 jbusecke
commented
3 years ago
jbusecke
commented
3 years ago From some of the initial interactions in #2 I got curious and started reading into the 'Optimization' chapter of the desk docs. I think not being able to diagnose/understand what is going on on that level really prevents me from identifying problems in a more concise manner.
I would like to learn more how I can inspect the task graph. I was able to go through the docs and I think I understand the steps on a basic level, but on a practical level I am not quite sure how to expose the graph from within an array dataset. Given the example above, how do I get to the dask graph leading to a final chunk?
I have tried
da = ds.simple.isel(time=0, x=0, y=0).data
dict(da.dask)but I think that still gives me the full dask graph for the entire array (its a huuuge dict)? If I try to .visualize() it, the output is not useable. Could I apply cull to this to see just the tasks leading to my selection or am I completely misunderstanding this?
 jrbourbeau
jrbourbeau mrocklin
mrocklin
In this issue I am trying to come up with a somewhat 'canonical' example of a workflow that I keep having trouble with when working on large climate model data.
A typical workflow for ocean model data
At the very basic level most of (at least my) workflows can be broken down into three steps.
Many of the problems I have encountered in the past are certainly related to more complex processing steps (2.) but I find that most of the time there is nothing that inherently breaks the processing, rather it seems that dask is just blowing up the available memory by starting to work on too many tasks at once if the dataset reaches a certain size.
I came up with this example, using xarray+dask, which hopefully illustrates my problem:
Working in the pangeo cloud deployment on a 'large' server, I first set up a dask gateway cluster and the pangeo scratch bucket:
Then I create a very simple synthetic dataset
And just save it out to the pangeo cloud scratch bucket.
This works as I would expect, showing low memory usage and a dense task graph: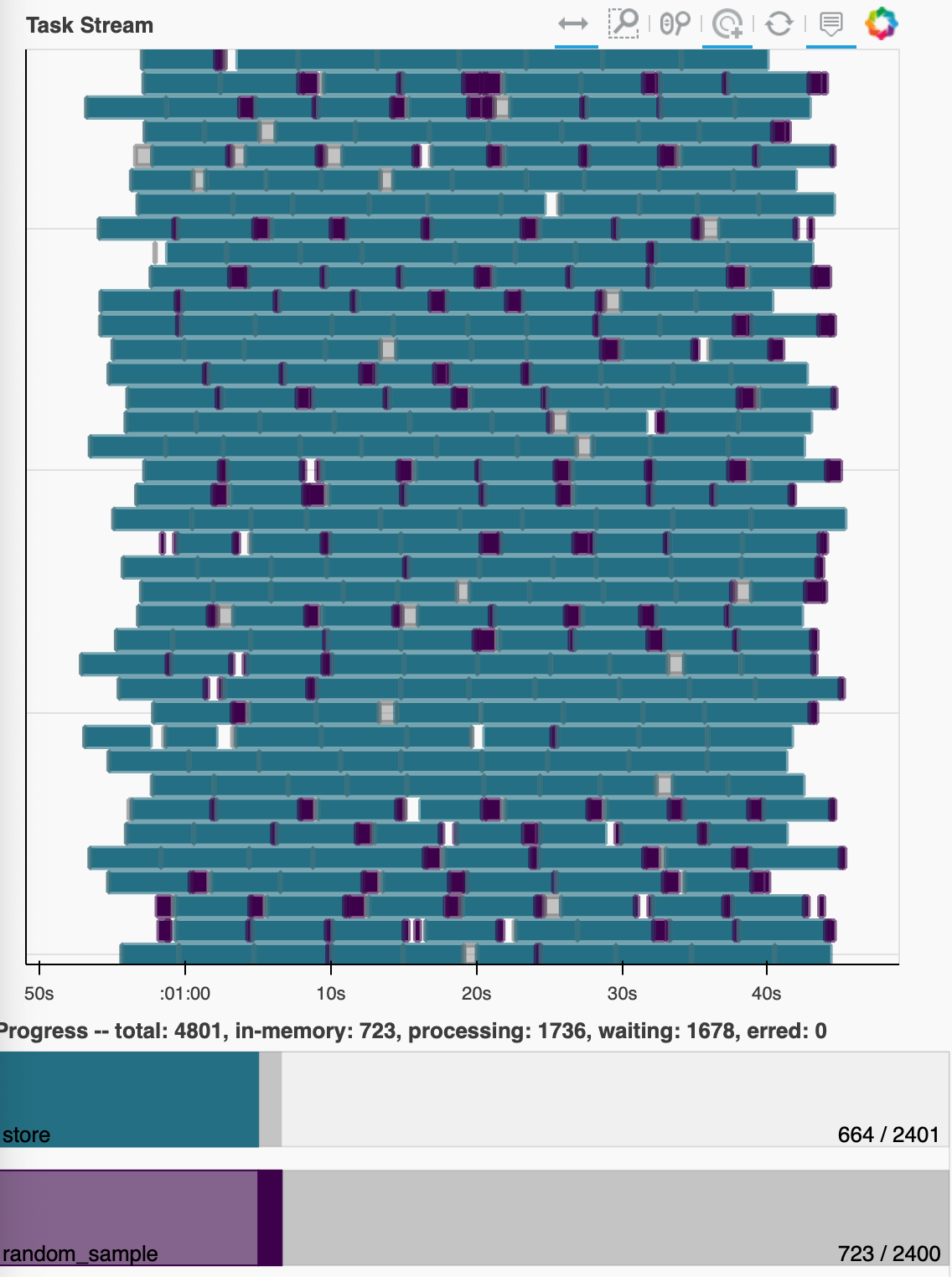
