 jinyup100
commented
3 years ago
jinyup100
commented
3 years ago Currently at a stage where pytorch model of SiamRPN++ has been made and where conversion from pytorch to ONNX is made.
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import math
import os
import onnx
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
# Class for the Tracker - SiamRPNPP
class Tracker(nn.Module):
def __init__(self):
super(Tracker, self).__init__()
# build backbone
self.backbone = resnet50([2,3,4])
# build adjust layer
self.neck = AdjustAllLayer([512, 1024, 2048], [256, 256, 256])
# build rpn head
self.rpn_head = MultiRPN(anchor_num=5,in_channels=[256, 256, 256],weighted=True)
def template(self, z):
zf = self.backbone(z)
zf = self.neck(zf)
self.zf = zf
def track(self, x):
xf = self.backbone(x)
xf = self.neck(xf)
cls, loc = self.rpn_head(self.zf, xf)
return {'cls': cls,'loc': loc,}
def log_softmax(self, cls):
b, a2, h, w = cls.size()
cls = cls.view(b, 2, a2//2, h, w)
cls = cls.permute(0, 2, 3, 4, 1).contiguous()
cls = F.log_softmax(cls, dim=4)
return cls
def forward(self, data):
""" only used in training
"""
template = data['template']
search = data['search']
#label_cls = data['label_cls']
#label_loc = data['label_loc']
#label_loc_weight = data['label_loc_weight']
# get feature
zf = self.backbone(template)
xf = self.backbone(search)
zf = self.neck(zf)
xf = self.neck(xf)
cls, loc = self.rpn_head(zf, xf)
# get loss
#cls = self.log_softmax(cls)
#cls_loss = select_cross_entropy_loss(cls, label_cls)
#loc_loss = weight_l1_loss(loc, label_loc, label_loc_weight)
#outputs = {}
#outputs['total_loss'] = cfg.TRAIN.CLS_WEIGHT * cls_loss + \
#cfg.TRAIN.LOC_WEIGHT * loc_loss
#outputs['cls_loss'] = cls_loss
#outputs['loc_loss'] = loc_loss
return cls, loc
# End of Tracker - SiamRPNPP
# Class for the Building Blocks required for ResNet
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1,downsample=None, dilation=1):
super(BasicBlock, self).__init__()
padding = 2 - stride
if dilation > 1:
padding = dilation
dd = dilation
pad = padding
if downsample is not None and dilation > 1:
dd = dilation // 2
pad = dd
self.conv1 = nn.Conv2d(inplanes, planes,
stride=stride, dilation=dd, bias=False,
kernel_size=3, padding=pad)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes, dilation=dilation)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1,
downsample=None, dilation=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
padding = 2 - stride
if downsample is not None and dilation > 1:
dilation = dilation // 2
padding = dilation
assert stride == 1 or dilation == 1, \
"stride and dilation must have one equals to zero at least"
if dilation > 1:
padding = dilation
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=padding, bias=False, dilation=dilation)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
# End of Building Blocks
# Class for ResNet - the Backbone neural network
class ResNet(nn.Module):
def __init__(self, block, layers, used_layers):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=0, # 3
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.feature_size = 128 * block.expansion
self.used_layers = used_layers
layer3 = True if 3 in used_layers else False
