 nutterb
commented
7 years ago
nutterb
commented
7 years ago I'm not opposed to the idea, but there are a few questions I would want resolve prior to taking on a project like this. For instance
- How should interaction terms be addressed?
- How should factor variables be retrieved?
- Most model objects return a
termcolumn when tidied viabroom, but what should happen if there is notermcolumn. - What should be the behavior if there is no confidence interval method for the object? When no p-value is available?
- Are there specific formats that should be followed? For example, APA formats? (Ugh)
- What should happen if an inappropriate
formis requested. For example, if I request an odds ratio with a t.test object.
Questions 1-4 seem like they would need pretty firm answers before committing any serious code effort. 5 and 6 are things I think could become headaches in the future.
Just brainstorming out loud, but would be interested in your thoughts on 1-4.
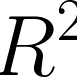 simonthelwall
simonthelwall ckraner
ckraner

I was thinking that it would be great if R had a set of functions for including regression output in body text and was wondering whether you thought this would be a good fit for pixiedust, or whether it would be out of scope for the package?
I imagine it working something like the following:
where
xis a regression model andyan independent variable.The output would look like
What do you think?