 HAMA-DL-dev
commented
1 year ago
HAMA-DL-dev
commented
1 year ago I found what is the problem, and it was my mistake. The proposal file's each array was 'str', not <class 'np.array'>. After modify auto-annotation tool and re-made proposal_file.pkl, I succeed training model somewhat.
The next problem is that, when I run command $python tools/train.py configs/{my_configs} --validate, training process stops like below.

I set the variable 'videos_per_gpu = 1', 'workers_per_gpu=4'. Because I find the issue that mmaction2 do not support multi-batch testing for Spatio-temporal detection now. (link)
Anyway, the error message is this.

I didn't set the variable det_score_thr, so I added the variable 'car_det_score_thr'. I paste my latest code for configs and dataset just in case.
code
my_custom_configs.py
"""
model setting from https://github.com/open-mmlab/mmaction2/blob/master/configs/detection/ava/slowfast_kinetics_pretrained_r50_4x16x1_20e_ava_rgb.py
1. You need to generate frames at a higher fps (24 or 30), but annotate them at 1 fps
2. For ann_file_train & ann_file_val, you should check the annotations on ur own, each line in the ann file should be: video_id, second_id, bbox [length is 4], action class id, person id
3. You don't need to generate exclude files.
4. The label file stores the map from action class id to action class name.
The proposal file is the detection result of ur dataset organized as a dictionary, the key is 'video_id, second_id', the value is human bounding boxes.
"""
custom_classes=[1,2]
num_classes=len(custom_classes)+1
model = dict(
type='FastRCNN',
backbone=dict(
type='ResNet3dSlowFast',
pretrained=None,
resample_rate=8,
speed_ratio=8,
channel_ratio=8,
slow_pathway=dict(
type='resnet3d',
depth=50,
pretrained=None,
lateral=True,
conv1_kernel=(1, 7, 7),
dilations=(1, 1, 1, 1),
conv1_stride_t=1,
pool1_stride_t=1,
inflate=(0, 0, 1, 1),
spatial_strides=(1, 2, 2, 1)),
fast_pathway=dict(
type='resnet3d',
depth=50,
pretrained=None,
lateral=False,
base_channels=8,
conv1_kernel=(5, 7, 7),
conv1_stride_t=1,
pool1_stride_t=1,
spatial_strides=(1, 2, 2, 1))),
roi_head=dict(
type='AVARoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor3D',
roi_layer_type='RoIAlign',
output_size=8,
with_temporal_pool=True),
bbox_head=dict(
type='BBoxHeadAVA',
in_channels=2304,
num_classes=3,
multilabel=True,
dropout_ratio=0.5)),
train_cfg=dict(
rcnn=dict(
assigner=dict(
type='MaxIoUAssignerAVA',
pos_iou_thr=0.9,
neg_iou_thr=0.9,
min_pos_iou=0.9),
sampler=dict(
type='RandomSampler',
num=1,
pos_fraction=1,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=1.0,
debug=False)),
test_cfg=dict(rcnn=dict(action_thr=0.002)))
dataset_type = 'MoraiDataset' # name of dataset which has been defined at datasets/__init__.py
data_root = 'data/TL/rawframes'
anno_root = 'data/TL/annotations'
## each line of the ann file should be: video_id, second_id, bbox [length is 4], action class id, person id
## (example) : zlVkeKC6Ha8,1798,0.568,0.312,0.953,0.926,74,215
ann_file = f'{anno_root}/annotation.txt'
ann_file_train = f'{anno_root}/train_list.txt'
ann_file_val = f'{anno_root}/val_list.txt'
label_file=f'{anno_root}/class_list.pbtxt'
## The proposal file is the detection result of ur dataset organized as a dictionary, the key is 'video_id, second_id', the value is human bounding boxes. 'second_id' is same as timestamp.
## (example) {'1j20qq1JyX4,0902': array([[0.036 , 0.098 , 0.55 , 0.979 , 0.995518],[0.443 , 0.04 , 0.99 , 0.989 , 0.977824]])
## 동일한 timestamp 내에서 검출되는 bounding box 좌표를 array화 하여 dictionary 형태로 변형한 것.
proposal_file_train = f'{anno_root}/proposal_file.pkl'
proposal_file_val = f'{anno_root}/proposal_file.pkl'
# Added below
exclude_file_train=f'{anno_root}/train_exclued_timestamps.csv'
exclude_file_val=f'{anno_root}/val_exclued_timestamps.csv'
gpu_ids=[0]
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_bgr=False)
train_pipeline = [
dict(type='SampleAVAFrames', clip_len=32, frame_interval=2),
dict(type='RawFrameDecode'),
dict(type='RandomRescale', scale_range=(256, 320)),
dict(type='RandomCrop', size=256),
dict(type='Flip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='FormatShape', input_format='NCTHW', collapse=True),
# Rename is needed to use mmdet detectors
dict(type='Rename', mapping=dict(imgs='img')),
dict(type='ToTensor', keys=['img', 'proposals', 'gt_bboxes', 'gt_labels']),
# dict(type='ToTensor', keys=['img', 'proposals']),
dict(
type='ToDataContainer',
fields=[
dict(key=['proposals', 'gt_bboxes', 'gt_labels'], stack=False)
]),
dict(
type='Collect',
keys=['img', 'proposals', 'gt_bboxes', 'gt_labels'],
meta_keys=['scores', 'entity_ids'])
]
# The testing is w/o. any cropping / flipping
val_pipeline = [
dict(
type='SampleAVAFrames', clip_len=32, frame_interval=2, test_mode=True),
dict(type='RawFrameDecode'),
dict(type='Resize', scale=(-1, 256)),
dict(type='Normalize', **img_norm_cfg),
dict(type='FormatShape', input_format='NCTHW', collapse=True),
# Rename is needed to use mmdet detectors
dict(type='Rename', mapping=dict(imgs='img')),
dict(type='ToTensor', keys=['img', 'proposals']),
dict(type='ToDataContainer', fields=[dict(key='proposals', stack=False)]),
dict(
type='Collect',
keys=['img', 'proposals'],
meta_keys=['scores', 'img_shape'],
nested=True)
]
data = dict(
videos_per_gpu=1, # mini-batch size
workers_per_gpu=4, # if you set this zero, it means "do not use multi-thread"
val_dataloader=dict(videos_per_gpu=1),
test_dataloader=dict(videos_per_gpu=1),
train=dict(
type=dataset_type,
ann_file=ann_file_train,
# exclude_file=exclude_file_train,
pipeline=train_pipeline,
label_file=label_file,
car_det_score_thr=0.8,
proposal_file=proposal_file_train,
num_classes=num_classes,
# custom_classes=custom_classes,
data_prefix=data_root),
val=dict(
type=dataset_type,
ann_file=ann_file_val,
# exclude_file=exclude_file_val,
pipeline=val_pipeline,
label_file=label_file,
car_det_score_thr=0.8,
proposal_file=proposal_file_train,
num_classes=num_classes,
# custom_classes=custom_classes,
data_prefix=data_root))
data['test'] = data['val']
optimizer = dict(type='SGD', lr=0.1125, momentum=0.9, weight_decay=0.00001)
# this lr is used for 8 gpus
optimizer_config = dict(grad_clip=dict(max_norm=40, norm_type=2))
# learning policy
lr_config = dict(
policy='step',
step=[10, 15],
warmup='linear',
warmup_by_epoch=True,
warmup_iters=5,
warmup_ratio=0.1)
total_epochs = 10
checkpoint_config = dict(interval=1)
workflow = [('train', 1)]
evaluation = dict(interval=1, save_best='mAP@0.5IOU')
log_config = dict(
interval=20, hooks=[
dict(type='TextLoggerHook'),
])
dist_params = dict(backend='nccl')
log_level = 'INFO'
work_dir = ('./result/'
'test')
