 pahud
commented
5 years ago
pahud
commented
5 years ago 可能需要定位這個問題是不是本身kops的問題,如果是的話需要反饋到上游kops社區去讓上游從根本來改進。
如果只部署kops集群,不配置Istio或其他功能,集群也會如此嗎?
Closed YuTingLiu closed 5 years ago
pahud
commented
5 years ago 可能需要定位這個問題是不是本身kops的問題,如果是的話需要反饋到上游kops社區去讓上游從根本來改進。
如果只部署kops集群,不配置Istio或其他功能,集群也會如此嗎?
 YuTingLiu
commented
5 years ago
YuTingLiu
commented
5 years ago @pahud 感谢回复,很想定位问题,但是我现在没有办法记录NODE在DOWN之前,有何记录,只要NOTREADY,SSH无法访问,是否有其它方式,我也不懂。 我会再尝试只部署集群
YuTingLiu
commented
5 years ago @pahud 只部署仍然出现这个问题,定位到: · Events: Type Reason Age From Message
Warning FailedScheduling 13s (x49 over 26m) default-scheduler 0/5 nodes are available: 5 node(s) had taints that the pod didn't tolerate.
· 貌似kube-dns、kube-proxy和kube-dns-autoscaler有问题,全部为PENDING状态。
pahud
commented
5 years ago 有辦法提供比較完整的資料方便重現問題嗎?
例如請附上你使用的Makefile以及具體你創建集群的命令?
目前還沒聽說按照README起集群在寧夏或北京region會遇到這個情況
YuTingLiu
commented
5 years ago # customize the values below
TARGET_REGION ?= cn-northwest-1
AWS_PROFILE ?= default
KOPS_STATE_STORE ?= s3://cluster.k8s.xxx
VPCID ?= vpc-223c8c4b
MASTER_COUNT ?= 3
MASTER_SIZE ?= m4.large
NODE_SIZE ?= m4.large
NODE_COUNT ?= 2
SSH_PUBLIC_KEY ?= ~/.ssh/id_rsa.pub
KUBERNETES_VERSION ?= v1.12.8
KOPS_VERSION ?= 1.12.1
# do not modify following values
AWS_DEFAULT_REGION ?= $(TARGET_REGION)
AWS_REGION ?= $(AWS_DEFAULT_REGION)
ifeq ($(TARGET_REGION) ,cn-north-1)
CLUSTER_NAME ?= cluster.bjs.xxx.k8s.loca
AMI ?= ami-0032227ab96e75a9f
ZONES ?= cn-north-1a,cn-north-1b
endif
ifeq ($(TARGET_REGION) ,cn-northwest-1)
CLUSTER_NAME ?= cluster.zhy.zqh.k8s.local
AMI ?= ami-006bc343e8c9c9b22
ZONES ?= cn-northwest-1a,cn-northwest-1b,cn-northwest-1c
endif
ifdef CUSTOM_CLUSTER_NAME
CLUSTER_NAME = $(CUSTOM_CLUSTER_NAME)
endif
KUBERNETES_VERSION_URI ?= "https://s3.cn-north-1.amazonaws.com.cn/kubernetes-release/release/$(KUBERNETES_VERSION)"
.PHONY: create-cluster
create-cluster:
@KOPS_STATE_STORE=$(KOPS_STATE_STORE) \
AWS_PROFILE=$(AWS_PROFILE) \
AWS_REGION=$(AWS_REGION) \
AWS_DEFAULT_REGION=$(AWS_DEFAULT_REGION) \
kops create cluster \
--cloud=aws \
--name=$(CLUSTER_NAME) \
--image=$(AMI) \
--zones=$(ZONES) \
--master-count=$(MASTER_COUNT) \
--master-size=$(MASTER_SIZE) \
