 Sam-Bolling
commented
1 year ago
Sam-Bolling
commented
1 year ago I am curious if this effort helps in resolving a limitation we ran into when implementing the SOS 2.0 specification. The most common military concept that matched "feature of interest" was/is "area of interest," but another concept was the "target of interest." Neither of these really synergized well with declaring the sensor ID as the feature of interest. So the profile practice of always using a sensor/monitoring station ID as the feature of interest didn't really work for us. However, we understood why communities would do this, because it offered a reasonably robust way to performed filtered queries to return lists of sensor IDs when the SOS 2.0 standard did not offer such an operation. Personally, I would advocate that an observation service should consider including operations focused on robust filtered queries and subscriptions that returned lists of sensor IDs (features that are sensors) but keep that concept separate from the feature of interest (features that are the focus of a sensor's observations) and maintain/improve the capabilities related to FoI discovery and access. Is there a conceptual conflict that precludes treating these as separate concepts altogether and building out the interface/API specifications to support them both well with use case -oriented operations?
 hylkevds
hylkevds humaidkidwai
humaidkidwai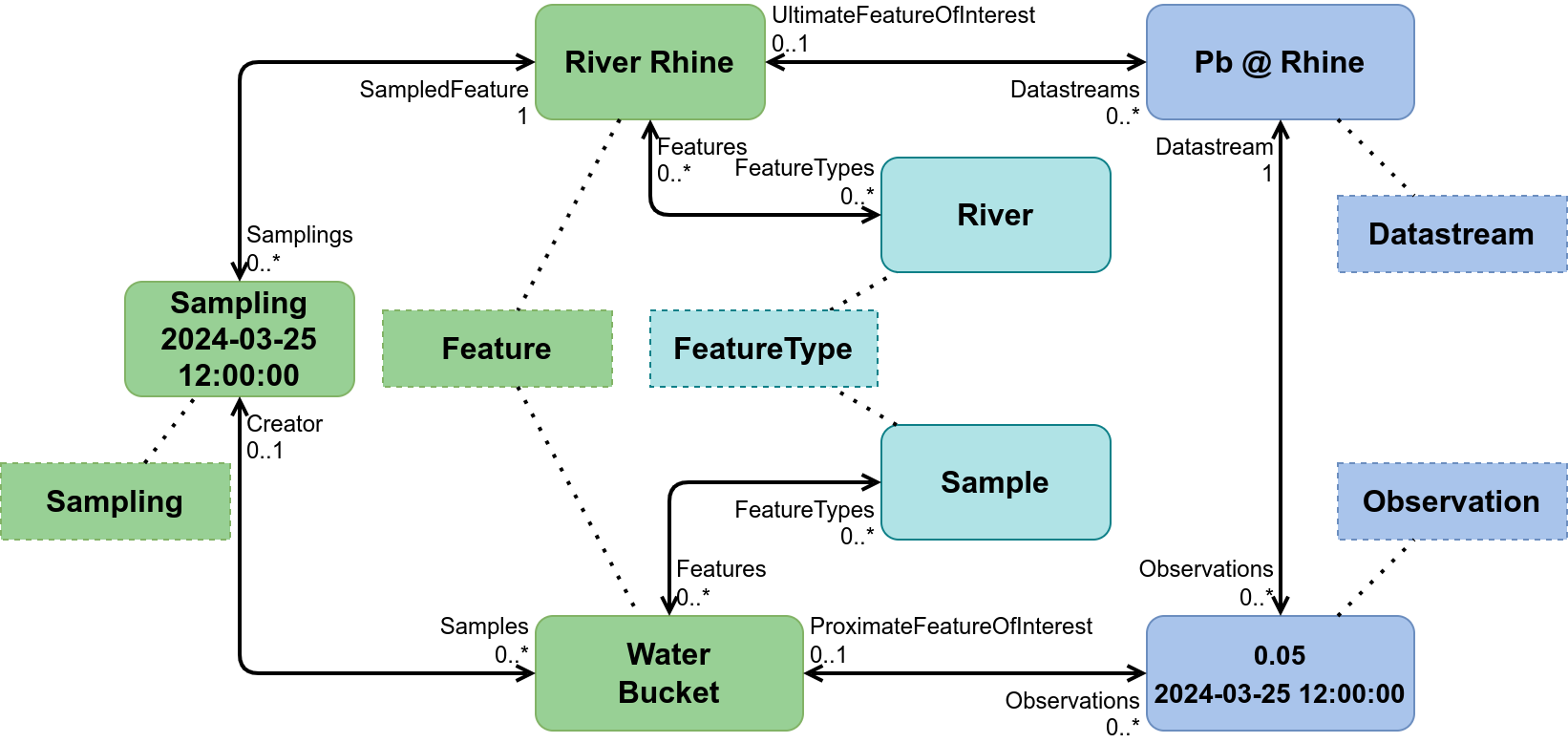
In OMS, we've differentiated FoI into proximate- and ultimateFeatureOfInterest. How do we implement this in STA?
Initial work has been done in the WQ IE, resulting in the following UML: https://raw.githubusercontent.com/hylkevds/FROST-Server.Plugin.WaterQualityIE/temp/Datamodel-SensorThingsApi-WaterQualityIE.drawio.png
The approach taken here takes into account that proximate vs. ultimate FoI is not a modification the FoI class itself, its just the role this Feature takes for the Observation. Thus: