OddBloke
commented
1 year ago
OddBloke
commented
1 year ago One outstanding issue: the parent test in the summary window will have its result based on the most recent run: if only a passing set of instances were run, it will show green, even if there are failing instances from previous runs.
 rcarriga
rcarriga urmzd
urmzd duncanam
duncanam tku137
tku137
(This is very rough, so I'm opening it as draft: this is the first Lua I've written that wasn't neovim configuration, so it will need substantial rework before it can land!)
These commits modify
PythonNeotestAdapter.discover_positions(path)to:pytest --collect-only <path>(vianeotest_python.py)[a-b-c])This would fix #35
It also includes one modification to get the UX to work correctly: individual test instances aren't tied to locations in
pytest, as they can be generated by the cross-product of several decorators and/or fixtures. It follows that the cursor position should still select the parent test, and not the test instances. As far as I can tell, this isn't currently achievable in neotest: settingrange = nilon the position results in all sorts of errors, and leaving it the same as the parent test results in the last test instance being focused.With this hack to neotest core, and 602a0ac1c9a92c5b498b9af4950272796e38605a, positions can declare that they should be excluded from focus (a better variable name would not go amiss, but it's getting late!):
This results in the parameters being displayed in the summary, while the parent test is selected: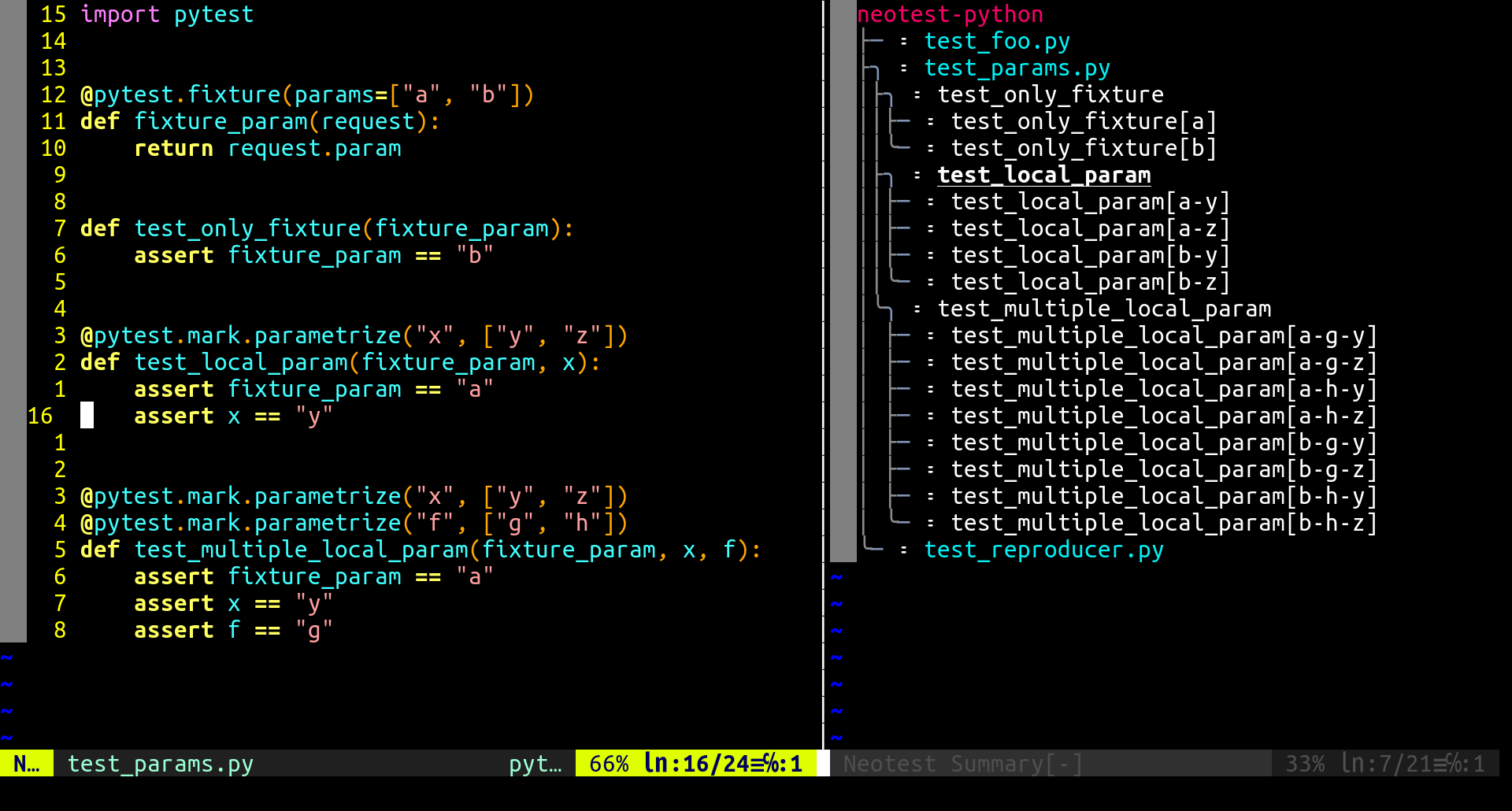
neotest.run.runin a test definition will run all test instances:And you can selectively run individual test instances from the summary window (the highlighting of the test name is from another plugin, oopsie):