 devosb
commented
4 years ago
devosb
commented
4 years ago If I swap the order of the vowel sign and KEMPHRENG (option 3 in the comment above) the rendering does not show any dotted circles with the same environments as above.
File harfbuzz-noto.png:

File directwrite-noto.png:
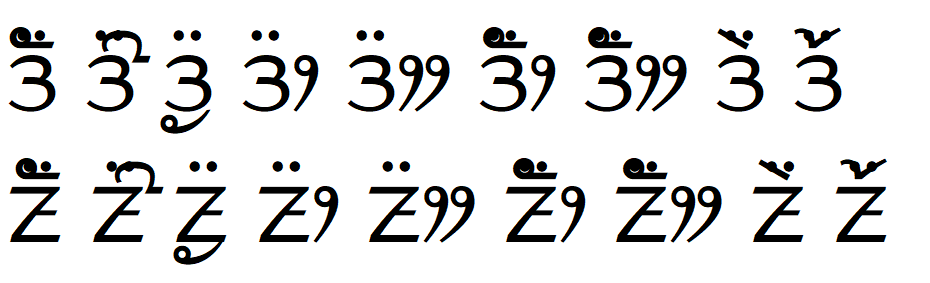
 NorbertLindenberg
NorbertLindenberg mhosken
mhosken behdad
behdad
Font
NotoSansLimbu-Regular.ttf
Where the font came from, and when
Site: https://github.com/googlefonts/noto-fonts/blob/master/phaseIII_only/unhinted/ttf/NotoSansLimbu/NotoSansLimbu-Regular.ttf Date: 2019-12-02
Font Version
2.000
OS name and version
Ubuntu Bionic amd64 Windows 10 Pro 1909
Application name and version
On Ubuntu - Libre Office Writer 6.0.7 On Windows - Notepad
Issue
Using U+193A LIMBU SIGN KEMPHRENG as a length mark after a vowel sign causes dotted circles with some vowel signs.
auto-length.txtformat with font in the above applications. auto-length.txt The file has space separated clusters of (U+190B|U+190F)(VOWEL SIGN x)(U+193A). I suspect the issue would happen with any consonant.harfbuzz-noto.pngfrom LibreOffice Writer on Ubuntudirectwrite-noto.pngfrom Notepad on Windows. Note that DirectWrite produces more dotted circles than HarfBuzz.harfbuzz-namdhinggo.pnglimbscript lookups removed, leaving onlylatnscript lookups. I suspect the results would be the same if thelatnlookups were replaced withDFLTscript. This way, the USE does not get invoked on Ubuntu LibreOffice Writer. On Widows, the USE would have been called, and dotted circles produced.If I use
hb-view, I can have lookups for bothlimbandlatnscript, and by passing--scripttohb-viewI can reproduce the dotted circles withlimband the desired result (no dotted circles) withlatn.If U+193A is classified with UISC = Tone_Mark, this would cause the Sigla to become VMAbv (VOWEL_MOD_ABOVE) and since all vowel modifiers come after vowels, then the cluster validation will pass. Changing the HB source code (locally) to use VMAbv instead of VAbv fixes the issue.
So, can the Noto font be modified to have a lookup that removes the dotted circle that USE inserts? Other options are:
Personally, I suspect option 1 or 2 would be best, but that is just my opinion.
Character data
Attached above.
Screenshot
Attached above.