load_from = None
resume_from = Nonemy_dataset.py
# Copyright (c) OpenMMLab. All rights reserved.
import copy
import os
import os.path as osp
from collections import defaultdict
from datetime import datetime
import mmcv
import numpy as np
from mmcv.utils import print_log
from ..core.evaluation.ava_utils import ava_eval, read_labelmap, results2csv
from ..utils import get_root_logger
from .base import BaseDataset
from .builder import DATASETS
@DATASETS.register_module()
class MoraiDataset(BaseDataset):
def __init__(self,
ann_file,
pipeline,
label_file=None,
data_prefix=None,
test_mode=False,
filename_tmpl='{:04}.png',
start_index=1,
proposal_file=None,
car_det_score_thr=0.8,
num_classes=3,
custom_classes=None,
modality='RGB',
num_max_proposals = 29,
timestamp_start=0,
timestamp_end=90,
fps=30
):
self._FPS = fps
self.custom_classes=custom_classes
if custom_classes is not None:
assert num_classes == len(custom_classes) + 1
assert 0 not in custom_classes
self.custom_classes = tuple([0] + custom_classes)
self.proposal_file = proposal_file
self.filename_tmpl = filename_tmpl
self.num_classes = num_classes
self.car_det_score_thr = car_det_score_thr
self.num_max_proposals = num_max_proposals
self.timestamp_start = timestamp_start
self.timestamp_end = timestamp_end
self.logger = get_root_logger()
# super(MoraiDataset, self).__init__(ann_file, pipeline, test_mode)
super().__init__(
ann_file,
pipeline,
data_prefix,
test_mode,
start_index=start_index,
modality=modality,
num_classes=num_classes)
if self.proposal_file is not None:
self.proposals = mmcv.load(self.proposal_file)
else:
self.proposals = None
def parse_img_record(self, img_records):
"""Merge image records of the same entity at the same time.
Args:
img_records (list[dict]): List of img_records (lines in AVA
annotations).
Returns:
tuple(list): A tuple consists of lists of bboxes, action labels and
entity_ids
"""
bboxes, labels, entity_ids = [], [], []
while len(img_records) > 0:
img_record = img_records[0]
num_img_records = len(img_records)
selected_records = [
x for x in img_records
if np.array_equal(x['entity_box'], img_record['entity_box'])
]
## ## ##
## print(selected_records)
## ## ##
num_selected_records = len(selected_records)
img_records = [
x for x in img_records if
not np.array_equal(x['entity_box'], img_record['entity_box'])
]
assert len(img_records) + num_selected_records == num_img_records
bboxes.append(img_record['entity_box'])
valid_labels = np.array([
selected_record['label']
for selected_record in selected_records
])
# print("valid labels : ",valid_labels)
# The format can be directly used by BCELossWithLogits
label = np.zeros(self.num_classes, dtype=np.float32)
label[valid_labels] = 1.
labels.append(label)
entity_ids.append(img_record['entity_id'])
bboxes = np.stack(bboxes)
labels = np.stack(labels)
entity_ids = np.stack(entity_ids)
return bboxes, labels, entity_ids
def load_annotations(self):
"""Load Morai annotations."""
video_infos = []
records_dict_by_img = defaultdict(list)
with open(self.ann_file, 'r') as fin:
for line in fin:
line_split = line.strip().split(',')
video_id = line_split[0]
timestamp = int(line_split[1])
img_key = f'{video_id},{timestamp}'
entity_box = np.array(list(map(float, line_split[2:6])))
entity_id = int(line_split[7])
shot_info = (0, (self.timestamp_end - self.timestamp_start) *
self._FPS)
line = line_split[0].split('_')
label = line[0]
if label == 'right':
label=2
elif label =='left':
label=1
if self.custom_classes is not None:
if label not in self.custom_classes:
continue
label = self.custom_classes.index(label)
video_info = dict(
video_id=video_id,
timestamp=timestamp,
entity_box=entity_box,
label=label,
entity_id=entity_id,
shot_info=shot_info)
records_dict_by_img[img_key].append(video_info)
assert records_dict_by_img is not None
for img_key in records_dict_by_img:
video_id, timestamp = img_key.split(',')
bboxes, labels, entity_ids = self.parse_img_record(
records_dict_by_img[img_key])
ann = dict(
gt_bboxes=bboxes, gt_labels=labels, entity_ids=entity_ids)
frame_dir = video_id
if self.data_prefix is not None:
frame_dir = osp.join(self.data_prefix, frame_dir)
video_info = dict(
frame_dir=frame_dir,
video_id=video_id,
timestamp=int(timestamp),
img_key=img_key,
shot_info=shot_info,
fps=self._FPS,
ann=ann)
video_infos.append(video_info)
assert video_infos is not None
return video_infos
def prepare_train_frames(self, idx):
"""Prepare the frames for training given the index."""
