 akashe
commented
3 years ago
akashe
commented
3 years ago Hi, For SAC Log Prob:
From Appendix 3 of the paper, you can see we use tanh for squashing of action values, continuing from there:

For Q Loss (also with TD3): Summing the loss won't have any effect on the gradients to q1 and q2. It is just a trick to do loss.backward() once. For example: when we do loss_q.backward() in https://github.com/openai/spinningup/blob/master/spinup/algos/pytorch/sac/sac.py#L234 a gradient of [1] is sent back from loss_q. Since loss_q = loss_q1 + loss_q2, the dreivative of loss_q wrt loss_q1 is 1(same for loss_q2) and so the same gradients([1]) are passed down to loss_q1 and loss_q2 as they would have been passed with seperate loss_q1.backward() and loss_q2.backward()
SAC Log Prob: I am really confused about the log_prob equation used in the pytorch code: https://github.com/openai/spinningup/blob/master/spinup/algos/pytorch/sac/core.py#L60
I realize that the log_prob of the policy was derived in Appendix C, Eqtn. 21 as seen below: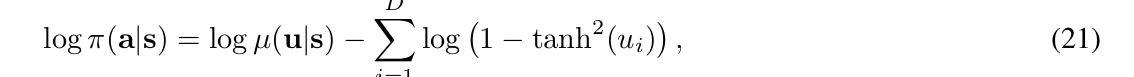
But I cannot see the connection to this line:
Q Loss (also with TD3): https://github.com/openai/spinningup/blob/master/spinup/algos/pytorch/sac/sac.py#L199
When computing the loss, we end up adding the loss for each I am not clear on the effect of adding the losses of the two functions and then subsequently doing backprop? Would it be better to backprop for each Q independently? Otherwise, we compute gradients that are larger than the error for each individual loss?