layer4 = True if 4 in used_layers else False
if layer3:
self.layer3 = self._make_layer(block, 256, layers[2],
stride=1, dilation=2) # 15x15, 7x7
self.feature_size = (256 + 128) * block.expansion
else:
self.layer3 = lambda x: x # identity
if layer4:
self.layer4 = self._make_layer(block, 512, layers[3],
stride=1, dilation=4) # 7x7, 3x3
self.feature_size = 512 * block.expansion
else:
self.layer4 = lambda x: x # identity
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1, dilation=1):
downsample = None
dd = dilation
if stride != 1 or self.inplanes != planes * block.expansion:
if stride == 1 and dilation == 1:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
else:
if dilation > 1:
dd = dilation // 2
padding = dd
else:
dd = 1
padding = 0
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=3, stride=stride, bias=False,
padding=padding, dilation=dd),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride,
downsample, dilation=dilation))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, dilation=dilation))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x_ = self.relu(x)
x = self.maxpool(x_)
p1 = self.layer1(x)
p2 = self.layer2(p1)
p3 = self.layer3(p2)
p4 = self.layer4(p3)
out = [x_, p1, p2, p3, p4]
out = [out[i] for i in self.used_layers]
if len(out) == 1:
return out[0]
else:
return out
# End of ResNet
# Class for Adjusting the layers of the neural net
class AdjustLayer(nn.Module):
def __init__(self, in_channels, out_channels, center_size=7):
super(AdjustLayer, self).__init__()
self.downsample = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
)
self.center_size = center_size
def forward(self, x):
x = self.downsample(x)
if x.size(3) < 20:
l = (x.size(3) - self.center_size) // 2
r = l + self.center_size
x = x[:, :, l:r, l:r]
return x
class AdjustAllLayer(nn.Module):
def __init__(self, in_channels, out_channels, center_size=7):
super(AdjustAllLayer, self).__init__()
self.num = len(out_channels)
if self.num == 1:
self.downsample = AdjustLayer(in_channels[0],
out_channels[0],
center_size)
else:
for i in range(self.num):
self.add_module('downsample'+str(i+2),
AdjustLayer(in_channels[i],
out_channels[i],
center_size))
def forward(self, features):
if self.num == 1:
return self.downsample(features)
else:
out = []
for i in range(self.num):
adj_layer = getattr(self, 'downsample'+str(i+2))
out.append(adj_layer(features[i]))
return out
# End of Class for Adjusting the layers of the neural net
# Class for Region Proposal Neural Network
class RPN(nn.Module):
def __init__(self):
super(RPN, self).__init__()
def forward(self, z_f, x_f):
raise NotImplementedError
class DepthwiseXCorr(nn.Module):
def __init__(self, in_channels, hidden, out_channels, kernel_size=3, hidden_kernel_size=5):
super(DepthwiseXCorr, self).__init__()
self.conv_kernel = nn.Sequential(
nn.Conv2d(in_channels, hidden, kernel_size=kernel_size, bias=False),
nn.BatchNorm2d(hidden),
nn.ReLU(inplace=True),
)
self.conv_search = nn.Sequential(
nn.Conv2d(in_channels, hidden, kernel_size=kernel_size, bias=False),
nn.BatchNorm2d(hidden),
nn.ReLU(inplace=True),
)
self.head = nn.Sequential(
nn.Conv2d(hidden, hidden, kernel_size=1, bias=False),
nn.BatchNorm2d(hidden),
nn.ReLU(inplace=True),