results = copy.deepcopy(self.video_infos[idx])
img_key = results['img_key']
results['filename_tmpl'] = self.filename_tmpl
results['modality'] = self.modality
results['start_index'] = self.start_index
results['timestamp_start'] = self.timestamp_start
results['timestamp_end'] = self.timestamp_end
if self.proposals is not None:
if img_key not in self.proposals:
results['proposals'] = np.array([[0, 0, 1, 1]])
results['scores'] = np.array([1])
else:
proposals = self.proposals[img_key]
print("Proposal Shape : ",proposals.shape) # shape should be ({any_number},5), 5 means bbx and confidence
if proposals.shape==(0,):
proposals = np.array([[0,0,1,1,1]])
assert proposals.shape[-1] in [4, 5]
if proposals.shape[-1] == 5:
thr = min(self.car_det_score_thr, max(proposals[:, 4]))
positive_inds = (proposals[:, 4] >= thr)
proposals = proposals[positive_inds]
proposals = proposals[:self.num_max_proposals]
results['proposals'] = proposals[:, :4]
results['scores'] = proposals[:, 4]
else:
proposals = proposals[:self.num_max_proposals]
results['proposals'] = proposals
ann = results.pop('ann')
results['gt_bboxes'] = ann['gt_bboxes']
results['gt_labels'] = ann['gt_labels']
results['entity_ids'] = ann['entity_ids']
return self.pipeline(results)
def prepare_test_frames(self, idx):
"""Prepare the frames for testing given the index."""
results = copy.deepcopy(self.video_infos[idx])
img_key = results['img_key']
results['filename_tmpl'] = self.filename_tmpl
results['modality'] = self.modality
results['start_index'] = self.start_index
results['timestamp_start'] = self.timestamp_start
results['timestamp_end'] = self.timestamp_end
if self.proposals is not None:
if img_key not in self.proposals:
results['proposals'] = np.array([[0, 0, 1, 1]])
results['scores'] = np.array([1])
else:
proposals = self.proposals[img_key]
if proposals.shape==(0,):
proposals = np.array([[0,0,1,1]])
assert proposals.shape[-1] in [4, 5]
if proposals.shape[-1] == 5:
thr = min(self.car_det_score_thr, max(proposals[:, 4]))
positive_inds = (proposals[:, 4] >= thr)
proposals = proposals[positive_inds]
proposals = proposals[:self.num_max_proposals]
results['proposals'] = proposals[:, :4]
results['scores'] = proposals[:, 4]
else:
proposals = proposals[:self.num_max_proposals]
results['proposals'] = proposals
ann = results.pop('ann')
# Follow the mmdet variable naming style.
results['gt_bboxes'] = ann['gt_bboxes']
results['gt_labels'] = ann['gt_labels']
results['entity_ids'] = ann['entity_ids']
return self.pipeline(results)
def dump_results(self, results, out):
"""Dump predictions into a csv file."""
assert out.endswith('csv')
results2csv(self, results, out, self.custom_classes)
'''
def evaluate(self,
results,
metrics='top_k_accuracy',
topk=(1, 5),
logger=None):
pass
'''
def evaluate(self,
results,
metrics=('mAP', ),
metric_options=None,
logger=None):
"""Evaluate the prediction results and report mAP."""