--node-count=$(NODE_COUNT) \
--node-size=$(NODE_SIZE) \
--vpc=$(VPCID) \
--kubernetes-version=$(KUBERNETES_VERSION_URI) \
--networking=amazon-vpc-routed-eni \
--ssh-public-key=$(SSH_PUBLIC_KEY)
.PHONY: edit-ig-nodes
edit-ig-nodes:
@KOPS_STATE_STORE=$(KOPS_STATE_STORE) \
AWS_PROFILE=$(AWS_PROFILE) \
AWS_REGION=$(AWS_REGION) \
AWS_DEFAULT_REGION=$(AWS_DEFAULT_REGION) \
kops edit ig --name=$(CLUSTER_NAME) nodes
.PHONY: edit-cluster
edit-cluster:
@KOPS_STATE_STORE=$(KOPS_STATE_STORE) \
AWS_PROFILE=$(AWS_PROFILE) \
AWS_REGION=$(AWS_REGION) \
AWS_DEFAULT_REGION=$(AWS_DEFAULT_REGION) \
kops edit cluster $(CLUSTER_NAME)
.PHONY: update-cluster
update-cluster:
@KOPS_STATE_STORE=$(KOPS_STATE_STORE) \
AWS_PROFILE=$(AWS_PROFILE) \
AWS_REGION=$(AWS_REGION) \
AWS_DEFAULT_REGION=$(AWS_DEFAULT_REGION) \
kops update cluster $(CLUSTER_NAME) --yes
.PHONY: validate-cluster
validate-cluster:
@KOPS_STATE_STORE=$(KOPS_STATE_STORE) \
AWS_PROFILE=$(AWS_PROFILE) \
AWS_REGION=$(AWS_REGION) \
AWS_DEFAULT_REGION=$(AWS_DEFAULT_REGION) \
kops validate cluster
.PHONY: delete-cluster
delete-cluster:
@KOPS_STATE_STORE=$(KOPS_STATE_STORE) \
AWS_PROFILE=$(AWS_PROFILE) \
AWS_REGION=$(AWS_REGION) \
AWS_DEFAULT_REGION=$(AWS_DEFAULT_REGION) \
kops delete cluster --name $(CLUSTER_NAME) --yes
.PHONY: rolling-update-cluster
rolling-update-cluster:
@KOPS_STATE_STORE=$(KOPS_STATE_STORE) \
AWS_PROFILE=$(AWS_PROFILE) \
AWS_REGION=$(AWS_REGION) \
AWS_DEFAULT_REGION=$(AWS_DEFAULT_REGION) \
kops rolling-update cluster --name $(CLUSTER_NAME) --yes --cloudonly
.PHONY: get-cluster
get-cluster:
@KOPS_STATE_STORE=$(KOPS_STATE_STORE) \
AWS_PROFILE=$(AWS_PROFILE) \
AWS_REGION=$(AWS_REGION) \
AWS_DEFAULT_REGION=$(AWS_DEFAULT_REGION) \
kops get cluster --name $(CLUSTER_NAME)安装过程: kops-cn目录下的Makefile文件. 您需要设置如下变量,见github https://github.com/nwcdlabs/kops-cn 必须修改的变量: KOPS_STATE_STORE:aws s3 mb s3://bucket-name命令可以创建一个s3桶 VPCID 留意pub key是authorized_keys
make create-cluster #创建群集 make edit-cluster #编辑集群,#将kops-cn目录下的 spec.yml 中内容贴到spec 下 并且在docker属性下配置子属性: docker: insecureRegistries:
ip和port为私有镜像仓库的ip和port
并保存退出。留意不能有额外或少空格 make edit-ig-nodes #可以设置spot # machineType: c5.large maxPrice: "0.9430"