nn.Conv2d(hidden, out_channels, kernel_size=1)
)
def forward(self, kernel, search):
kernel = self.conv_kernel(kernel)
search = self.conv_search(search)
feature = xcorr_depthwise(search, kernel)
out = self.head(feature)
return out
class DepthwiseRPN(RPN):
def __init__(self, anchor_num=5, in_channels=256, out_channels=256):
super(DepthwiseRPN, self).__init__()
self.cls = DepthwiseXCorr(in_channels, out_channels, 2 * anchor_num)
self.loc = DepthwiseXCorr(in_channels, out_channels, 4 * anchor_num)
def forward(self, z_f, x_f):
cls = self.cls(z_f, x_f)
loc = self.loc(z_f, x_f)
return cls, loc
class MultiRPN(RPN):
def __init__(self, anchor_num, in_channels, weighted=False):
super(MultiRPN, self).__init__()
self.weighted = weighted
for i in range(len(in_channels)):
self.add_module('rpn'+str(i+2),
DepthwiseRPN(anchor_num, in_channels[i], in_channels[i]))
if self.weighted:
self.cls_weight = nn.Parameter(torch.ones(len(in_channels)))
self.loc_weight = nn.Parameter(torch.ones(len(in_channels)))
def forward(self, z_fs, x_fs):
cls = []
loc = []
for idx, (z_f, x_f) in enumerate(zip(z_fs, x_fs), start=2):
rpn = getattr(self, 'rpn'+str(idx))
c, l = rpn(z_f, x_f)
cls.append(c)
loc.append(l)
if self.weighted:
cls_weight = F.softmax(self.cls_weight, 0)
loc_weight = F.softmax(self.loc_weight, 0)
def avg(lst):
return sum(lst) / len(lst)
def weighted_avg(lst, weight):
s = 0
for i in range(len(weight)):
s += lst[i] * weight[i]
return s
if self.weighted:
return weighted_avg(cls, cls_weight), weighted_avg(loc, loc_weight)
else:
return avg(cls), avg(loc)
# End of class for RPN
def conv3x3(in_planes, out_planes, stride=1, dilation=1):
"3x3 convolution with padding"
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, bias=False, dilation=dilation)
def xcorr_depthwise(x, kernel):
"""depthwise cross correlation
"""
batch = kernel.size(0)
channel = kernel.size(1)
x = x.view(1, batch*channel, x.size(2), x.size(3))
kernel = kernel.view(batch*channel, 1, kernel.size(2), kernel.size(3))
out = F.conv2d(x, kernel, groups=batch*channel)
out = out.view(batch, channel, out.size(2), out.size(3))
return out
def resnet18(used_layers):
"""Constructs a ResNet-18 model.
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], used_layers)
return model
def resnet50(used_layers):
"""Constructs a ResNet-50 model.
"""
model = ResNet(Bottleneck, [3, 4, 6, 3], used_layers)
return model
# Buiid Tracker
tracker_model = Tracker()
tracker_model.eval()
tracker_model.state_dict().keys()
model_dict = tracker_model.state_dict()
# Load pre-trained weights
# Pre-trained weights for siamrpn_r50_l234_dwxcorr is available from:
# https://drive.google.com/drive/folders/1Q4-1563iPwV6wSf_lBHDj5CPFiGSlEPG
# Other pre-trained weights is available from:
# https://github.com/STVIR/pysot/blob/master/MODEL_ZOO.md
current_path = os.getcwd()
load_path = os.path.join(current_path, "siamrpn_r50_l234_dwxcorr.pth")
pretrained_dict = torch.load(load_path,map_location=torch.device('cpu') )
#pretrained_dict = torch.load(load_path)
pretrained_dict.keys()
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
model_dict.update(pretrained_dict)
tracker_model.load_state_dict(model_dict)
# Dummy Input Variables
y = {}
