 odow
commented
1 year ago
odow
commented
1 year ago using SDDP
import Ipopt
function main()
δ, ρ = 0.1, 0.05
β = 1 / (1 + ρ)
graph = SDDP.LinearGraph(1)
SDDP.add_edge(graph, 1 => 1, β)
model = SDDP.PolicyGraph(
graph;
sense = :Max,
upper_bound = 1000,
optimizer = Ipopt.Optimizer,
) do sp, _
z = ρ + δ + 0.02
u_SS = (z - ρ - δ) / (ρ + δ)
x_SS = u_SS / δ
x0 = 0.5 * x_SS
@variable(sp, x, SDDP.State, initial_value = x0)
@variable(sp, u)
@constraint(sp, x.out == (1 - δ) * x.in + u)
@stageobjective(sp, z * x.in - u - 0.5 * u^2)
return
end
SDDP.train(model; iteration_limit = 50)
sims = SDDP.simulate(
model,
1,
[:x, :u];
sampling_scheme = SDDP.Historical([(1, nothing) for t in 1:100])
)
return map(sims[1]) do data
return Dict(:u => data[:u], :x => data[:x].out)
end
endyields
100-element Vector{Dict{Symbol, Float64}}:
Dict(:u => 0.13333333331362393, :x => 0.7333333333136239)
Dict(:u => 0.13333333331362374, :x => 0.7933333332958853)
Dict(:u => 0.13333333331362351, :x => 0.8473333332799203)
Dict(:u => 0.13333333331362318, :x => 0.8959333332655515)
Dict(:u => 0.13333333331362332, :x => 0.9396733332526196)
Dict(:u => 0.1333333333136231, :x => 0.9790393332409807)
Dict(:u => 0.13333333331362282, :x => 1.0144687332305053)
Dict(:u => 0.13333333331362288, :x => 1.0463551932210777)
Dict(:u => 0.1333333333136227, :x => 1.0750530072125926)
Dict(:u => 0.13333333331362265, :x => 1.100881039804956)
Dict(:u => 0.13333333331362265, :x => 1.1241262691380831)
Dict(:u => 0.13333333331362265, :x => 1.1450469755378974)
Dict(:u => 0.13333333331362238, :x => 1.16387561129773)
Dict(:u => 0.13333333331362252, :x => 1.1808213834815795)
Dict(:u => 0.13333333331362257, :x => 1.1960725784470443)
Dict(:u => 0.1333333333136224, :x => 1.2097986539159622)
Dict(:u => 0.1333333333136224, :x => 1.2221521218379885)
Dict(:u => 0.13333333331362215, :x => 1.233270242967812)
Dict(:u => 0.13333333331362232, :x => 1.2432765519846531)
Dict(:u => 0.1333333333136223, :x => 1.2522822300998102)
Dict(:u => 0.1333333333136222, :x => 1.2603873404034514)
Dict(:u => 0.13333333331362213, :x => 1.2676819396767285)
Dict(:u => 0.13333333331362227, :x => 1.2742470790226779)
Dict(:u => 0.1333333333136221, :x => 1.2801557044340324)
Dict(:u => 0.13333333331362224, :x => 1.2854734673042514)
Dict(:u => 0.1333333333136221, :x => 1.2902594538874486)
Dict(:u => 0.13333333331362215, :x => 1.294566841812326)
⋮
Dict(:u => 0.13333333331362204, :x => 1.33308667414627)
Dict(:u => 0.13333333331362204, :x => 1.333111340045265)
Dict(:u => 0.13333333331362213, :x => 1.3331335393543606)
Dict(:u => 0.13333333331362204, :x => 1.3331535187325465)
Dict(:u => 0.13333333331362185, :x => 1.3331715001729136)
Dict(:u => 0.13333333331362204, :x => 1.3331876834692442)
Dict(:u => 0.13333333331362188, :x => 1.3332022484359418)
Dict(:u => 0.13333333331362188, :x => 1.3332153569059697)
Dict(:u => 0.13333333331362182, :x => 1.3332271545289944)
Dict(:u => 0.13333333331362174, :x => 1.3332377723897169)
Dict(:u => 0.13333333331362196, :x => 1.333247328464367)
Dict(:u => 0.13333333331362188, :x => 1.3332559289315524)
Dict(:u => 0.13333333331362202, :x => 1.3332636693520192)
Dict(:u => 0.13333333331362207, :x => 1.3332706357304394)
Dict(:u => 0.13333333331362193, :x => 1.3332769054710174)
Dict(:u => 0.13333333331362202, :x => 1.3332825482375377)
Dict(:u => 0.133333333313622, :x => 1.3332876267274059)
Dict(:u => 0.13333333331362204, :x => 1.3332921973682872)
Dict(:u => 0.13333333331362193, :x => 1.3332963109450804)
Dict(:u => 0.13333333331362182, :x => 1.333300013164194)
Dict(:u => 0.13333333331362185, :x => 1.3333033451613967)
Dict(:u => 0.13333333331362188, :x => 1.333306343958879)
Dict(:u => 0.13333333331362182, :x => 1.333309042876613)
Dict(:u => 0.13333333331362193, :x => 1.3333114719025736)
Dict(:u => 0.13333333331362185, :x => 1.3333136580259382)
Dict(:u => 0.13333333331362193, :x => 1.3333156255369663)which looks like the solution from https://discourse.julialang.org/t/solving-the-4-quadrants-of-dynamic-optimization-problems-in-julia-help-wanted/73285/28?u=odow.
SDDP.jl is overkill for this sort of problem though. It's not what it was designed for.
 azev77
azev77
Hi, can you please help me solve the following problem with SDDP.jl using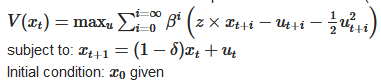 I use the following parameters:
I use the following parameters:
Ipoptor another open-source solver:I spent some time trying and was not able to get it to work...