$ make update-cluster #更新群集,这时候开始创建资源,包括子网,master,worker,autoscaling,ELB…
$ kops validate cluster #验证群集,要等ELB里面实例in-service后
$ make validate-cluster #验证群集用这个。。。 #需验证IAM权限 $ kubectl cluster-info $ kubectl version $ kubectl -n kube-system get po
YuTingLiu
commented
5 years ago @pahud node如果进入notready是不是应该会有记录不正常?现在新建一个集群,其它节点正常运行,某一个节点进入notready,应该是突然进入的,执行kubectl describe pod -n kube-system kube-proxy-ip-172-31-76-236.cn-northwest-1.compute.internal可以看到:
Normal Created 22m kubelet, ip-172-31-76-236.cn-northwest-1.compute.internal Created container
Normal Started 22m kubelet, ip-172-31-76-236.cn-northwest-1.compute.internal Started container
这是最后的记录。执行kubectl get pods --all-namespaces,可以看到:
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system aws-node-8s5hr 1/1 Running 1 17m
kube-system aws-node-h95fl 1/1 Running 2 17m
kube-system aws-node-n5hs8 1/1 Running 0 15m
kube-system aws-node-sldwc 1/1 Running 1 17m
kube-system aws-node-w8wn8 1/1 NodeLost 0 16m
没有重新启动尝试的记录。所以我不明白,问题卡在哪里?谢谢
pahud
commented
5 years ago Hi @YuTingLiu
我注意到你有些配置不是預設的default配置,包括
ifeq ($(TARGET_REGION) ,cn-north-1)
CLUSTER_NAME ?= cluster.bjs.xxx.k8s.loca
AMI ?= ami-0032227ab96e75a9f
ZONES ?= cn-north-1a,cn-north-1b
endif你的CLUSTER_NAME結尾是loca少了l, 這是不小心刪除了的嗎?如果不是k8s.local會有一些問題
另外
make edit-cluster #编辑集群,#将kops-cn目录下的 spec.yml 中内容贴到spec 下
并且在docker属性下配置子属性:
docker:
insecureRegistries:
- 52.82.110.118:5000看起來你大幅度修改了spec.yml內容,這會造成有一些images抓不下來,這部分應該是要完整copy/paste過去不做任何修改的。
能否完全使用kops-cn提供的官方README說明,最小程度修改,包括spec.yml完全不要修改內容,CLUSTER_NAME名稱也不要修改,重新看看是否問題還在?
YuTingLiu
commented
5 years ago @pahud 感谢回复, 第一个确实少l,但是部署在northwest,不影响。 我试了试你说的,仍然有notready的节点出现。但是稳定在一个node。如果是这样,目前不影响。 ` docker: insecureRegistries:
pahud
commented
5 years ago 如果你完全按照README裡面提供的範例來部署,應該cn-north-1 and cn-northwest-1 都會穩定所有node都READY才對,應該不會有些READY有些沒有READY。所以請全部都不要改動,只做必要的改動例如KOPS_STATE_STORE, VPCID, SSH_PUBLIC_KEY等,確保最小調整的情況下集群是穩定的,之後再慢慢修改你要的配置,觀察具體改了什麼造成集群故障,然後一步一步去定位問題。
spec.yml 裡面的內容不建議修改
https://github.com/nwcdlabs/kops-cn/blob/9a84d0185a80b1b5235ea992dd90cc201452555d/spec.yml#L2-L8
docker.registryMirrors 這裡定義的是所有docker hub images的抓取,統一往docker china public registry抓取, 如果移除或改成其他endpoint可能會有docker images無法抓取的問題.