y['template'] = Variable(torch.randn(1, 3, 126, 126), requires_grad=True)
y['search'] = Variable(torch.randn(1, 3, 224, 224), requires_grad=True)
torch_out = tracker_model(y)
# Export the torch tracker model to ONNX model
batch_size = 1
torch.onnx.export(tracker_model, y, "siamrpnpp.onnx", export_params=True, opset_version=10,
do_constant_folding=True, input_names = ['input'], output_names = ['output'],
dynamic_axes={'input' : {0 : 'batch_size'}, 'output' : {0 : 'batch_size'}})
# Load the saved tracker model using ONNX
onnx_model = onnx.load("siamrpnpp.onnx")
# Check whether the tracker model has been successfully imported
onnx.checker.check_model(onnx_model)
onnx.helper.printable_graph(onnx_model.graph)
 l-bat
l-bat bhack
bhack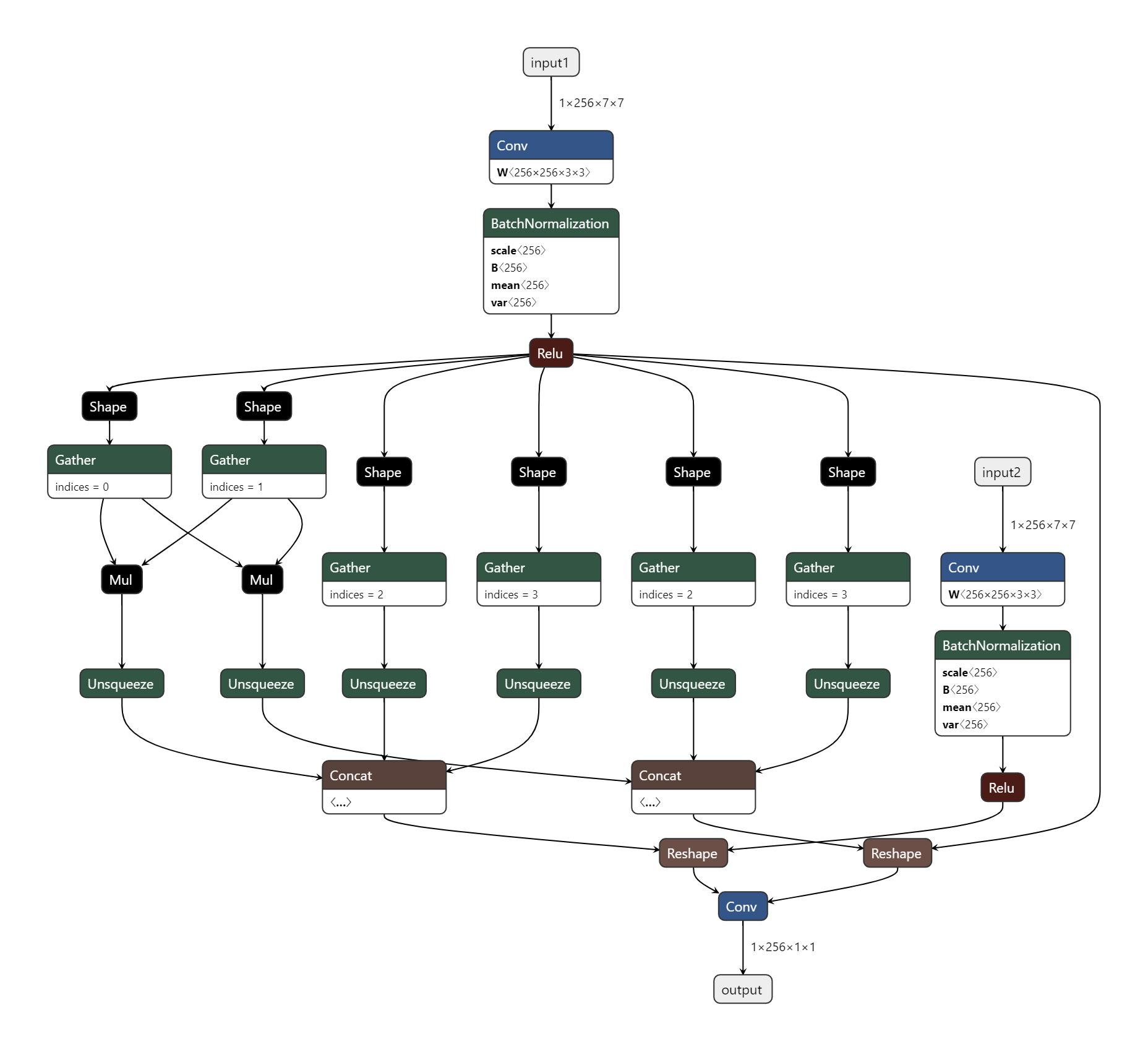
 ieliz
ieliz
 wenhaotang
wenhaotang
GSoC '20 : Real-time Single Object Tracking using Deep Learning (SiamRPN++)
Overview
Proposal : https://summerofcode.withgoogle.com/projects/#4979746967912448 Mentors : Liubov Batanina @l-bat, Stefano Fabri @bhack, Ilya Elizarov @ieliz Student : Jin Yeob Chung @jinyup100
Details of the Pull Request
Examples
Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
Code to generate ONNX Models
The code shown below to generate the ONNX models of siamrpn++ is also available from : https://gist.github.com/jinyup100/7aa748686c5e234ed6780154141b4685  The Final Version of the Pre-Trained Weights and successfully converted ONNX format of the models using the codes are available at:: **Pre-Trained Weights in pth Format** https://drive.google.com/file/d/11bwgPFVkps9AH2NOD1zBDdpF_tQghAB-/view?usp=sharing **Target Net** : Import :heavy_check_mark: Export :heavy_check_mark: https://drive.google.com/file/d/1dw_Ne3UMcCnFsaD6xkZepwE4GEpqq7U_/view?usp=sharing **Search Net** : Import :heavy_check_mark: Export :heavy_check_mark: https://drive.google.com/file/d/1Lt4oE43ZSucJvze3Y-Z87CVDreO-Afwl/view?usp=sharing **RPN_head** : Import : :heavy_check_mark: Export :heavy_check_mark: https://drive.google.com/file/d/1zT1yu12mtj3JQEkkfKFJWiZ71fJ-dQTi/view?usp=sharing ```python import numpy as np import onnx import torch import torch.nn as nn # Class for the Building Blocks required for ResNet class Bottleneck(nn.Module): expansion = 4 def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1): super(Bottleneck, self).__init__() self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False) self.bn1 = nn.BatchNorm2d(planes) padding = 2 - stride if downsample is not None and dilation > 1: dilation = dilation // 2 padding = dilation assert stride == 1 or dilation == 1, \ "stride and dilation must have one equals to zero at least" if dilation > 1: padding = dilation self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=padding, bias=False, dilation=dilation) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False) self.bn3 = nn.BatchNorm2d(planes * 4) self.relu = nn.ReLU(inplace=True) self.downsample = downsample self.stride = stride def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) if self.downsample is not None: residual = self.downsample(x) out += residual out = self.relu(out) return out # End of Building Blocks # Class for ResNet - the Backbone neural network class ResNet(nn.Module): "ResNET" def __init__(self, block, layers, used_layers): self.inplanes = 64 super(ResNet, self).