assert len(metrics) == 1 and metrics[0] == 'mAP', (
'For evaluation on AVADataset, you need to use metrics "mAP" '
'See https://github.com/open-mmlab/mmaction2/pull/567 '
'for more info.')
time_now = datetime.now().strftime('%Y%m%d_%H%M%S')
temp_file = f'Morai_{time_now}_result.csv'
results2csv(self, results, temp_file, self.custom_classes)
ret = {}
for metric in metrics:
msg = f'Evaluating {metric} ...'
if logger is None:
msg = '\n' + msg
print_log(msg, logger=logger)
eval_result = ava_eval(
temp_file,
metric,
self.label_file,
self.ann_file,
self.exclude_file,
custom_classes=self.custom_classes)
log_msg = []
for k, v in eval_result.items():
log_msg.append(f'\n{k}\t{v: .4f}')
log_msg = ''.join(log_msg)
print_log(log_msg, logger=logger)
ret.update(eval_result)
os.remove(temp_file)
return ret
 Dai-Wenxun
Dai-Wenxun eliethesaiyan
eliethesaiyan
I made custom dataset(rawframes, videos) to detect car tail light. there is two videos and each one has 2,700 frames. FPS that I targeting is 30. So, my custom dataset and config file refer to spatio-temporal detection such as ava_dataset and slowfast_kinetics_pretrained_r50_4x16x1_20e_ava_rgb.py