docker.insecureRegistry 這個配置我沒測試過,看起來會讓所有docker image pulling指向自己的private registry,一旦private registry無法抓取就很有可能出現kops各種功能的問題。
YuTingLiu
commented
5 years ago @pahud 嗯,突然感到是不是现在只支持2个Node节点,我设置了三个node,所以一直有一个node会变为notready,但是这个配置下资源很快不够用,还没有部署服务,已经达到的资源用量为:

pahud
commented
5 years ago @YuTingLiu 我看到你部署了Istio
kops-cn default配置是沒有部署Istio的,如果只是起集群,什麼都沒有部署包括Istio,依然會有一個node無法READY嗎
pahud
commented
5 years ago 另外要注意的是, AWS VPC CNI每個node能運行的pod數量是有限的 https://github.com/awslabs/amazon-eks-ami/blob/32d2ac42612e6cff05df03e7be8094cfa9250da1/files/eni-max-pods.txt
以c4.large來說最多只能跑29 pods https://github.com/awslabs/amazon-eks-ami/blob/32d2ac42612e6cff05df03e7be8094cfa9250da1/files/eni-max-pods.txt#L26
從上面那張截圖來看你已經跑了29 pods, 這樣會有pod會無法被deploy上去
你可能要從這角度去查看一下。同時測試一下Istio不部署的話集群是否都能READY
YuTingLiu
commented
5 years ago @pahud 非常感谢回复,我明白了,问题的症结可能是这个限制。这样来看,我只能将instance type改大吗?
我试了新建一个node为c5.4xlarge的集群,一样会出现notready的节点。
 可以看到RESTART是0,说明丢失还是什么情况?
可以看到RESTART是0,说明丢失还是什么情况?
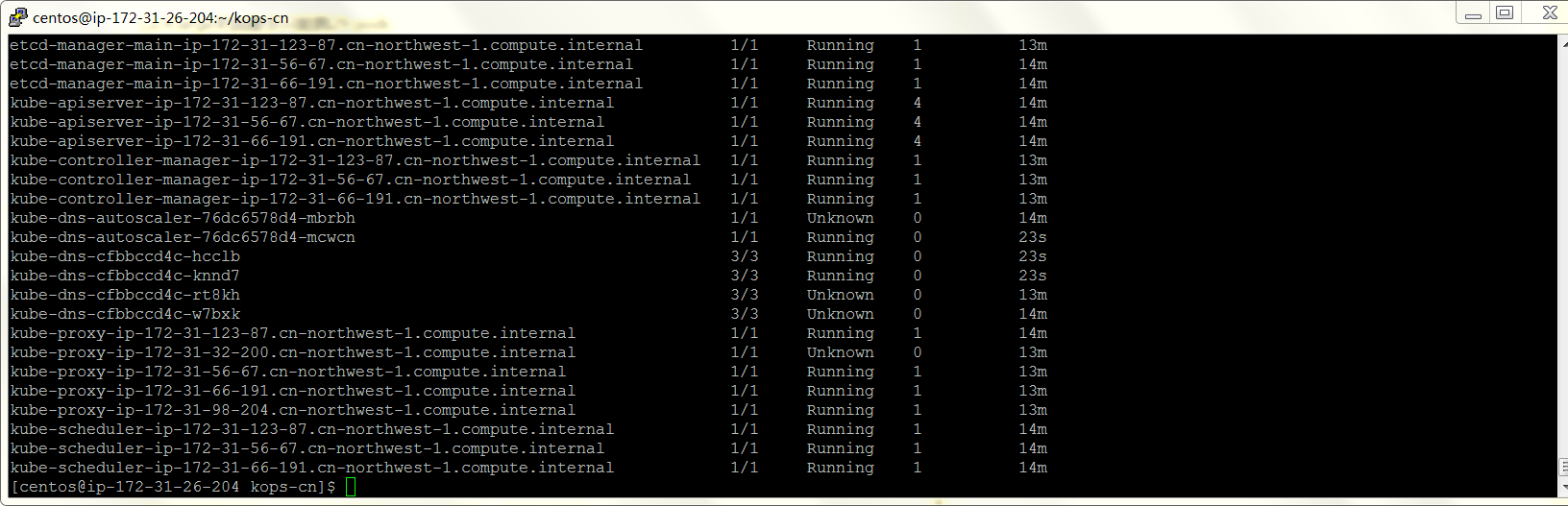 我应该是看到了kubectl尝试重启dns,proxy服务,显示ContaontainerCreating,但是失败了变为UNKONWN。
PS:昨天使用c2.xlarge刚开始是稳定的,所以是哪里不稳定?成功是概率?