__init__() self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=0, # 3 bias=False) self.bn1 = nn.BatchNorm2d(64) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.layer1 = self._make_layer(block, 64, layers[0]) self.layer2 = self._make_layer(block, 128, layers[1], stride=2) self.feature_size = 128 * block.expansion self.used_layers = used_layers layer3 = True if 3 in used_layers else False layer4 = True if 4 in used_layers else False if layer3: self.layer3 = self._make_layer(block, 256, layers[2], stride=1, dilation=2) # 15x15, 7x7 self.feature_size = (256 + 128) * block.expansion else: self.layer3 = lambda x: x # identity if layer4: self.layer4 = self._make_layer(block, 512, layers[3], stride=1, dilation=4) # 7x7, 3x3 self.feature_size = 512 * block.expansion else: self.layer4 = lambda x: x # identity for m in self.modules(): if isinstance(m, nn.Conv2d): n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels m.weight.data.normal_(0, np.sqrt(2. / n)) elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_() def _make_layer(self, block, planes, blocks, stride=1, dilation=1): downsample = None dd = dilation if stride != 1 or self.inplanes != planes * block.expansion: if stride == 1 and dilation == 1: downsample = nn.Sequential( nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(planes * block.expansion), ) else: if dilation > 1: dd = dilation // 2 padding = dd else: dd = 1 padding = 0 downsample = nn.Sequential( nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=3, stride=stride, bias=False, padding=padding, dilation=dd), nn.BatchNorm2d(planes * block.expansion), ) layers = [] layers.append(block(self.inplanes, planes, stride, downsample, dilation=dilation)) self.inplanes = planes * block.expansion for i in range(1, blocks): layers.append(block(self.inplanes, planes, dilation=dilation)) return nn.Sequential(*layers) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x_ = self.relu(x) x = self.maxpool(x_) p1 = self.layer1(x) p2 = self.layer2(p1) p3 = self.layer3(p2) p4 = self.layer4(p3) out = [x_, p1, p2, p3, p4] out = [out[i] for i in self.used_layers] if len(out) == 1: return out[0] else: return out # End of ResNet # Class for Adjusting the layers of the neural net class AdjustLayer_1(nn.Module): def __init__(self, in_channels, out_channels, center_size=7): super(AdjustLayer_1, self).__init__() self.downsample = nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False), nn.BatchNorm2d(out_channels), ) self.center_size = center_size def forward(self, x): x = self.downsample(x) l = 4 r = 11 x = x[:, :, l:r, l:r] return x class AdjustAllLayer_1(nn.Module): def __init__(self, in_channels, out_channels, center_size=7): super(AdjustAllLayer_1, self).__init__() self.num = len(out_channels) if self.num == 1: self.downsample = AdjustLayer_1(in_channels[0], out_channels[0], center_size) else: for i in range(self.num): self.add_module('downsample'+str(i+2), AdjustLayer_1(in_channels[i], out_channels[i], center_size)) def forward(self, features): if self.num == 1: return self.downsample(features) else: out = [] for i in range(self.num): adj_layer = getattr(self, 'downsample'+str(i+2)) out.append(adj_layer(features[i])) return out class AdjustLayer_2(nn.Module): def __init__(self, in_channels, out_channels, center_size=7): super(AdjustLayer_2, self).