 pvretano
commented
4 years ago
pvretano
commented
4 years ago @dr-shorthair no, this is not carried over from CSW-3. All content models are still on the table and DCAT-2 is a prominent discussion point. There is, however, a desire not to throw CSW-3 under the bus and try to follow the same pattern set by OAPIF -- that is that an "OGC API - Records" facade can be implemented on top of a CSW-3 catalogue just like a "OGC API - Features" facade can be implemented on top of a WFS 2.X. I should say that my own opinion is that the catalogue should be agnostic of the types or resources being catalogued (dataset, services, widgets, etc.) and should provide a uniform means to (a) provide at least a minimal description of a resource and how to get to it (b) relate the resource to other resources (in and outside the catalogue) and (c) classify the resource using any number of classification schemes. My feeling is that DCAT is very dataset and services focused ... am I wrong about that?
 dr-shorthair
dr-shorthair mhogeweg
mhogeweg cportele
cportele ghobona
ghobona
 uvoges
uvoges
 rob-metalinkage
rob-metalinkage lvdbrink
lvdbrink nmtoken
nmtoken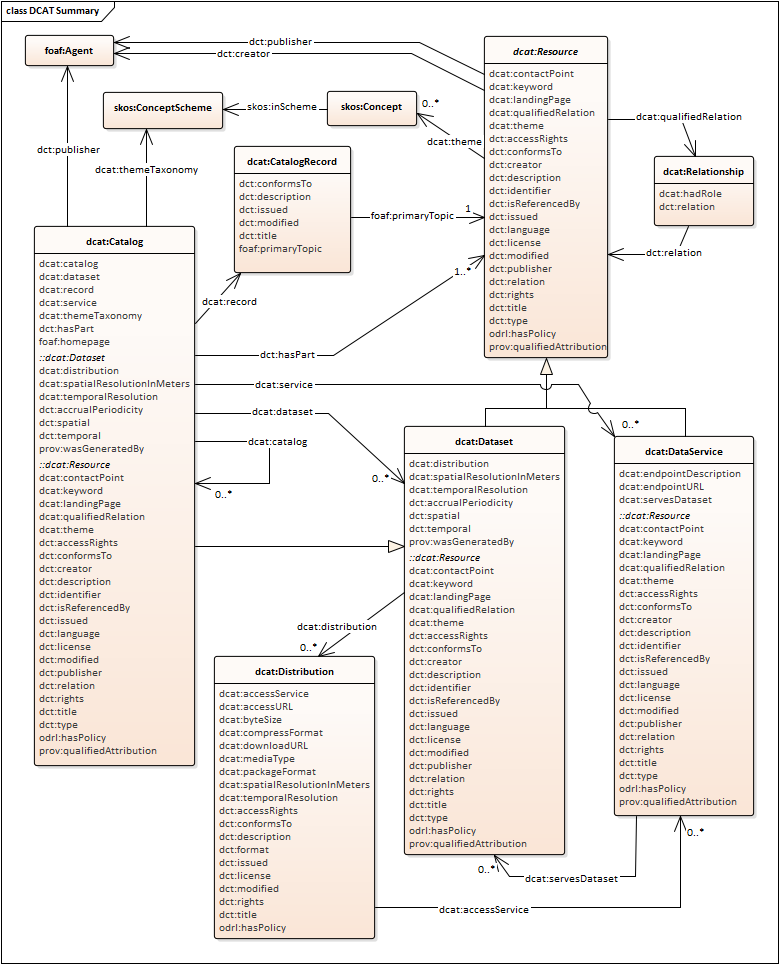{kind=link}
Is this carried over from CSW-3, or is a refresh under consideration - perhaps aligned with Schema.org or DCAT-2 ?