我应该是看到了kubectl尝试重启dns,proxy服务,显示ContaontainerCreating,但是失败了变为UNKONWN。
PS:昨天使用c2.xlarge刚开始是稳定的,所以是哪里不稳定?成功是概率?
pahud
commented
5 years ago @YuTingLiu
你可以試著透過 kubectl logs -f po/<podname> 去查看指定的pod是否有什麼error log
或者
kubectl describe po/<podname> 查看pod是否遇到了什麼無法被deploy的事件。
aws-node是最重要的po,這是AWS VPC CNI,這個pod如果沒有順利部署成功的話,整個k8s的networking會出問題,後面連帶就會有很多其他pod例如kube-dns甚至Istio都會有問題。
希望上面這兩個命令可以幫助你盤查到底發生了什麼事。
 bigdrum
commented
5 years ago
bigdrum
commented
5 years ago Probably you can SSH to the host machine to read the system log.
YuTingLiu
commented
5 years ago Probably you can SSH to the host machine to read the system log.
大多数情况下,节点出现notready是无法ssh进入,正如我开头说的。 能够进入的情况下,一般来说,notready可能是节点在任务中,但是无任务也不ready的情况我也遇见过。
YuTingLiu
commented
5 years ago 感谢
YuTingLiu
commented
5 years ago  @pahud 这个问题只能再咨询您了,应该没有比您更了解了,经过与AWS技术支持人员沟通,发现确实不是AWS服务限制导致的slave进入NotReady,而是slave节点的网络接口(network interface)问题,实践上发现,应该是eth0能够ssh进入的,但是现在是eth1能够进入,eth0无法进入了,所以这个实例运行正常,k8s无法访问。
在Makefile中,我看到创建cluster时的命令为:
create-cluster:
@KOPS_STATE_STORE=$(KOPS_STATE_STORE) \
AWS_PROFILE=$(AWS_PROFILE) \
AWS_REGION=$(AWS_REGION) \
AWS_DEFAULT_REGION=$(AWS_DEFAULT_REGION) \
kops create cluster \
--cloud=aws \
--name=$(CLUSTER_NAME) \
--image=$(AMI) \
--zones=$(ZONES) \
--master-count=$(MASTER_COUNT) \
--master-size=$(MASTER_SIZE) \
--node-count=$(NODE_COUNT) \
--node-size=$(NODE_SIZE) \
--vpc=$(VPCID) \
--kubernetes-version=$(KUBERNETES_VERSION_URI) \
--networking=amazon-vpc-routed-eni \
--ssh-public-key=$(SSH_PUBLIC_KEY)
@pahud 这个问题只能再咨询您了,应该没有比您更了解了,经过与AWS技术支持人员沟通,发现确实不是AWS服务限制导致的slave进入NotReady,而是slave节点的网络接口(network interface)问题,实践上发现,应该是eth0能够ssh进入的,但是现在是eth1能够进入,eth0无法进入了,所以这个实例运行正常,k8s无法访问。
在Makefile中,我看到创建cluster时的命令为:
create-cluster:
@KOPS_STATE_STORE=$(KOPS_STATE_STORE) \
AWS_PROFILE=$(AWS_PROFILE) \
AWS_REGION=$(AWS_REGION) \
AWS_DEFAULT_REGION=$(AWS_DEFAULT_REGION) \
kops create cluster \
--cloud=aws \
--name=$(CLUSTER_NAME) \
--image=$(AMI) \
--zones=$(ZONES) \
--master-count=$(MASTER_COUNT) \
--master-size=$(MASTER_SIZE) \
--node-count=$(NODE_COUNT) \
--node-size=$(NODE_SIZE) \
--vpc=$(VPCID) \
--kubernetes-version=$(KUBERNETES_VERSION_URI) \
--networking=amazon-vpc-routed-eni \
--ssh-public-key=$(SSH_PUBLIC_KEY)
参考:https://github.com/kubernetes/kops/blob/master/docs/networking.md 我想请问是否是networking参数在中国区使用的问题?有没有其它参数可以使用? 谢谢