__init__() self.downsample = nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False), nn.BatchNorm2d(out_channels), ) self.center_size = center_size def forward(self, x): x = self.downsample(x) return x class AdjustAllLayer_2(nn.Module): def __init__(self, in_channels, out_channels, center_size=7): super(AdjustAllLayer_2, self).__init__() self.num = len(out_channels) if self.num == 1: self.downsample = AdjustLayer_2(in_channels[0], out_channels[0], center_size) else: for i in range(self.num): self.add_module('downsample'+str(i+2), AdjustLayer_2(in_channels[i], out_channels[i], center_size)) def forward(self, features): if self.num == 1: return self.downsample(features) else: out = [] for i in range(self.num): adj_layer = getattr(self, 'downsample'+str(i+2)) out.append(adj_layer(features[i])) return out # End of Class for Adjusting the layers of the neural net # Class for Region Proposal Neural Network class RPN(nn.Module): "Region Proposal Network" def __init__(self): super(RPN, self).__init__() def forward(self, z_f, x_f): raise NotImplementedError class DepthwiseXCorr(nn.Module): "Depthwise Correlation Layer" def __init__(self, in_channels, hidden, out_channels, kernel_size=3, hidden_kernel_size=5): super(DepthwiseXCorr, self).__init__() self.conv_kernel = nn.Sequential( nn.Conv2d(in_channels, hidden, kernel_size=kernel_size, bias=False), nn.BatchNorm2d(hidden), nn.ReLU(inplace=True), ) self.conv_search = nn.Sequential( nn.Conv2d(in_channels, hidden, kernel_size=kernel_size, bias=False), nn.BatchNorm2d(hidden), nn.ReLU(inplace=True), ) self.head = nn.Sequential( nn.Conv2d(hidden, hidden, kernel_size=1, bias=False), nn.BatchNorm2d(hidden), nn.ReLU(inplace=True), nn.Conv2d(hidden, out_channels, kernel_size=1) ) def forward(self, kernel, search): kernel = self.conv_kernel(kernel) search = self.conv_search(search) feature = xcorr_depthwise(search, kernel) out = self.head(feature) return out class DepthwiseRPN(RPN): def __init__(self, anchor_num=5, in_channels=256, out_channels=256): super(DepthwiseRPN, self).__init__() self.cls = DepthwiseXCorr(in_channels, out_channels, 2 * anchor_num) self.loc = DepthwiseXCorr(in_channels, out_channels, 4 * anchor_num) def forward(self, z_f, x_f): cls = self.cls(z_f, x_f) loc = self.loc(z_f, x_f) return cls, loc class MultiRPN(RPN): def __init__(self, anchor_num, in_channels): super(MultiRPN, self).__init__() for i in range(len(in_channels)): self.add_module('rpn'+str(i+2), DepthwiseRPN(anchor_num, in_channels[i], in_channels[i])) self.weight_cls = nn.Parameter(torch.Tensor([0.38156851768108546, 0.4364767608115956, 0.18195472150731892])) self.weight_loc = nn.Parameter(torch.Tensor([0.17644893463361863, 0.16564198028417967, 0.6579090850822015])) def forward(self, z_fs, x_fs): cls = [] loc = [] rpn2 = self.rpn2 z_f2 = z_fs[0] x_f2 = x_fs[0] c2,l2 = rpn2(z_f2, x_f2) cls.append(c2) loc.append(l2) rpn3 = self.rpn3 z_f3 = z_fs[1] x_f3 = x_fs[1] c3,l3 = rpn3(z_f3, x_f3) cls.append(c3) loc.append(l3) rpn4 = self.rpn4 z_f4 = z_fs[2] x_f4 = x_fs[2] c4,l4 = rpn4(z_f4, x_f4) cls.append(c4) loc.append(l4) def avg(lst): return sum(lst) / len(lst) def weighted_avg(lst, weight): s = 0 fixed_len = 3 for i in range(3): s += lst[i] * weight[i] return s return weighted_avg(cls, self.weight_cls), weighted_avg(loc, self.weight_loc) # End of class for RPN def conv3x3(in_planes, out_planes, stride=1, dilation=1): "3x3 convolution with padding" return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=dilation, bias=False, dilation=dilation) def xcorr_depthwise(x, kernel): """ Deptwise convolution for input and weights with different shapes """ batch = kernel.size(0) channel = kernel.size(1) x = x.view(1, batch*channel, x.size(2), x.size(3)) kernel = kernel.view(batch*channel, 1, kernel.size(2), kernel.size(3)) conv = nn.Conv2d(batch*channel, batch*channel, kernel_size=(kernel.size(2), kernel.size(3)), bias=False, groups=batch*channel) conv.weight = nn.Parameter(kernel) out = conv(x) out = out.view(batch, channel, out.size(2), out.size(3)) out = out.detach() return out class TargetNetBuilder(nn.Module): def __init__(self): super(TargetNetBuilder, self).__init__() # Build Backbone Model self.backbone = ResNet(Bottleneck, [3,4,6,3], [2,3,4]) # Build Neck Model self.neck = AdjustAllLayer_1([512,1024,2048], [256,256,256]) def forward(self, frame): features = self.backbone(frame) output = self.neck(features) return output class SearchNetBuilder(nn.Module): def __init__(self): super(SearchNetBuilder, self).__init__() # Build Backbone Model self.backbone = ResNet(Bottleneck, [3,4,6,3], [2,3,4]) # Build Neck Model self.neck = AdjustAllLayer_2([512,1024,2048], [256,256,256]) def forward(self, frame): features = self.backbone(frame) output = self.neck(features) return output class RPNBuilder(nn.Module): def __init__(self): super(RPNBuilder, self).__init__() # Build Adjusted Layer Builder self.rpn_head = MultiRPN(anchor_num=5,in_channels=[256, 256, 256]) def forward(self, zf, xf): # Get Feature cls, loc = self.rpn_head(zf, xf) return cls, loc """Load path should be the directory of the pre-trained siamrpn_r50_l234_dwxcorr.pth The download link to siamrpn_r50_l234_dwxcorr.pth is shown in the description""" current_path = os.getcwd() load_path = os.path.join(current_path, "siamrpn_r50_l234_dwxcorr.pth") pretrained_dict = torch.load(load_path,map_location=torch.device('cpu') ) pretrained_dict_backbone = pretrained_dict pretrained_dict_neck_1 = pretrained_dict pretrained_dict_neck_2 = pretrained_dict pretrained_dict_head = pretrained_dict pretrained_dict_target = pretrained_dict pretrained_dict_search = pretrained_dict # The shape of the inputs to the Target Network and the Search Network target = torch.Tensor(np.random.rand(1,3,127,127)) search = torch.Tensor(np.random.rand(1,3,125,125)) # Build the torch backbone model target_net = TargetNetBuilder() target_net.eval() target_net.state_dict().keys() target_net_dict = target_net.state_dict() # Load the pre-trained weight to the torch target net model pretrained_dict_target = {k: v for k, v in pretrained_dict_target.items() if k in target_net_dict} target_net_dict.update(pretrained_dict_target) target_net.load_state_dict(target_net_dict) # Export