 Ezra-Yu
commented
2 years ago
Ezra-Yu
commented
2 years ago Yes. Thank you for your report. Can you fix that and create a PR?
Closed marouaneamz closed 2 years ago
Ezra-Yu
commented
2 years ago Yes. Thank you for your report. Can you fix that and create a PR?
 marouaneamz
commented
2 years ago
marouaneamz
commented
2 years ago yes of course
marouaneamz
commented
2 years ago @Ezra-Yu here is the PR : https://github.com/open-mmlab/mmclassification/pull/1143
Ezra-Yu
commented
2 years ago Good Job! I will test it.
marouaneamz
commented
2 years ago @Ezra-Yu did you test the inference after deployment? https://github.com/open-mmlab/mmclassification/pull/1143#issuecomment-1292230518
Ezra-Yu
commented
2 years ago @marouaneamz Sorry for later reply. (Since I have to download&install the docker, debug it when I test that)
Yes, I have tested it after deployment refer to this tutorial. And there are errors besides the one you mentioned here.
@Ezra-Yu In my understanding, the default _scope for the registry will be initialized in the runner. to use inference-mmcls in deploy servers it must be run with runners or hardcoded default_scope.
You are right, there is some error when testing. The PR https://github.com/open-mmlab/mmclassification/pull/1139 and https://github.com/open-mmlab/mmclassification/pull/1118 are going to solve this problem.
If you really want to run the example, you can modify the docker/serve/Dockerfile as flowing:
ARG PYTORCH="1.8.1"
ARG CUDA="10.2"
ARG CUDNN="7"
FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
# fetch the key refer to https://forums.developer.nvidia.com/t/18-04-cuda-docker-image-is-broken/212892/9
RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/3bf863cc.pub 32
RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/7fa2af80.pub
ARG MMENGINE="0.2.0"
ARG MMCV="2.0.0rc1"
ARG MMCLS="1.0.0rc2"
ENV PYTHONUNBUFFERED TRUE
RUN apt-get update && \
DEBIAN_FRONTEND=noninteractive apt-get install --no-install-recommends -y \
ca-certificates \
g++ \
openjdk-11-jre-headless \
# MMDet Requirements
ffmpeg libsm6 libxext6 git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 \
&& rm -rf /var/lib/apt/lists/*
ENV PATH="/opt/conda/bin:$PATH"
RUN export FORCE_CUDA=1
# TORCHSEVER
RUN pip install torchserve torch-model-archiver
RUn pip install nvgpu
# MMLAB
ARG PYTORCH
ARG CUDA
RUN pip install mmengine==${MMENGINE}
RUN ["/bin/bash", "-c", "pip install mmcv==${MMCV} -f https://download.openmmlab.com/mmcv/dist/cu${CUDA//./}/torch${PYTORCH}/index.html"]
RUN pip3 install git+https://github.com/mzr1996/mmclassification.git@1x-model-pages
# this branch has solved that
# RUN pip install mmcls==${MMCLS}
RUN useradd -m model-server \
&& mkdir -p /home/model-server/tmp
COPY entrypoint.sh /usr/local/bin/entrypoint.sh
RUN chmod +x /usr/local/bin/entrypoint.sh \
&& chown -R model-server /home/model-server
COPY config.properties /home/model-server/config.properties
RUN mkdir /home/model-server/model-store && chown -R model-server /home/model-server/model-store
EXPOSE 8080 8081 8082
USER model-server
WORKDIR /home/model-server
ENV TEMP=/home/model-server/tmp
ENTRYPOINT ["/usr/local/bin/entrypoint.sh"]
CMD ["serve"]In my env, it works fine as :
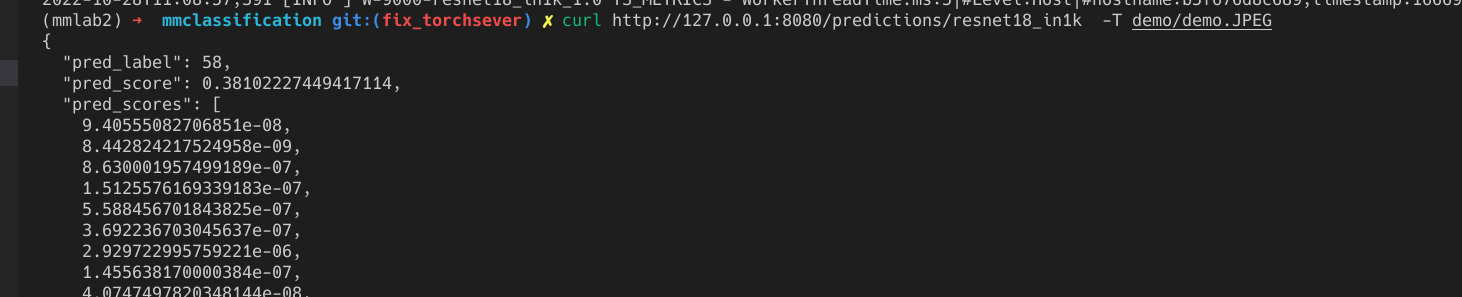
Ezra-Yu
commented
2 years ago We will fix it in branch 1.x in next version.
Ezra-Yu
commented
2 years ago fix it in #1143
Branch
1.x branch (1.0.0rc2 or other 1.x version)
Describe the bug
i think you forget to modify mmcv to mmengine here https://github.com/open-mmlab/mmclassification/blob/1.x/tools/deployment/mmcls2torchserve.py#L6
Environment
Other information
No response