 pzhokhov
commented
6 years ago
pzhokhov
commented
6 years ago I think the most important factor for speedup is ratio of compute time (simulator step time) to the communication time (time it takes to send observations and actions through the pipes); the larger this ratio - the better speedup one can achieve. The first thing I'd try is the same experiment using ShmemVecEnv, which eliminates some of the communication overhead by using shared arrays... Anything further will likely require a detailed analysis on where exactly is time being spent.
 zuoxingdong
zuoxingdong














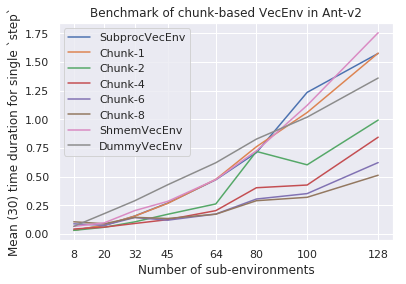



I made some toy benchmark by creating 16 environments for both
SubprocVecEnvandDummyVecEnv. And collect 1000 time steps by firstly reset the environment and feed random action sampled from action space within a for loop.It turns out the speed of the simulator step is quite crucial for total speedup. For example,
HalfCheetah-v2is roughly 1.5-2x faster and 'FetchPush-v1' could be 7-9x faster. I guess it depends on the dynamics where cheetah is simpler.For classic control environments like
CartPole-v1, it seems usingDummyVecEnvis much better, since the speedup is ~0.2x, i.e. 5x slower thanDummyVecEnv.I am considering that if it is feasible to scale up the speedup further to be approximately linear with the number of environments ? Or the main reason is coming from computing overhead in the
Process?