the torch target net model to ONNX model torch.onnx.export(target_net, torch.Tensor(target), "target_net.onnx", export_params=True, opset_version=11, do_constant_folding=True, input_names=['input'], output_names=['output_1,', 'output_2', 'output_3']) # Load the saved torch target net model using ONNX onnx_target = onnx.load("target_net.onnx") # Check whether the ONNX target net model has been successfully imported onnx.checker.check_model(onnx_target) print(onnx.checker.check_model(onnx_target)) onnx.helper.printable_graph(onnx_target.graph) print(onnx.helper.printable_graph(onnx_target.graph)) # Build the torch backbone model search_net = SearchNetBuilder() search_net.eval() search_net.state_dict().keys() search_net_dict = search_net.state_dict() # Load the pre-trained weight to the torch target net model pretrained_dict_search = {k: v for k, v in pretrained_dict_search.items() if k in search_net_dict} search_net_dict.update(pretrained_dict_search) search_net.load_state_dict(search_net_dict) # Export the torch target net model to ONNX model torch.onnx.export(search_net, torch.Tensor(search), "search_net.onnx", export_params=True, opset_version=11, do_constant_folding=True, input_names=['input'], output_names=['output_1,', 'output_2', 'output_3']) # Load the saved torch target net model using ONNX onnx_search = onnx.load("search_net.onnx") # Check whether the ONNX target net model has been successfully imported onnx.checker.check_model(onnx_search) print(onnx.checker.check_model(onnx_search)) onnx.helper.printable_graph(onnx_search.graph) print(onnx.helper.printable_graph(onnx_search.graph)) # Outputs from the Target Net and Search Net zfs_1, zfs_2, zfs_3 = target_net(torch.Tensor(target)) xfs_1, xfs_2, xfs_3 = search_net(torch.Tensor(search)) # Adjustments to the outputs from each of the neck models to match to input shape of the torch rpn_head model zfs = np.stack([zfs_1.detach().numpy(), zfs_2.detach().numpy(), zfs_3.detach().numpy()]) xfs = np.stack([xfs_1.detach().numpy(), xfs_2.detach().numpy(), xfs_3.detach().numpy()]) # Build the torch rpn_head model rpn_head = RPNBuilder() rpn_head.eval() rpn_head.state_dict().keys() rpn_head_dict = rpn_head.state_dict() # Load the pre-trained weights to the rpn_head model pretrained_dict_head = {k: v for k, v in pretrained_dict_head.items() if k in rpn_head_dict} pretrained_dict_head.keys() rpn_head_dict.update(pretrained_dict_head) rpn_head.load_state_dict(rpn_head_dict) rpn_head.eval() # Export the torch rpn_head model to ONNX model torch.onnx.export(rpn_head, (torch.Tensor(np.random.rand(*zfs.shape)), torch.Tensor(np.random.rand(*xfs.shape))), "rpn_head.onnx", export_params=True, opset_version=11, do_constant_folding=True, input_names = ['input_1', 'input_2'], output_names = ['output_1', 'output_2']) # Load the saved rpn_head model using ONNX onnx_rpn_head_model = onnx.load("rpn_head.onnx") # Check whether the rpn_head model has been successfully imported onnx.checker.check_model(onnx_rpn_head_model) print(onnx.checker.check_model(onnx_rpn_head_model)) onnx.helper.printable_graph(onnx_rpn_head_model.graph) print(onnx.helper.printable_graph(onnx_rpn_head_model.graph)) ```