 BadisG
commented
1 year ago
BadisG
commented
1 year ago Can we save the quantized version at the end? Or do we need the f16 all the time to make it work?
Closed oobabooga closed 1 year ago
BadisG
commented
1 year ago Can we save the quantized version at the end? Or do we need the f16 all the time to make it work?
 AlpinDale
commented
1 year ago
AlpinDale
commented
1 year ago Good work! As for the slow inference speed, it's expected to be fixed soon (tvvo more vveeks!)
The 4bit inference kernels need more work, since Tim is working on CUDA code for matmul using the NF4 datatype, which isn't supported by current hardware.
BadisG
commented
1 year ago Is there a way to force it to not swap when we have enough RAM? (Using WSL2)
BadisG
commented
1 year ago Good work! As for the slow inference speed, it's expected to be fixed soon (tvvo more vveeks!)
I have 2tokens/s for the moment (5 times slower than GPTQ) but if what Tim says is true then we could get good final speed at the end
AlpinDale
commented
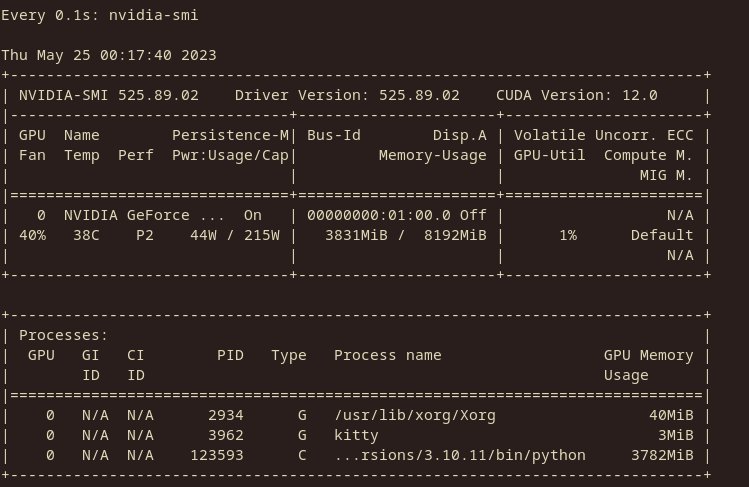
1 year ago Memory usage report GPU: NVIDIA RTX 2070S 8GB Model: RedPajama-INCITE-3B-v1
--load-in-8bit
--load-in-4bit
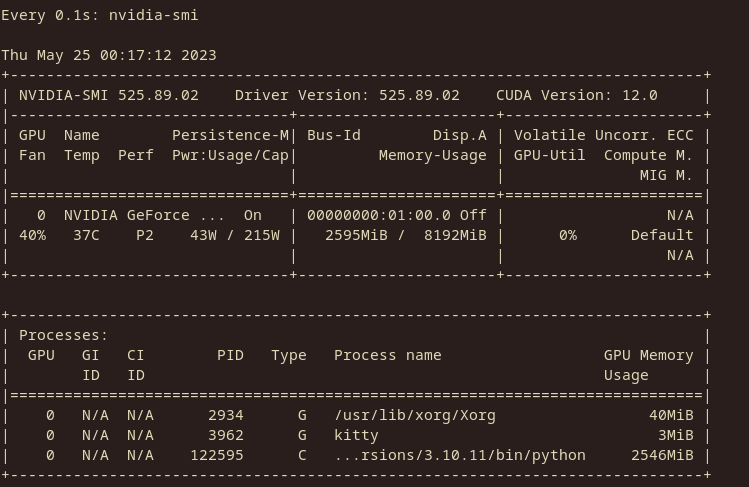
There seems to be a roughly 33% decrease in VRAM usage. The context is currently empty, so that's how much it takes to load the 3B model.
UPDATE: Slight decrease with nf4 data type:
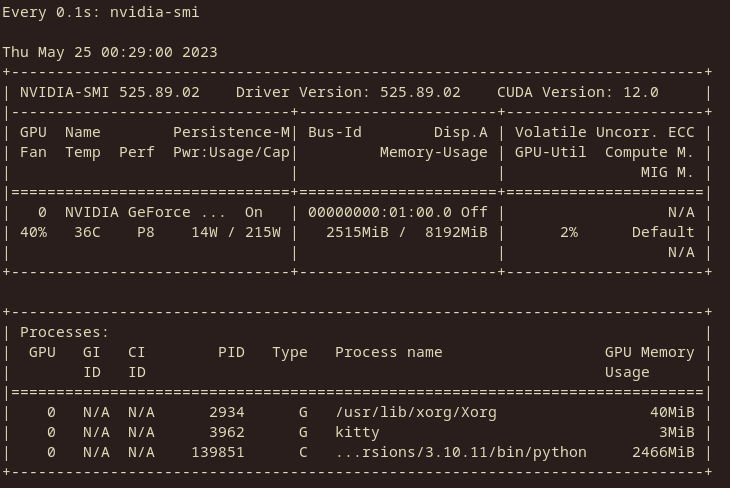
GPTQ 4bit (no groupsize) for comparison:
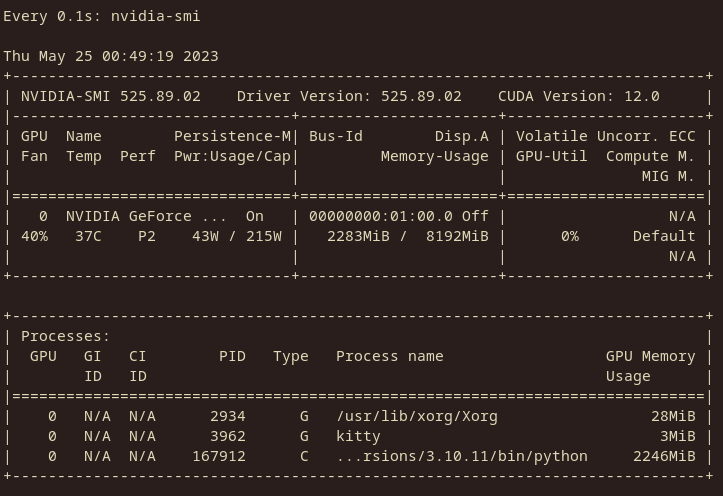
Seems to have a ~9.8% increase in VRAM usage over GPTQ.