pahud
commented
5 years ago 很抱歉這個問題我現在也無法協助,kops-cn專案提供一個配置範例,讓大家根據這個範例可以很快速部署一個kops集群,但很可能因為各種原因出現一些issue,這個有些可能是kops上游的問題,有時候也會是Linux AMI問題,或者CNI的問題都有可能。
其他Networking參數只要kops上游支持,理論上cn都可以用,但有可能會缺少一些必要的docker images需要mirror進國內才行,具體需要哪些images就需要大家提PR貢獻了。
目前我們只能提供一個最小可運行的範例,如果還有遇到各種情況,就需要大家一起幫忙了。
 fc277073030
commented
5 years ago
fc277073030
commented
5 years ago 确实会有节点not ready,而且出现很频繁,看来大家都碰到这个问题了,希望作者有空解决一下
YuTingLiu
commented
5 years ago NETWORKING参数修改为:flannel-vxlan,可以临时解决问题,麻烦在于需要进入节点,自己更新镜像。
docker pull quay.io/coreos/flannel:v0.11.0-amd64 docker tag quay.io/coreos/flannel:v0.11.0-amd64 937788672844.dkr.ecr.cn-north-1.amazonaws.com.cn/quay.io-coreos-flannel:v0.11.0-amd64
 liualexiang
commented
5 years ago
liualexiang
commented
5 years ago 出现节点NotReady是由于默认的镜像CoreOS对AWS平台多网卡支持不好,只有eth0能通信,eth1或者eth0的其他网卡都不能通信,所以如果Node跟API Server之间用了其他非eth0的主IP,就会出现NotReady的情况。
解决办法: 在Makefile中,将Image修改为Amazon Linux 2的ami即可解决问题
pahud
commented
5 years ago @liualexiang 感謝,Amazon Linux 2 AMI之前有遇過其他問題 https://github.com/nwcdlabs/kops-cn/issues/47#issuecomment-454648298
不知道現在情況如何,just FYI
 MMichael-S
commented
5 years ago
MMichael-S
commented
5 years ago 我也遇到使用coreos作为k8s node时的类似问题,经过试验发现如下情况供参考: 通过kops在ZHY部署k8s,使用amazon-vpc-cni-k8s网络,node绑定多个ENI coreos实例在启动后会有一次自动重新启动,而重新启动后路由优先级变化为eth1优先(通过ip route可见),之后node上的pod会报告异常。 journalctl -f 可见错误信息: error querying AWS metadata for "network/interfaces/macs": "RequestError: send request failed\ncaused by: Get http://169.254.169.254/latest/meta-data/network/interfaces/macs .... connection error: desc = \"transport: Error while dialing dial tcp [::1]:50051: connect: connection refused\"" 同时ssh登录node原主私有IP会失败。
基本可确定为coreos上跟systemd有关的bug,但均未close。 https://github.com/coreos/bugs/issues/992 https://github.com/aws/amazon-vpc-cni-k8s/issues/266 https://github.com/aws/amazon-vpc-cni-k8s/issues/345
目前查到的Workaround为: sudo vim /etc/systemd/network/10-eth0-default-pref.network 修改eth0 的属性RouteMetric=512 保证优先级 sudo vim /etc/systemd/network/10-eth0-default-pref.network [Match] Name=eth0 [Network] DHCP=ipv4 [DHCP] RouteMetric=512
之后重新启动node正常。
MMichael-S
commented
5 years ago 补充说明一点,我测试了最新可用的coreos ami问题依旧。 更换为centos之后,运行了一段时间未出现同样问题。 在ZHY建议使用marketplace中的 “CentOS 7 (x86_64) – with Updates HVM” AMI,目前已经可以支持最新一代Nitro的机型。
pahud
commented
5 years ago @MMichael-S 感謝!