And then, I generate annotations using ground truth bounding box and auto-annotation tools that I made. So, the folder structure is like below.
After annotations, create code for config and ${MMACTION2}/mmaction/dataset/my_dataset.py (I paste my config and dataset code.)
I run $python tools/train.py config/detect/custom/custom_config.py --validate
But, I face an error as like below.
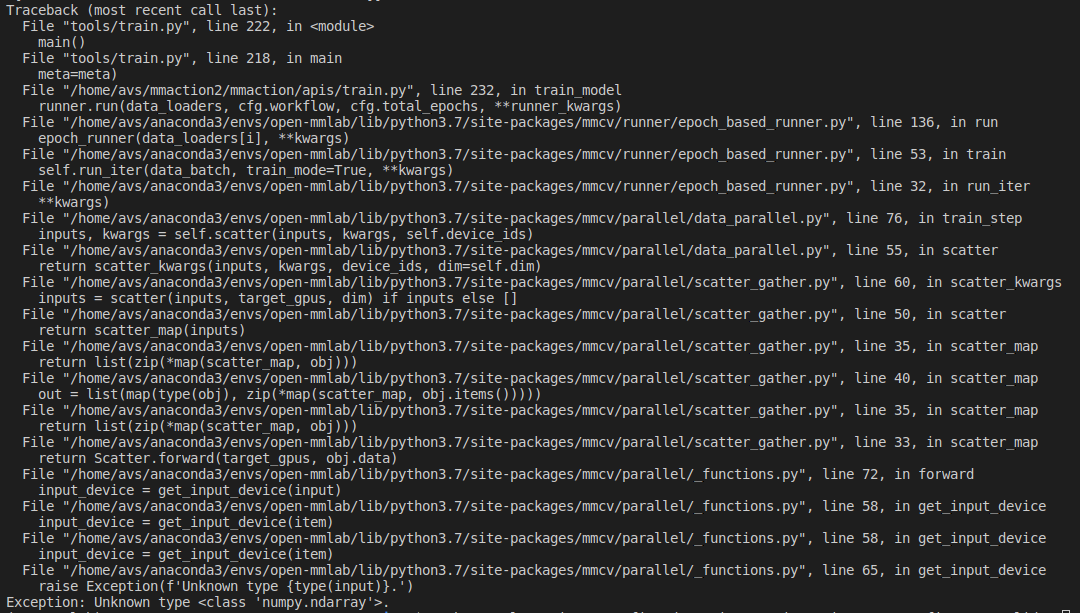
I also train AVAdataset to figure out what's the problem. the command was $python tools/train.py configs/detection/ava/slowfast_kinetics_pretrained_r50_4x16x1_20e_ava_rgb.py --validate
and add print command to check input value that I encounter the error.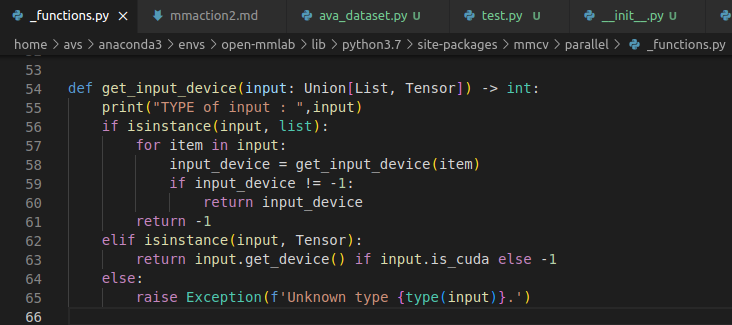
when training with AVA dataset, the input value has no change type value.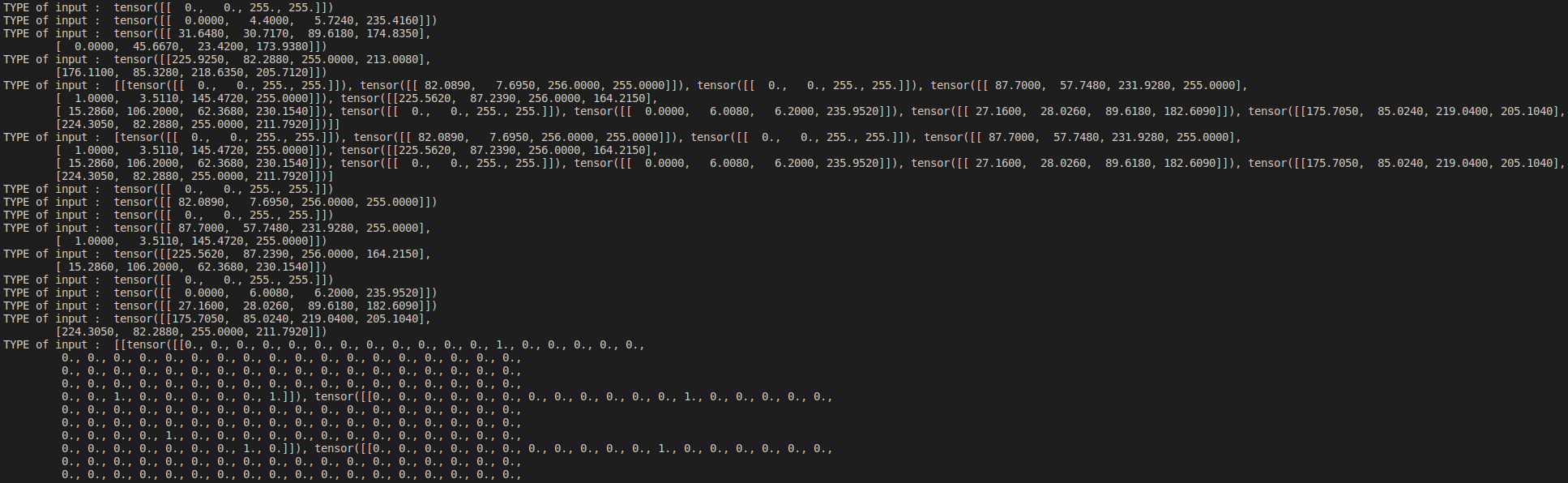
But, when training my custom dataset, the input value type turns into tensor to np.array suddenly
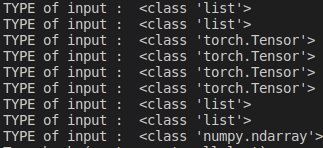
I want to know why is there sudden value type change, and thanks to read
codes
I have searched related issues and read the FAQ documentation but cannot get the expected help.