what does
lexmemean?
A lexeme here is the raw string that the parser recognized. Happy to change the name. Any suggestions?
manekinekko
commented
1 year ago @MoLow @cjihrig please let me know if you need me to make other changes.
cjihrig
commented
1 year ago It looks like the CI is failing. I'll review again once it's passing.
manekinekko
commented
1 year ago Sorry about that @cjihrig. I am wondering if this is related to this error
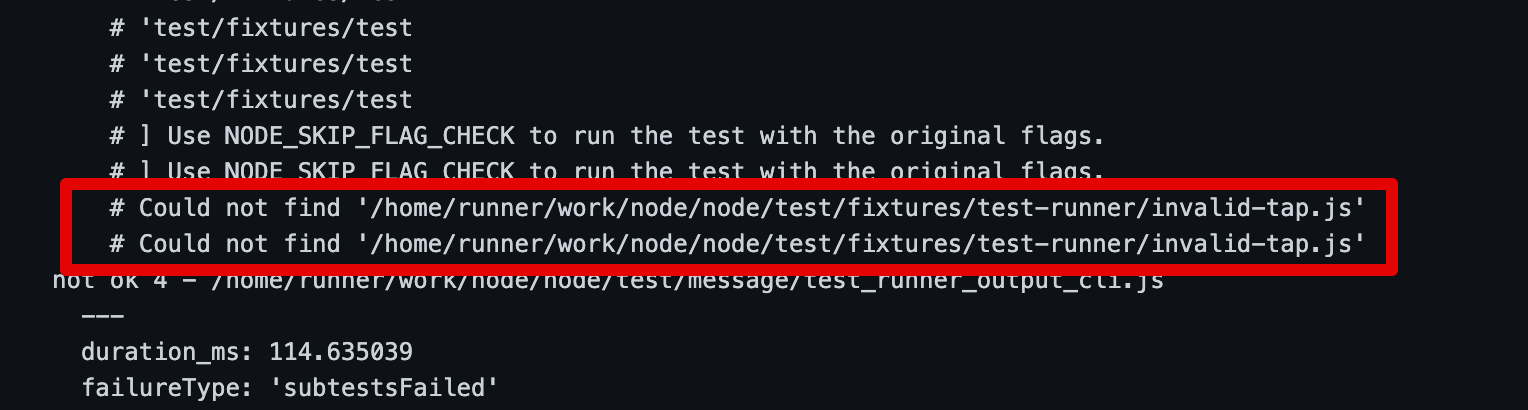
I looked at the file invalid-tap.js (note the dash) and don't know where it is referenced!? The correct file is invalid_tap.js
cjihrig
commented
1 year ago It looks like the logic that processes // Flags replaces underscores with dashes here. Since that is a problem that only exists inside the Node core test suite, I think you could work around it by renaming that file.
manekinekko
commented
1 year ago Done. Thanks @cjihrig 👍
manekinekko
commented
1 year ago Thanks @MoLow I'm working on a fix for the falling test.
cjihrig
commented
1 year ago @manekinekko I just gave this another pass. I think this LGTM too once the CI is passing. If you're having trouble getting a message test working, you could try making it a normal test and use snapshot testing for the TAP output.
manekinekko
commented
1 year ago @cjihrig @MoLow all TAP parser-related tests are now passing locally and on CI. I had to split test_runner_output_cli.js message test into single tests because all individuals message tests are passing but when combined together into test_runner_output_cli_single.js they randomly fail/pass for a reason I can't explain 😅
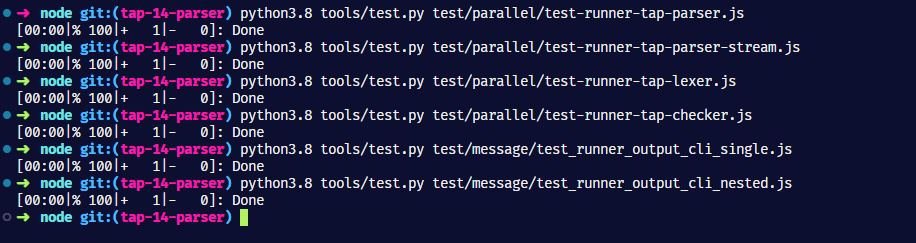
manekinekko
commented
1 year ago @cjihrig @MoLow any idea why the tests are failing this time? Tried to read the logs but couldn't find why.
The parallel test I added is passing locally...

 nodejs-github-bot
commented
1 year ago cjihrig
commented
1 year ago
nodejs-github-bot
commented
1 year ago cjihrig
commented
1 year ago It looks like the CI has some relevant failures - https://ci.nodejs.org/job/node-test-pull-request/47385/
This PR adds initial support for a TAP LL(1) parser. This implementation is based on the grammar for TAP14 from https://testanything.org/tap-version-14-specification.html
TODO:
make lint)Refs: #43344 Signed-off-by: Wassim Chegham github@wassim.dev
@benjamincburns @fhinkel @cjihrig