看起來我們配置範例可能要考慮換成CentOS了,畢竟Marketplace已經有這個AMI可以用了。
歡迎大家多多測試。
 liangruibupt
commented
5 years ago
liangruibupt
commented
5 years ago @liualexiang 感謝,Amazon Linux 2 AMI之前有遇過其他問題 #47 (comment)
不知道現在情況如何,just FYI
我昨天也遇到类似问题,使用默认的MakeFile,按照要求修改,运行1个小时之后NotReady,采用Amazon Linux2 BJS最新版本,没有再复现这个问题
pahud
commented
5 years ago 我剛剛在寧夏Region用這方式跑起來CentOS AMI
AMI=ami-0df732b66b1665c54 make create-cluster看起來一切正常



pahud
commented
5 years ago 跑最新Amazon Linux 2 AMI看起來沒問題
寧夏Region這樣跑
AMI=ami-0829e595217a759b9 make create-cluster建議大家優先試試看Amaozn Linux 2 AMI,如果沒問題的話,我們考慮換成Amazon Linux 2 AMI
liangruibupt
commented
5 years ago 跑最新Amazon Linux 2 AMI看起來沒問題
寧夏Region這樣跑
AMI=ami-0829e595217a759b9 make create-cluster建議大家優先試試看Amaozn Linux 2 AMI,如果沒問題的話,我們考慮換成Amazon Linux 2 AMI
估计是和CNI兼容问题,集群跑一段时间之后,dns出现问题 kube-dns-cfbbccd4c-7wh4p 0/3 CrashLoopBackOff 565 15h kube-dns-cfbbccd4c-8pg7c 0/3 CrashLoopBackOff 570 15h
目前看Ubuntu Server 16.04 LTS (HVM) 暂时没有发现问题 BJS: AMI=ami-05bf8d3ead843c270 make create-cluster
liualexiang
commented
5 years ago @liualexiang 感謝,Amazon Linux 2 AMI之前有遇過其他問題 #47 (comment)
不知道現在情況如何,just FYI
经多次频繁测试,虽然使用Amazon Linux 2不会遇到node NotReady情况,但是在集群启动半个小时之后,kube-DNS会出现crash的情况,整个集群的cluster ip不可达,部署的service无法正常访问。
目前发现使用Ubuntu 16.04,或者使用社区版k8镜像可以解决(在北京区和宁夏区分别测试,创建LB类型的svc,公网可成功访问)。
已成功测试的镜像(集群跑了将近20小时未发现异常): 北京区k8s debian发行版:(ami-076828ef599fb3764) 宁夏区ubuntu 16.04:(ami-09081e8e3d61f4b9e)
pahud
commented
5 years ago @liualexiang 如果kops 官方debian ami and Ubuntu都沒問題的話,可能跟隨上游使用debian比較好
https://github.com/nwcdlabs/kops-cn/issues/96
我們在這邊討論AMI更換的事情吧!
没有人发布这个问题?貌似这个是AWS中经常碰到的问题。 之前使用master:t2.medium,node:t2.large,并不会经常出现这个问题。现在回忆起来,时间不定,进入notready状态。 现在使用m4.large之后,这个问题稳定出现。
配置: kops-cn标准配置,istio.
目前解决方案:
可能的解决方案 https://kubernetes.io/docs/tasks/debug-application-cluster/monitor-node-health/,记录节点出现问题的log。 https://github.com/awslabs/amazon-eks-ami/issues/79
期待 能够在配置上做到:监控节点状态,如果出现NOTREADY,则5min之后,重新调度