AlpinDale
commented
1 year ago I recommend using the float16 datatype for models trained in FP16 (e.g. RedPajama). No change in memory usage of course, but it might improve generation speed and accuracy:
Speed with the NF4 datatype and float16:

BadisG
commented
1 year ago I recommend using the float16 datatype for models trained in FP16 (e.g. RedPajama).
Aren't the finetunes of llama also in 16bit?
AlpinDale
commented
1 year ago I recommend using the float16 datatype for models trained in FP16 (e.g. RedPajama).
Aren't the finetunes of llama also in 16bit?
Yes, though a few fine-tunes (such as Pygmalion-7B) are in BF16.
BadisG
commented
1 year ago I don't think there's a use in loading in 32bit as it has no loss precision between the 32bit and 16bit, in llama.cpp they always use f16 as the reference for example.
 USBhost
commented
1 year ago
USBhost
commented
1 year ago Since no one is talking about 33b Loaded VRAM usage: 18088MiB GPTQ no groupsize 18054MiB NF4 double quant 18054MiB FP4 double quant
 oobabooga
commented
1 year ago
oobabooga
commented
1 year ago @BadisG
Can we save the quantized version at the end? Or do we need the f16 all the time to make it work?
I haven't tried, but probably not (models loaded with --load-in-8bit used to refuse to be saved due to the presence of a CPU offload)
@AlpinDale
Good work! As for the slow inference speed, it's expected to be fixed soon (tvvo more vveeks!)
The 4bit inference kernels need more work, since Tim is working on CUDA code for matmul using the NF4 datatype, which isn't supported by current hardware.
This is encouraging to hear. I think that this has the potential to become the new meta for inference if speed becomes competitive with GPTQ.
I recommend using the float16 datatype for models trained in FP16 (e.g. RedPajama). No change in memory usage of course, but it might improve generation speed and accuracy:
There are several mentions to bfloat16 in the blog post, so I set that as the default. It seems like the choice between float16/float32/bfloat16 in compute_dtype doesn't change the perplexity at all. I have added command-line arguments and UI dropdowns/checkboxes to customize all of the 3 new parameters.
I'll merge the PR, if anyone notices something off please let me know.
 jllllll
commented
1 year ago
jllllll
commented
1 year ago @oobabooga
Just letting you know that I have compiled a Windows wheel for 0.39.0: https://github.com/jllllll/bitsandbytes-windows-webui/raw/main/bitsandbytes-0.39.0-py3-none-any.whl
Unfortunately, it does not support pre-Volta cards (less than 7.0 compute). This is, presumably, due to the use of code in the kernels that the Windows Cuda Toolkit does not support on older architectures. I am unable to test it as a result, since I have a 1080ti.
BadisG
commented
1 year ago https://www.reddit.com/r/LocalLLaMA/comments/13r7pzg/gptqlora_efficient_finetuning_of_quantized_llms/
According to this, GPTQ is still better than nf4, so there's not really a reason to use the load-in-4bit instead of using a gptq safetensor
And it looks like the double quant doesn't do anything to the perplexity
oobabooga
commented
1 year ago @jllllll I have tested your 3.29.0 wheel on Windows and it worked fine with --load-in-4bit on a GTX 1650, so I have:
1) Removed the bitsandbytes installation step from the one-click-installers: https://github.com/oobabooga/one-click-installers/commit/996c49daa75abf3b485e1b6b3074b117084c9e3e 2) Added your wheel directly to the requirements.txt here: https://github.com/oobabooga/text-generation-webui/commit/548f05e106ec41aa58adc6bcb1ff88116c0750c4 3) Added a note about bitsandbytes on older GPUs to the README: https://github.com/oobabooga/text-generation-webui/#note-about-bitsandbytes
This is a proof of concept that requires the latest transformers/accelerate/bitsandbytes:
Usage
Load a 16-bit model with
--load-in-4bit, egPerplexity/speed
In a small, unreliable, and preliminary test that I made, perplexity seems lower for llama-7b and the same for llama-13b compared to the old cuda gptq-for-llama branch. Speed seems slower.
When
bnb_4bit_quant_type="nf4"is used, perplexity seems to drop further and become lower than old cuda for 13b.Note that the quantization is done on the fly contrary to gptq, and it works in principle for any hugging face model.