If this scales properly I would expect a dataset that is chunked the same way, just has more chunks along the time dimension to process in the same smooth way (with execution time proportional to the increase along the time axis). But when I simply double the time chunks
I start seeing very high memory load and buffering to disk? (not actually sure where these dask workers are writing their temp data to):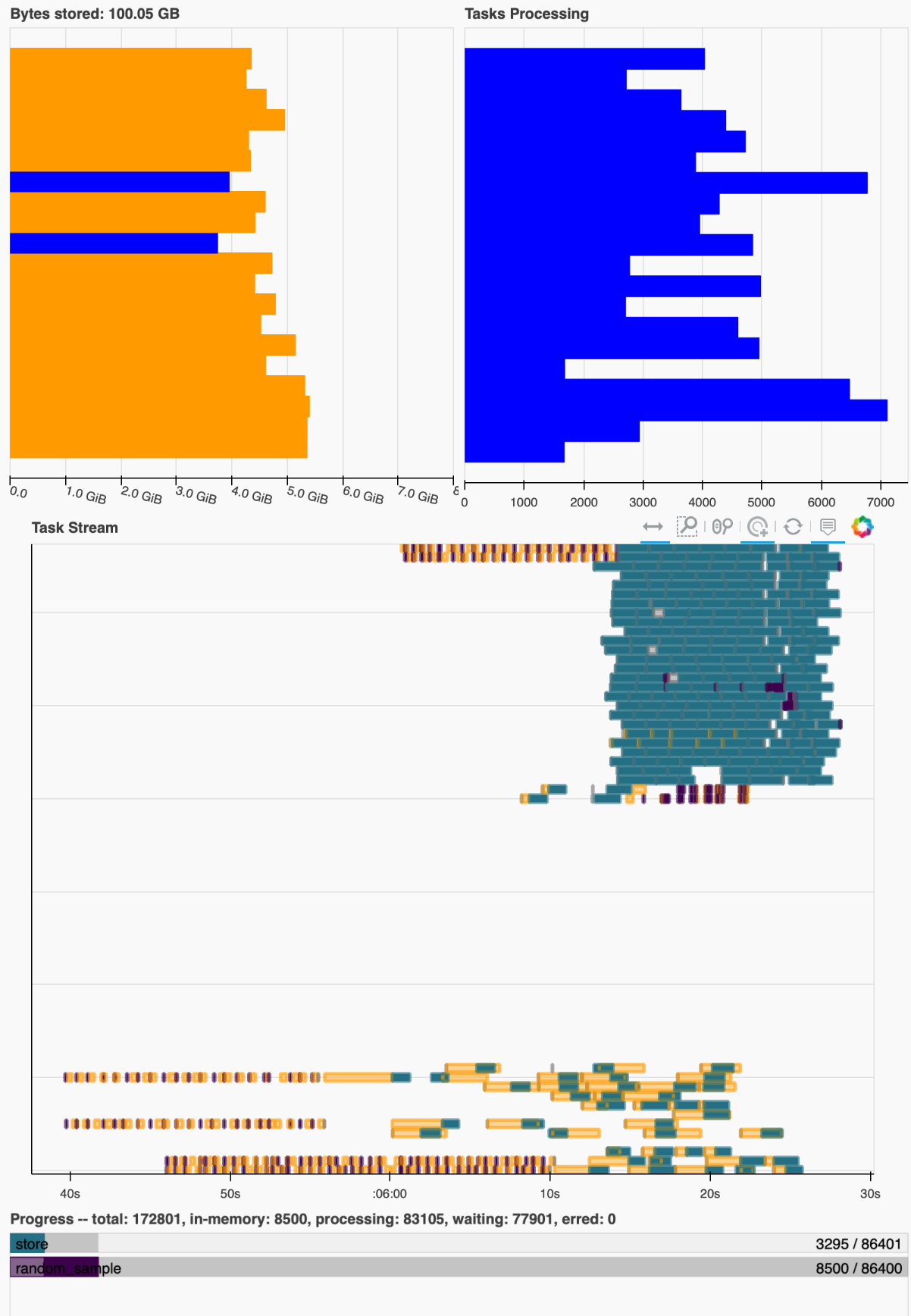
The task graph seems to recover periodically and then go back into a situation like this and the timing suggests that this does take approximately double as long as the previous dataset.
it gets worse when I add even more time chunks, to the point where the computation crashes out some times. As mentioned in #2, it is not uncommon to work with such large datasets, e.g. multi centuries-long control runs.
To put this in perspective, dealing with issues like this, and coming up with everchanging 'ugly' solutions like looping over smaller time slices, etc, has taken up a considerable amount of my work hours in the past months/years. A solution to this would be an absolute godsend to my scientific productivity.
I have had some success with manually throttling my dask workers on HPC clusters (e.g. reducing the number of workers on a node, and thus allocating very large amounts of memory to each), but I have the feeling (and I might be completely wrong and naive) that there should be a way to 'limit' the number of tasks that are started (maybe along a custom dimension which could be determined by e.g. xarray)?
I would certainly be willing to sacrifice speed for reliability (in this case reliability=less probability that the whole cluster dies because the workers run out of memory). Also note that this example is the absolute simplest way to work with a model dataset, which does not even involve applying any processing steps. The addition of masking, coordinate transformation and other things highly amplifies this problem.
I am more than happy to do further testing, and please correct any of my vocabulary or assumptions above, as I am sure I have some of these things wrong.
P.S.: I know there was a discussion about adding the concept of 'memory pressure' started by @rabernat I believe, but I cannot find it at the moment.