 avaziri
commented
6 years ago
avaziri
commented
6 years ago ContinuousGoalOrientedMoveToPoint-v0 Environment
Env Summary:
The goal of this environment is to move the agent (a red dot) to touch the goal (a greev dot). The agent has momentum and will bounce off of walls if it touches one.
Gif of Environment
Please excuse the inconsistent frame rate, I was controlling the agent with a keyboard and did not hit the keys at a constant frequency.

Env Details
State Space: Positions in a unit square, velocities between -0.05 and +0.05. Goal Space: Any point in the unit square, re-sampled each episode Initial State Space: A point in the unit square, re-sampled each episode as well as a velocity within the velocity bounds re-sampled each episode Action Space: X force component, Y force component, between -1 and 1 Reward: 1 for reaching goal, 0 otherwise Terminal Condition: When the goal is achieved or when the time limit is reached (time limit comes from wrapper)
Source code
continuous_goal_oriented_particle.py.gz Make sure to register the environment with a time limit.
from gym.envs.registration import register
def register_move_to_point_env():
register(
id='ContinuousGoalOrientedMoveToPoint-v0',
entry_point='baselines.her.experiment.continuous_goal_oriented_particle:ContinuousGoalOrientedMoveToPoint',
max_episode_steps=250,
reward_threshold=1,)
 iSaran
iSaran filipolszewski
filipolszewski
System information
Describe the problem
I have not been able to get HER to converge on any environment other than the Mujoco environments. I have concerns about the robustness and reproducibility of the algorithm. Even with hyperparameter tuning HER fails to converge on all the simple environments I have tried.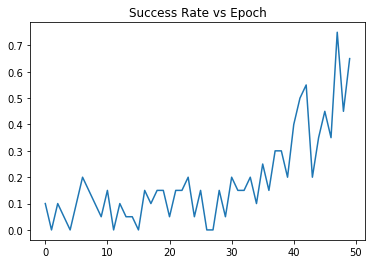 Here is a graph of test progress on the much more simple environment I made. I will give the source, and a description of the environment in a follow up post. It was run with command
Here is a graph of test progress on the much more simple environment I made. I will give the source, and a description of the environment in a follow up post. It was run with command 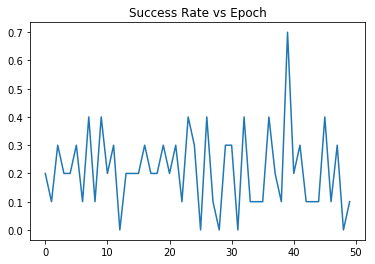 Result: Over 50 epochs it seems any learning is negligible. I am confident the environment is functioning properly. I have confirmed that DDPG can solve this environment very well with less than 20 epochs of training. I have also made a keyboard agent and played this environment myself; observing that everything works as expected.
Result: Over 50 epochs it seems any learning is negligible. I am confident the environment is functioning properly. I have confirmed that DDPG can solve this environment very well with less than 20 epochs of training. I have also made a keyboard agent and played this environment myself; observing that everything works as expected.
Here is a graph of test progress on FetchPush-v1 with command
python -m baselines.her.experiment.train --env_name=FetchPush-v1:python -m baselines.her.experiment.train --env_name ContinuousGoalOrientedMoveToPoint-v0:Hypothesis About Cause of Problem